







摘要: SparkSQL大增量表取最新组织关系
关键词: 大数据、SparkSQL优化、性能优化、HINTS
一、背景
- 背景:一张巨大的增量日志表需要获取最新的用户组织关系;
- 技术应用场景:日志统计,历史用户关系统计;
- 整体思路:把每次全量转换为增量,把大表和大表关联,转换为大表和小表关联,利用SparkSQL特性优化查询速度。
二、解决过程
2.1、优化前的准备工作
1)、准备表
a.增量日志表 时间分区为2016-01-01至今,每日增量分区,分区字段pdate,总分区数据量约200亿条。
create table t_log
( id String COMMENT '唯一id',
user_id String COMMENT '用户id',
active_time String COMMENT '活动时间,精确到具体时分秒',
) PARTITIONED BY (pdate string)
STORED AS PARQUET
b.用户拉链表 单分区数据量约2亿条。
create table t_user_h
( school_id String COMMENT '学校id',
user_id String COMMENT '用户id',
start_date String COMMENT '开始日期',
end_date String COMMENT '结束日期'
) PARTITIONED BY (pdate string)
STORED AS PARQUET
2)、优化预期
- 优化前 两张表直接关联,关联代码如下
select
t1.id,
t1.user_id,
t1.active_time,
t2.school_id
from t_log t1
join t_user_h t2
on t1.active_time >= t2.start_date
and t1.active_time <= t2.end_date
and t1.user_id = t2.user_id
where t2.pdate = current_date
关联时间: 5小时/每日 关联扫描用户数: 200万/每日
- 优化后 挑出不变的用户,只对变化做关联 关联时间: 0.5小时/每日 关联扫描用户数: 2万/每日
2.2、进入优化阶段
1)、优化方案说明
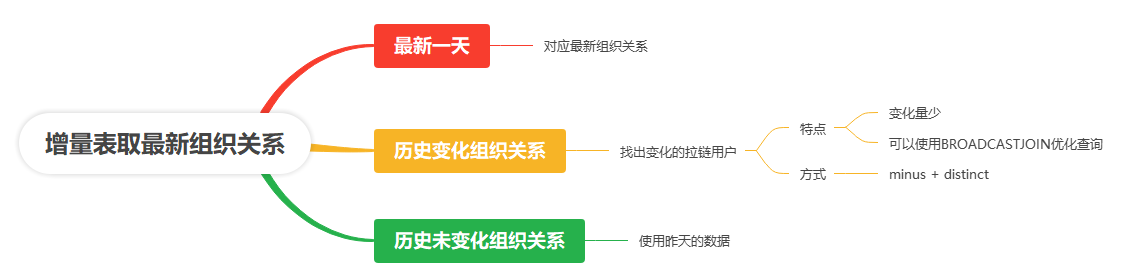
2)、SparkSQL关联基础知识
1、关联方式基础知识
a、 broadcast join(小表对大表)
将小表的数据分发到每个节点上,供大表使用。executor
存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQL中称作Broadcast Join Broadcast Join的条件有以下几个:
- 被广播的表需要小于 spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是10M (或者加了broadcast join的hint)
- 基表不能被广播,比如 left outer join 时,只能广播右表
b、 Shuffle Hash Join
分为两步:
- 对两张表分别按照join keys进行重分区,即shuffle,目的是为了让有相同join keys值的记录分到对应的分区中
- 对对应分区中的数据进行join,此处先将小表分区构造为一张hash表,然后根据大表分区中记录的join keys值拿出来进行匹配
c、 Sort Merge Join(大表对大表)
将两张表按照join keys进行了重新shuffle,保证join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接,
因为两个序列都是有序的,从头遍历,碰到key相同的就输出;如果不同,左边小就继续取左边,反之取右边。
2、explain的基础知识
explain + select 语句
执行即可查看 这个段查询的 执行计划,即 查询会按照什么样的方式执行
3、hints的基础知识
可以通过在SparkSQL中增加hints 格式:
/*+ HINT_NAME */
举例: 强制SparkSQL 使用BROADCASTJOIN方式, 为小表的别名
/*+ BROADCASTJOIN(B) */
3)、优化步骤
第一步:对新增的一天的数据直接关联历史拉链表
create temporary view temp_result_part1 as
select
t1.id,
t1.user_id,
t1.active_time,
t2.school_id
from t_log t1
join t_user_h t2
on t1.active_time >= t2.start_date
and t1.active_time <= t2.end_date
and t1.user_id = t2.user_id
and t1.pdate = t2.pdate
where t2.pdate = current_date
第二步:找出变化的拉链用户, 拉链的变化包含新增、更新、删除
create temporary view temp_user_h_change as
create
select
user_id,
start_date,
end_date
from t_user_h
where pdate = current_date
minus
select
user_id,
start_date,
end_date
from t_user_h
where pdate = date_sub(current_date,1)
第三步:根据变化的用户去减少t_log的数据量,同时使用spark中的broadcastjoin来加快关联,一天变化用户约2万个
create temporary view temp_log as
select
/*+ BROADCASTJOIN(t1,t2) */
t1.id,
t1.user_id,
t1.active_time
from t_log t1
join (select distinct user_id from temp_user_h_change) t2
on t1.user_id = t2.user_id
where t1.pdate <= date_sub(current_date,1)
第四步:把变化的这部分日志记录关联最新的组织关系
create temporary view temp_result_part2 as
select
t1.id,
t1.user_id,
t1.active_time,
t2.school_id
from temp_log t1
join t_user_h t2
on t1.active_time >= t2.start_date
and t1.active_time <= t2.end_date
and t1.user_id = t2.user_id
where t2.pdate = current_date
第五步:针对那些没有变化组织关系的用户,直接使用昨天的数据t_result, 至于昨天的数据怎么生成, 可以采用全量关联的方式,生成一个初始化数据,这里个过程很耗时,但是只要一次就可以了。
insert overwrite table t_result
select
t1.id,
t1.user_id,
t1.active_time,
t2.school_id
from t_log t1
join t_user_h t2
on t1.active_time >= t2.start_date
and t1.active_time <= t2.end_date
and t1.user_id = t2.user_id
where t2.pdate = date_sub(current_date,1)
and t1.pdate <= date_sub(current_date,1)
把昨天的数据放入临时表
create temporary view temp_result_yesteday as
select
id,
user_id,
active_time,
school_id
from t_result
去除昨天的数据中已经是组织关系变化的用户,只保留没有变化的用户
create temporary view temp_result_part3 as
select
id,
user_id,
active_time,
school_id
from temp_result_yesteday
left join (select distinct user_id from temp_user_h_change) t2
on t1.user_id = t2.user_id
where t2.user_id is null
第六步就是把这三部分合在一起,就是我们想要的结果
insert overwrite table t_result
select
id,
user_id,
active_time,
school_id
from temp_result_part1
union all
select
id,
user_id,
active_time,
school_id
from temp_result_part2
union all
select
id,
user_id,
active_time,
school_id
from temp_result_part3
三、总结
由于变化的用户只有2万左右的数据比原来所有的用户200万下降了100倍,所以数据关联消耗资源大大减少。 同时计算时间也从5小时下降到1小时, 扫描大的日志数据表的计算时间还是没法避免。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











