







摘要: Hive自定义函数简介及实践
关键词: 大数据、Hive、自定义函数
整体说明
从自定义函数的简介,到自定义函数的使用类型分类和使用周期分类,以及每种自定义函数的实践案例,解决具体的需求,简单图示如下:
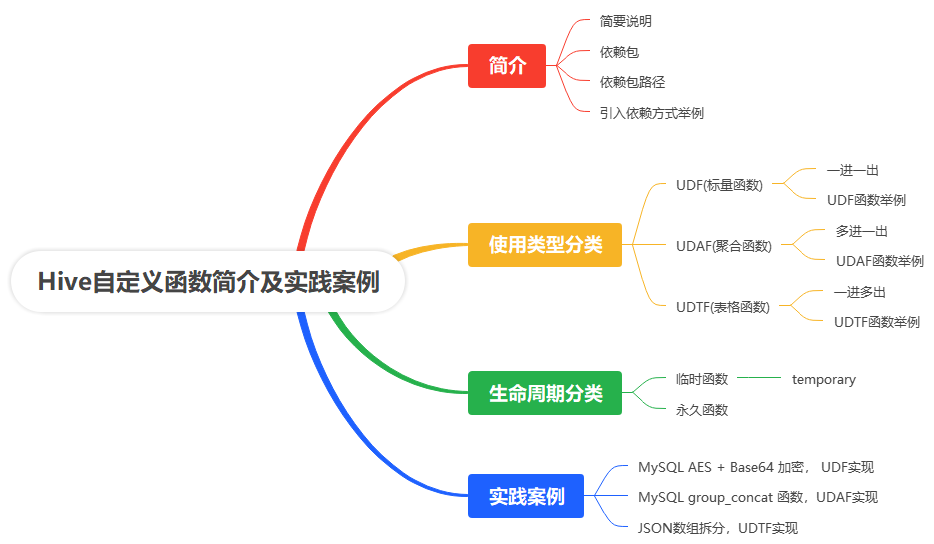
一、简介
允许用户扩展 Hive 的功能,以实现特定的数据处理需求。
通过编写自定义函数,你可以添加新的聚合逻辑、转换操作或数据格式化等功能。
所有内置函数都是通过自定义函数的形式编写的,所以编写UDF时,可以参照Hive的源码。
- 依赖包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
- 依赖包路径
org.apache.hadoop.hive.ql.udf.generic
- 引入依赖方式举例
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFCovariance;
二、使用类型分类
2.1、UDF(标量函数)
-
定义: 用户自定义标量函数 (User-Defined Function),用于处理单个数据项并返回单个结果的函数类型,即一进一出。例如,将一个字符串转为大写字母。
-
UDF函数举例:
CONCAT:连接多个字符串。
UPPER:将字符串转为大写字母。
LOWER:将字符串转为小写字母。
TRIM:删除字符串中的空格。
SUBSTR:截取字符串的一部分。
2.2、UDAF(聚合函数)
-
定义: 用户自定义聚合函数 (User-Defined Aggregation Function),用于处理多个数据项并返回单个结果的函数类型,即多进一出。例如,计算一个列的平均值。
-
UDAF函数举例:
AVG:计算一个数值列的平均值。
SUM:计算一个数值列的总和。
MAX:计算一个数值列的最大值。
MIN:计算一个数值列的最小值。
COUNT:计算一个数值列的行数。
2.3、UDTF(表格函数)
-
定义: 用户自定义表格函数 (User-Defined Table Function),用于将一个输入转为多个输出的函数类型,即一进多出(如 lateral view explode())。例如,将一行数据拆分成多个单词。
-
UDTF函数举例:
EXPLODE:将一个数组或者一个 Map 类型的列拆分成多行。
LATERAL VIEW:将一个表格函数应用到一个查询中的每一行,产生多个输出行。
PARSE_URL:解析 URL 中的各个部分。
JSON_TUPLE:解析 JSON 格式的数据。
三、生命周期分类
-
临时函数: 加了 temporary 关键字的是临时函数,当退出系统时,这个函数也将消失,如果想要调用,需要登录后重新创建。而且临时 UDF 函数可以在任意库中调用,不受库限制。
-
永久函数: 不加 temporary 关键字的是永久函数,永久性的 UDF 函数会一直存在,不会因为退出系统而消失。但其他库想要调用永久性 UDF 函数需要在函数名前加上库名。
四、实践案例
4.1、MySQL AES + Base64 加密, UDF实现
4.1.1、需求背景
由于通过 iflydata 资产平台-数据服务 (这个模块是把 SQL 转换成 RestFul接口) 连接 MySQL 把敏感数据加密提供出去,使用了 MySQL 内部的加密方式。
后来由于引入了 Doris 数据库,去做这个数据加密共享出去的事,为了保持加密方式一致,所以需要 UDF (Doris UDF 可以直接使用 Hive UDF, 这里就演示注册到 Hive的效果)。
4.1.2、UDF 实现
- 实现JavaUtil
package com.bigdata.util;
import org.apache.commons.codec.binary.Base64;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
/**
* @author jpquan2
* @Description 字段加密,Mysql的加密方式,增加给Doris数据库使用
* @since 2024/10/30
*/
public class AesBase64EncryMysqlUtil {
public AesBase64EncryMysqlUtil() {
}
public static String encrptBase64(String data, String key) throws Exception {
final Cipher encryptCipher = Cipher.getInstance("AES");
encryptCipher.init(Cipher.ENCRYPT_MODE, generateMySQLAESKey(key, StandardCharsets.UTF_8));
byte[] encryptedBytes = encryptCipher.doFinal(data.getBytes());
return Base64.encodeBase64String(encryptedBytes);
}
/**
* 生成AES加解密用的SecretKeySpec
*
* @param key 加解密用的秘钥
* @param charset 编码设置 默认UTF-8
* @return SecretKeySpec实例
*/
public static SecretKeySpec generateMySQLAESKey(String key, Charset charset) {
try {
final byte[] finalKey = new byte[16];
