



目录
一、功能全景概览
本次开发的 Python 爬虫,聚焦当当网图书搜索结果页,实现自动化采集图书核心数据(价格、书名、出版社、评论) 。通过requests发起 HTTP 请求获取网页内容,利用lxml的etree结合 XPath 精准解析页面节点,最后借助pandas将数据规整存储为 CSV 文件,为后续图书市场分析、价格监测等场景提供数据支撑。
二、环境依赖与筹备细节
(一)关键库深度解读
- requests:作为 Python 最常用的 HTTP 请求库,它简化了复杂的网络请求流程。不仅能发送 GET、POST 等多种请求,还可便捷设置请求头、参数、超时时间等。在本爬虫中,负责向当当网服务器 “伸手要数据”,把网页 HTML 内容 “搬” 到本地 。
- lxml.etree:依托 libxml2 库,解析 HTML 文本效率高,且完美支持 XPath 表达式。它能把杂乱的 HTML 字符串转化为结构化的 DOM 树,让我们可以像 “查字典” 一样,用 XPath 精准定位并提取所需数据节点 。
- time、random:
time.sleep:控制请求频率,让爬虫 “慢下来”,模拟人类浏览网页的间隔,降低被网站反爬机制识别的概率。random.uniform:生成随机等待时间,进一步混淆请求规律,让网站更难判断是机器批量请求 。
- pandas:强大的数据处理库,将爬取的字典列表转化为 DataFrame 后,能轻松实现数据清洗、格式转换,还可一键保存为 CSV、Excel 等文件,让采集的数据 “有条理地安家” 。
(二)安装与环境验证
- 通过
pip一键安装依赖: -
pip install requests lxml pandas - 安装完成后,可在 Python 交互环境验证:
- 运行
import requests
from lxml import etree
import pandas as pd
# 若无报错,说明环境就绪
三、核心逻辑拆解(函数分步精讲)
(一)函数定义与初始化:搭建爬虫 “骨架”
python
运行
def scrape_dangdang_books(keyword, pages=2):
# 请求头:模拟浏览器身份,绕过基础反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
products = [] # 存储图书数据的“容器”,每个元素是一本图书的信息字典
max_retries = 5 # 请求重试次数上限,应对网络波动、短暂封禁
- 参数设计考量:
keyword需提前做 URL 编码(如 “大数据” 转%B4%F3%CA%FD%BE%DD),贴合当当网搜索接口规则;pages设置默认值 2,既满足简单采集需求,又支持灵活扩展爬取深度 。 headers的隐藏作用:除模拟浏览器,部分网站会校验User-Agent、Referer等字段,后续若遇到反爬升级,可补充Referer(当前请求页的来源页 )、Cookie(维持登录态 )等字段强化伪装 。
(二)分页请求逻辑:应对网络与反爬的 “博弈”
python
运行
for page in range(pages):
# 构造分页URL:page_index从1开始,与当当网前端页码对应
url = f'https://search.dangdang.com/?key={keyword}&act=input&page_index={page + 1}'
retries = 0 # 初始化重试计数器
# 重试机制:网络超时、服务器500错误等场景自动重试
while retries < max_retries:
try:
print(f"正在请求第 {page + 1} 页,URL: {url}")
# 发送GET请求,携带请求头
response = requests.get(url, headers=headers)
# 检查响应状态:非200状态码(如403、404)抛出异常
response.raise_for_status()
break # 请求成功,跳出重试循环,进入解析环节
except requests.RequestException as e:
# 捕获请求异常(超时、连接错误等)
print(f"请求第 {page + 1} 页失败,重试中... 错误信息: {e}")
retries += 1
time.sleep(1) # 等待1秒,避免短时间内频繁重试触发反爬
else:
# 重试次数耗尽,跳过当前页,记录失败日志
print(f"请求第 {page + 1} 页多次失败,跳过此页")
continue
- URL 构造细节:当当网搜索接口通过
page_index参数控制分页,需严格遵循page + 1的规则(前端页码从 1 起始 ),否则会出现页码错乱、数据重复 / 缺失问题 。 - 重试机制优化点:可扩展为 “梯度重试”,如第一次等待 1 秒,第二次 3 秒,第三次 5 秒,平衡重试效率与反爬规避 ;也可结合日志库(如
logging),记录详细失败信息,便于排查问题 。
(三)XPath 解析与数据提取:精准 “挖掘” 信息
运行代码:
try:
# 将响应文本转为可 XPath 查询的 DOM 树
html = etree.HTML(response.text)
# 定位图书列表容器:所有图书信息包裹在 class 为 bigimg 的 ul 下的 li 中
product_list = html.xpath('//ul[@class="bigimg"]/li')
for product in product_list:
# 1. 提取价格:定位价格 span,处理“¥”符号
price_elements = product.xpath('.//span[@class="search_now_price"]/text()')
price = price_elements[0].strip('¥') if price_elements else '无价格'
# 2. 提取书名:从图书封面 a 标签的 title 属性获取
book_name_elements = product.xpath('.//a[@class="pic"]/@title')
book_name = book_name_elements[0] if book_name_elements else '无书名'
# 3. 提取出版社:通过层级定位,p[5]、span[3] 需严格匹配网页结构
publisher_elements = product.xpath('.//p[5]/span[3]/a/text()')
