







摘要: 大数据内容总结
关键词: 大数据、内容总结、案例举例
整体说明
大数据从方向分为 数据建模、数据平台、数据算法。从时效性分 实时大数据和离线大数据。从使用开发语言分 Java、Scala、SQL。常用平台分 Spark、Flink、Hadoop等。从各个方向分析下大数据包含哪些内容,具体图示如下:
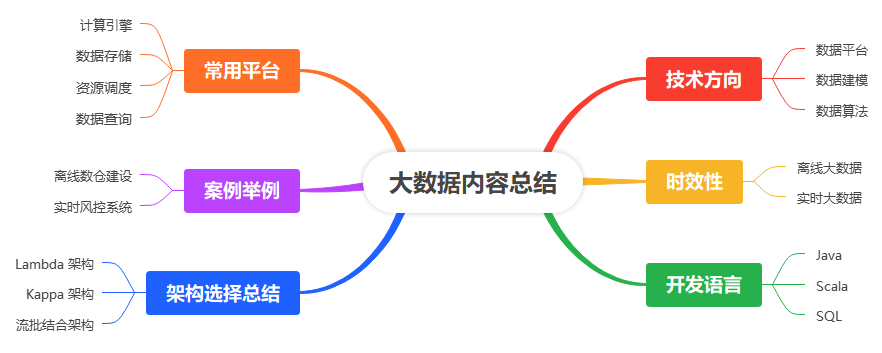
一、技术方向
1.1、 数据建模
1.1.1、类型分类
- 数据仓库建模:星型模型、雪花模型、宽表设计
- 维度建模:事实表、维度表、缓慢变化维(SCD)
- 实体关系模型(ER模型):用于传统关系型数据库设计
- 数据治理:元数据管理、数据血缘、数据质量校验
1.1.2、职业前景
- 职业侧重:这个技术方向主要是侧重数据开发,大部分是之前传统数仓转过来的,也就是大家调笑的SqlBoy。
- 职业优劣:这个方向确实在技术开发能力上相对薄弱,但是也有自己的优势,那就是更加侧重于解决方案,
经验积累方面需要更多。 - 职业方向:更加的重视理论知识和模型的设计,同时也和业务更贴近,更容易成为业务专家。
1.2. 数据平台
1.2.1、类型分类
- 数据采集:工具如Flume、Kafka、Sqoop
- 数据存储:HDFS、HBase、对象存储(如S3)
- 数据处理:ETL工具(如Apache Nifi)、分布式计算框架(如Spark、Flink)
- 数据分析:BI工具(如Tableau)、OLAP引擎(如Doris、ClickHouse)
1.2.2、职业前景
- 职业侧重: 这个技术方向主要是侧重平台开发,大部分是以前的Java开发,对工具进行二次开发,然后做数据的处理。
- 职业优劣:就是有数据思维的Java开发,开发能力强。
- 职业方向:大数据架构师。
1.3. 数据算法
1.3.1、类型分类
- 机器学习:分类、聚类、推荐算法(如协同过滤)
- 统计分析:假设检验、回归分析、时序预测
- 数据挖掘:关联规则(Apriori)、异常检测(Isolation Forest)
- 图计算:PageRank、社区发现(如Spark GraphX)
1.3.2、职业前景
- 职业侧重:这个技术方向主要侧重于数据分析和数据挖掘,也就是算法工程师这种,
- 职业优劣:相对比较吃香,但是随着越来越卷, 对学历的要求也越来越高。
- 职业方向:最终是以数据科学家为目标,但是又有几个科学家呢。
二、时效性
2.1、实时大数据
- 流处理框架:Flink、Storm、Kafka Streams
- 应用场景:实时监控(如风控)、实时推荐、IoT数据处理