int i = 0;
for (byte b : key.getBytes(charset)) {
finalKey[i++ % 16] ^= b;
}
//System.out.println(new String(finalKey));
return new SecretKeySpec(finalKey, "AES");
} catch (Exception e) {
return null;
}
}
}
- 注册 UDF
package com.bigdata.udf;
import com.bigdata.util.AesBase64EncryMysqlUtil;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @Author jpquan2
* @Date 2024/10/30
* 字段加密,Mysql的加密方式,增加给Doris数据库使用
*/
public class UDFAesBase64EncryMysql extends UDF {
public String evaluate(String column, String key) throws Exception{
return AesBase64EncryMysqlUtil.encrptBase64(column, key);
}
}
4.1.3、UDF 注册到 Hive
- 打包: 首选需要打包 UDF 包,比如 bigdata-udf-1.0-SNAPSHOT.jar
- 上传文件: 然后放到对应的HDFS路径,比如 hdfs://bigdataedu///project/shscnq/udf/
create temporary function UDFAesBase64EncryMysql as 'com.bigdata.udf.UDFAesBase64EncryMysql'
using jar 'hdfs://bigdataedu///project/shscnq/udf/bigdata-udf-1.0-SNAPSHOT.jar';
4.1.4、UDF 实现效果
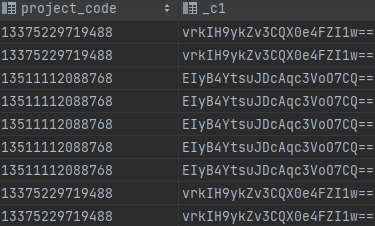
- 查询 SQL
select
project_code,
UDFAesBase64EncryMysql(project_code,'test')
from demo_data
limit 10;
- 查询结果
4.2、MySQL group_concat 函数,UDAF实现
4.2.1、需求背景
习惯了 MySQL 的语法,觉得 group_concat 这个函数真的很好用,但是 Hive 里又没有,抱着学习自定义函数的心态,自己写了一个,后续需要的话可以参照此写法。(官方建议大数据量的情况下,还是使用 Hive 内置的 collect_list 或 collect_set 结合 concat_ws 函数,因为它们更加高效且易于维护)。
4.2.2、UDAF 实现
package com.bigdata.udaf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableConstantStringObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.Text;
@Description(name = "group_concat", value = "_FUNC_(x, delimiter) - Returns the input strings concatenated into a single string with a specified delimiter")
public class UDAFGroupConcat extends AbstractGenericUDAFResolver {
private static final String DEFAULT_DELIMITER = ",";
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException {
if (parameters.length != 1 && parameters.length != 2) {
throw new UDFArgumentException("One or two arguments are expected: a string and an optional delimiter.");
}
return new GroupConcatEvaluator();
}
public static class GroupConcatEvaluator extends GenericUDAFEvaluator {
private Text result;
private String separator;
private transient ObjectInspector[] argumentOIs;
@Override
public ObjectInspector init(Mode mode, ObjectInspector[] parameters) throws HiveException {
super.init(mode, parameters);
result = new Text();
separator = DEFAULT_DELIMITER; // Default delimiter is comma
if (parameters.length == 2) { //判断参数是否为2
