






numpy统计
1.平均值和中位数
平均值
.mean()方法
axis=0 从上往下计算平均值 =1 从左往右

中位数
np.median()

标准差
np.std()
方差
np.var()
最大值和最小值
np.max() np.min()

求和 np.sum()

加权平均数

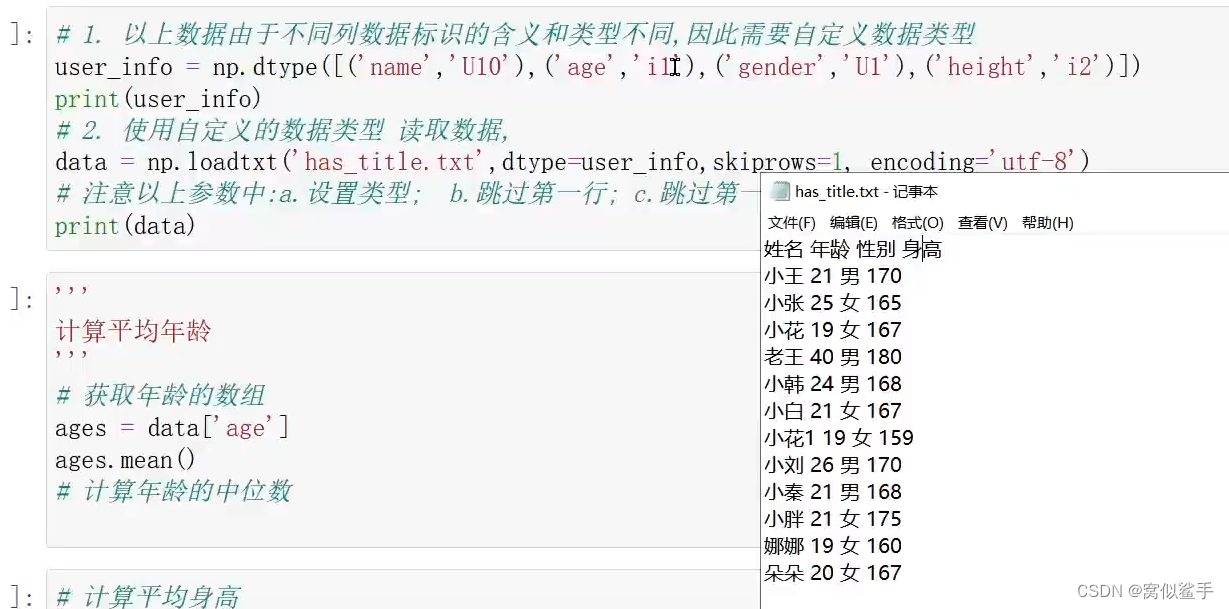
数据类型
自定义结构化数据类型
可以使每一列的数据类型不同,也可以用dtype=object 全部可以接受

自定义结构化数据类型 数据类型 长度 "i2" U Unicode定义了每个字符的编号和名称
t=np.dtype([("name","U10"),("gender","U1"),]) 可以用标识码也可以 np.str,3
#传入几个参数 usecols接受几个 要相对于应匹配 否则会报错
b=np.loadtxt("D:\python.txt",dtype=t,usecols=(0,2),encoding='utf-8',skiprows=1)
#usecols 取第几列数据
print(b)
文件操作
np.loadtxt()

不同类型数据的读取
 计算女生身高采用了布尔索引,把true的数据取出来
计算女生身高采用了布尔索引,把true的数据取出来
dtype:指定类型 skiprows:跳过多少行,假如有#号,行数也要加上 usecols:取哪几列数据
encoding='utf-8'

随机函数
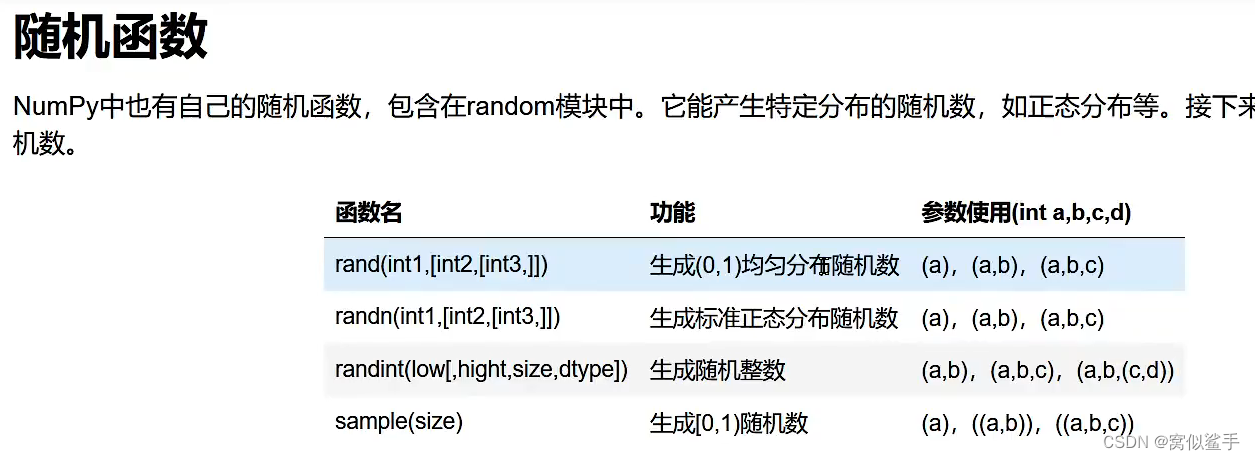
b=np.random.rand(2,3)#创建两行三列的均匀分布的数据
print(b)
c=np.random.randint(1,high=4,size=(2,2)) #1-4 不包括4
print(c)
结果:
[[0.27324425 0.7321929 0.26343662]
[0.20622495 0.72546426 0.62475389]]
[[3 3]
[1 1]]numpy.random.rand 范围0到1不包括1

数组其他函数

argwhere返回满足条件的索引
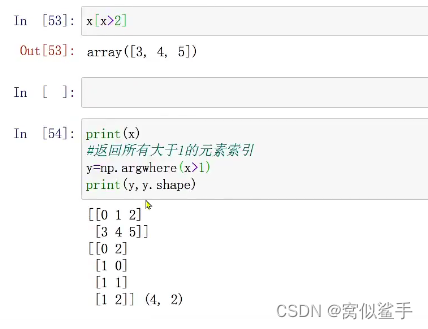
unique函数
numpy.unique(arr,return_index=true 返回去重后的索引数组,return_counts=true,重复个数)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