- 技术特征:低延迟(毫秒级)、事件时间处理(Event Time)
2.2、 离线大数据
- 批处理框架:Hadoop MapReduce、Spark(批模式)
- 应用场景:T+1报表、历史数据分析、数据仓库构建
- 技术特征:高吞吐量、资源利用率优化
三、开发语言
3.1、Java
- 应用场景:Hadoop生态(HDFS、MapReduce)、Flink(部分API)
- 工具支持:HBase、Elasticsearch的Java客户端
3.2、 Scala
- 核心框架:Spark(原生语言)、Flink(API兼容)
- 优势:函数式编程、与JVM生态无缝集成
3.3、 SQL
- 场景:Hive、Spark SQL、Flink SQL
- 扩展语法:窗口函数(如OVER子句)、UDF开发
四、常用平台
4.1、 计算引擎
- Spark:内存计算、支持批流一体(Structured Streaming)
- Flink:低延迟流处理、Exactly-Once语义
- Hadoop:HDFS(存储)+ MapReduce(计算)
4.2、 存储与查询
- Hive:基于HDFS的数据仓库,支持SQL查询
- HBase:分布式列式存储,适用于随机读写
- Kafka:高吞吐消息队列,支持流式数据缓冲
4.3、资源调度
- YARN:Hadoop生态的资源管理器
- Kubernetes:容器化部署(如Flink on K8s)
五、案例举例
5.1、实时风控系统
- 技术栈:Flink(实时计算)+ Kafka(数据流)+ Redis(特征缓存)
- 流程:用户行为数据→实时特征计算→规则引擎→风险拦截
5.2、离线数仓建设
- 技术栈:Hive(数据分层)+ Spark(ETL)+ Airflow(调度)
- 流程:原始数据→ODS→DWD→DWS→ADS→BI报表
六、架构选择总结
大数据技术体系需要根据业务需求选择合适的技术组合,以实时数仓选型,举例如下
6.1、Lambda 架构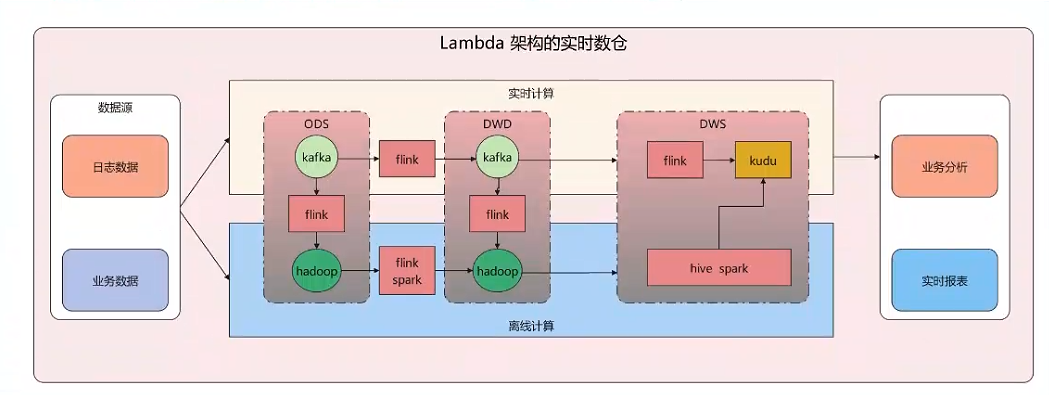
6.2、Kappa 架构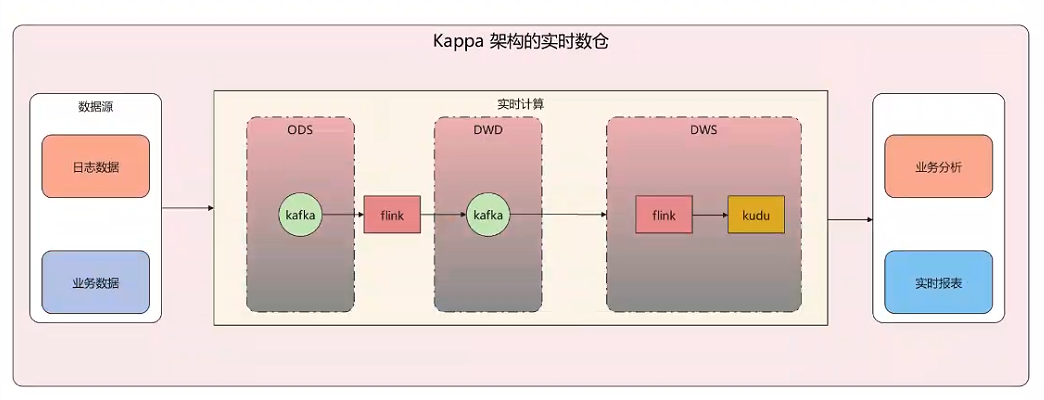
6.3、流批结合架构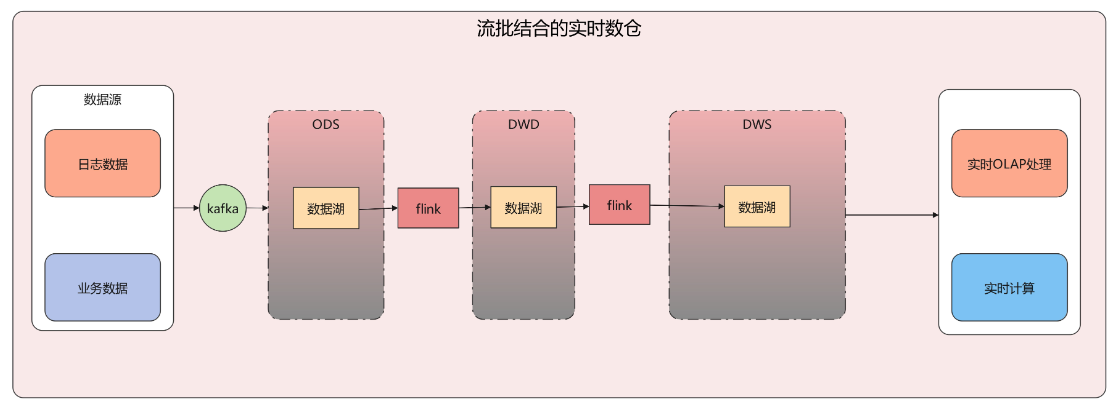
实际应用中,还需关注数据安全、成本优化(如计算资源调度)和可观测性(如日志监控)。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