WritableConstantStringObjectInspector stringObjectInspector = (WritableConstantStringObjectInspector) parameters[1];
separator = stringObjectInspector.getWritableConstantValue().toString();
}
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
static class StringAggBuffer implements AggregationBuffer {
StringBuilder buffer;
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
StringAggBuffer buffer = new StringAggBuffer();
reset(buffer);
return buffer;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((StringAggBuffer) agg).buffer = new StringBuilder();
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
if (parameters[0] != null) {
StringAggBuffer myAgg = (StringAggBuffer) agg;
if (myAgg.buffer.length() > 0) {
myAgg.buffer.append(separator);
}
myAgg.buffer.append(parameters[0].toString());
}
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
if (partial != null) {
StringAggBuffer myAgg = (StringAggBuffer) agg;
if (myAgg.buffer.length() > 0 && partial.toString().length() > 0) {
myAgg.buffer.append(separator);
}
myAgg.buffer.append(partial.toString());
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
StringAggBuffer myAgg = (StringAggBuffer) agg;
result.set(myAgg.buffer.toString());
return result;
}
}
}
4.2.3、UDAF 注册到 Hive
- 打包: 首选需要打包 UDF 包,比如 bigdata-udf-1.0-SNAPSHOT.jar
- 上传文件: 然后放到对应的HDFS路径,比如 hdfs://bigdataedu///project/shscnq/udf/
create temporary function UDAFGroupConcat as 'com.bigdata.udaf.UDAFGroupConcat'
using jar 'hdfs://bigdataedu///project/shscnq/udf/bigdata-udf-1.0-SNAPSHOT.jar';
4.2.4、UDAF 实现效果
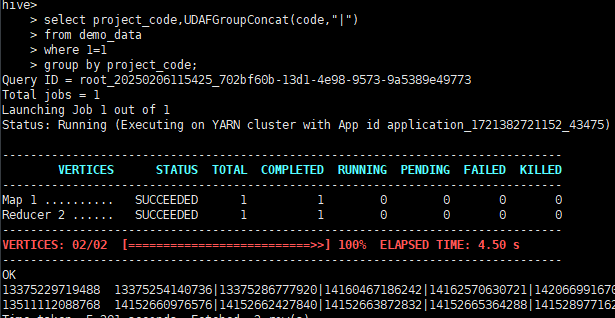
- 查询 SQL
select project_code,UDAFGroupConcat(code,"|")
from demo_data
where 1=1
group by project_code;
- 查询结果
4.3、JSON数组拆分,UDTF实现
4.2.1、需求背景
把解析 Json 数组 和 解析数组内 Json 拆开,更灵活且更多的使用 Hive 内部函数,性能更高。
4.2.2、UDTF 实现
package com.bigdata.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import org.json.JSONException;
import java.util.ArrayList;
import java.util.List;
public class UDTFExplodeJsonArray extends GenericUDTF {
/**
* 这个initialize()方法只会被执行一次,相当于是校验出入类型,声明输出类型,然后将元数据加载到内存中,给process等方法进行调用
* @param argOIs
* @return
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
/**
* 1、参数校验,个数,类型
*/
List<? extends StructField> refs = argOIs.getAllStructFieldRefs();
//1.1 参数格式校验
if (refs.size() != 1 ){
throw new UDFArgumentException("ExplodeJsonArray's arguments size must be one ,but you lost or beyond 1 ");
}
//1.2 参数类型校验,如果函数有多个参数,那么我们需要遍历分别校验类型
StructField field = refs.get(0);
String typeName = field.getFieldObjectInspector().getTypeName();
if (!"string".equals(typeName.toLowerCase())){
throw new UDFArgumentException("ExplodeJsonArray 的 initialize只能接受一个string类型的参数");
}
/**
* 2、将函数需要输出结果字段名称、字段类型封装到一个对象检查器中,然后返回该对象检查器
*/
//PrimitiveObjectInspectorFactory.javaStringObjectInspector.create(); //这个只能获取基本数据类型的检查器
//我们需要返回一个复杂数据类型的数据类型,得换一个工厂类
ArrayList<String> structFieldNames = new ArrayList<String>(); //这里放的是所有的column name,通过lateral view fc() tbl as c1,...cn
//我们只需要返回一个String类型的json字符串,所以只需要添加并返回一个类型名称,这个名称随便取
structFieldNames.add("json_col");
//然后获取一个String类型的objectInspector,用来表示返回值的类型
ArrayList<ObjectInspector> objectInspector = new ArrayList<ObjectInspector>();
objectInspector.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//最终返回该类型的对象校验器
StructObjectInspector outSOI = ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames,objectInspector);
return outSOI;
}
/**
* 这个方法会对循环为每个对象调用
* @param objects
* @throws HiveException
*/
public void process(Object[] objects) throws HiveException {
//这是传入的一个jsonArray的字符串对象,我们要将这个jsonArray转换成真正的JsonArray对象
String jsonArrayStr = objects[0].toString();
JSONArray jsonArray = null;
try {
//转换成真正的JsonArray对象
jsonArray = new JSONArray(jsonArrayStr);
//根据JsonArray的长度遍历,将其中的每个JsonObject转换成简单的字符串
for (int i = 0; i < jsonArray.length(); i++) {
//[{},{},{}],获取到需要被输出的数组中的一个json字符串{}
String singlejson = jsonArray.getString(i);
String[] jsons = new String[1];
jsons[0]=singlejson;
//最终通过forward方法将数据传给下一个操作
forward(jsons);
}
} catch (JSONException e) {
e.printStackTrace();
}
}
public void close() throws HiveException {
}
}
4.2.3、UDTF 注册到 Hive
- 打包: 首选需要打包 UDF 包,比如 bigdata-udf-1.0-SNAPSHOT.jar
- 上传文件: 然后放到对应的HDFS路径,比如 hdfs://bigdataedu///project/shscnq/udf/
create temporary function UDTFExplodeJsonArray as 'com.bigdata.udtf.UDTFExplodeJsonArray'
using jar 'hdfs://bigdataedu///project/shscnq/udf/bigdata-udf-1.0-SNAPSHOT.jar';
4.2.4、UDTF 实现效果
- 查询 SQL
select
distinct
uuid,
t1.questions,
t2.question_json,
get_json_object(t2.question_json,'$.number') as number
from u_ods.ods_u_st_t_xiaoxian_papers t1
lateral view UDTFExplodeJsonArray(t1.questions) t2 as question_json
where 1=1
and uuid = '152216097281643527444'
;
- 查询结果
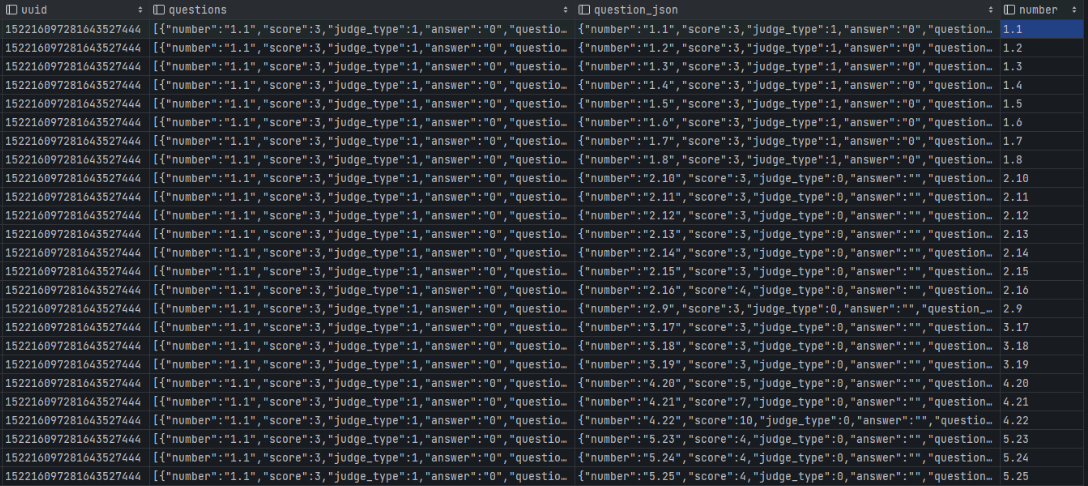
从结果可以看出,一个 Json 数组 (questions字段),解析成 26 个 Json 字符串 (question_json 字段),解析 Json key (number 字段)。



















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