publisher = publisher_elements[0] if publisher_elements else '无出版社'
# 4. 提取评论:从评论数 a 标签获取文本
comment_elements = product.xpath('.//p[4]/a/text()')
comment = comment_elements[0] if comment_elements else '无评论'
# 封装为字典,统一数据格式
product_info = {
'价格': price,
'书名': book_name,
'出版社': publisher,
'评论': comment
}
products.append(product_info)
except Exception as e:
# 捕获解析异常(如 XPath 语法错、节点不存在)
print(f"解析第 {page + 1} 页 HTML 时出错: {e}")
# 随机等待 1-3 秒,降低被网站识别为爬虫的概率
time.sleep(random.uniform(1, 3))
- XPath 表达式深度解析:
//ul[@class="bigimg"]/li:双斜杠//表示从根节点开始全局查找,[@class="bigimg"]是属性筛选,精准定位图书列表的父容器ul,再通过/li获取每个图书项 。若网页结构调整(如ul的 class 变更 ),需同步修改,否则会提取失败 。.//span[@class="search_now_price"]/text():点·表示从当前product节点(li)开始查找,避免全局搜索干扰;text()提取节点文本内容,后续用strip('¥')清理冗余符号 。- 其他表达式逻辑:书名通过
@title提取属性值,出版社、评论依赖严格的层级路径(p[5]/span[3]),若网页布局变动(如p标签顺序调整 ),需重新调试 XPath 。- 异常处理延伸:可细化异常类型(如
etree.XPathEvalError处理 XPath 语法错,IndexError处理列表为空 ),针对性修复问题;也可记录错误页面的 HTML 到文件,辅助人工排查结构变动 。
(四)数据存储:让采集成果 “落地”
运行代码:
if products:
# 转换为 DataFrame,指定列顺序,规范输出
df = pd.DataFrame(products, columns=['价格', '书名', '出版社', '评论'])
# 保存为 CSV 文件:utf-8-sig 编码适配中文,index=False 去除行索引
df.to_csv('dangdang_products.csv', index=False, encoding='utf-8-sig')
print("数据已成功保存到 dangdang_products.csv 文件中。")
else:
print("未获取到任何有效数据。")
pandas操作优势:相比手动写入 CSV(需处理编码、分隔符 ),DataFrame.to_csv更简洁高效;后续若需分析数据,可直接基于 DataFrame 做去重(drop_duplicates)、统计(value_counts)等操作 。- 存储扩展思路:可增加数据追加模式(
mode='a'),支持持续采集多关键词数据;或对接数据库(如 MySQL,用df.to_sql),实现结构化存储与长期管理 。
四、函数调用与场景扩展
(一)基础调用示例
运行代码:
if __name__ == '__main__':
# “大数据”关键词的 URL 编码,可通过 urllib.parse.quote 生成
keyword = "%B4%F3%CA%FD%BE%DD"
pages = 2 # 爬取前 2 页数据
scrape_dangdang_books(keyword, pages)
- 关键词编码技巧:手动编码易出错,可借助 Python 标准库动态生成:
运行代码:
from urllib.parse import quote
keyword = quote('大数据') # 输出 %B4%F3%CA%FD%BE%DD
- 入口逻辑意义:
if __name__ == '__main__'是 Python 脚本规范写法,确保函数仅在脚本直接运行时执行。若作为模块被其他代码导入,可避免自动触发爬虫,方便复用函数逻辑 。
(二)功能扩展与反爬对抗
1. 反爬增强策略
- 代理 IP 池接入:
运行代码:
# 示例:配置代理(需替换为有效代理 IP)
proxies = {
'http': 'http://123.45.67.89:8080',
'https': 'https://123.45.67.89:8080'
}
# 在 requests.get 中添加 proxies 参数
response = requests.get(url, headers=headers, proxies=proxies)
通过轮换代理 IP,规避当当网的 IP 封禁限制。可结合免费代理池(如proxy_pool库 )或付费代理服务,保障爬虫稳定性 。
- 验证码识别集成:若遇到验证码拦截,可对接打码平台(如超级鹰 ):
运行代码:
# 伪代码:调用打码 API
from chaojiying import Chaojiying_Client # 假设的打码客户端
cjy = Chaojiying_Client('用户名', '密码', '软件ID')
# 上传验证码图片,获取识别结果
result = cjy.PostPic(open('captcha.png', 'rb'), 1902) # 1902 为验证码类型
需先捕获验证码图片(从响应 HTML 中提取img链接 ),再调用接口识别,最后将识别结果填入请求表单 / 参数 。
2. 数据清洗与监控
- 异常值处理:
运行代码:
# 采集后清洗:过滤“无出版社”等无效数据
df = df[df['出版社'] != '无出版社']
# 价格转换为数值类型(若需分析)
df['价格'] = df['价格'].astype(float)
通过pandas筛选有效数据,转换数据类型,为后续分析铺路 。
- 采集监控:结合
logging记录采集进度、失败页码:
运行代码:
import logging
logging.basicConfig(filename='crawl.log', level=logging.INFO)
# 在关键环节记录日志
logging.info(f"第 {page + 1} 页采集完成,获取 {len(product_list)} 条数据")
便于追溯采集过程,及时发现大规模失败、数据异常等问题 。
五、代码结果
代码如下:
爬取成功结果如下:
用csv的形式展示结果
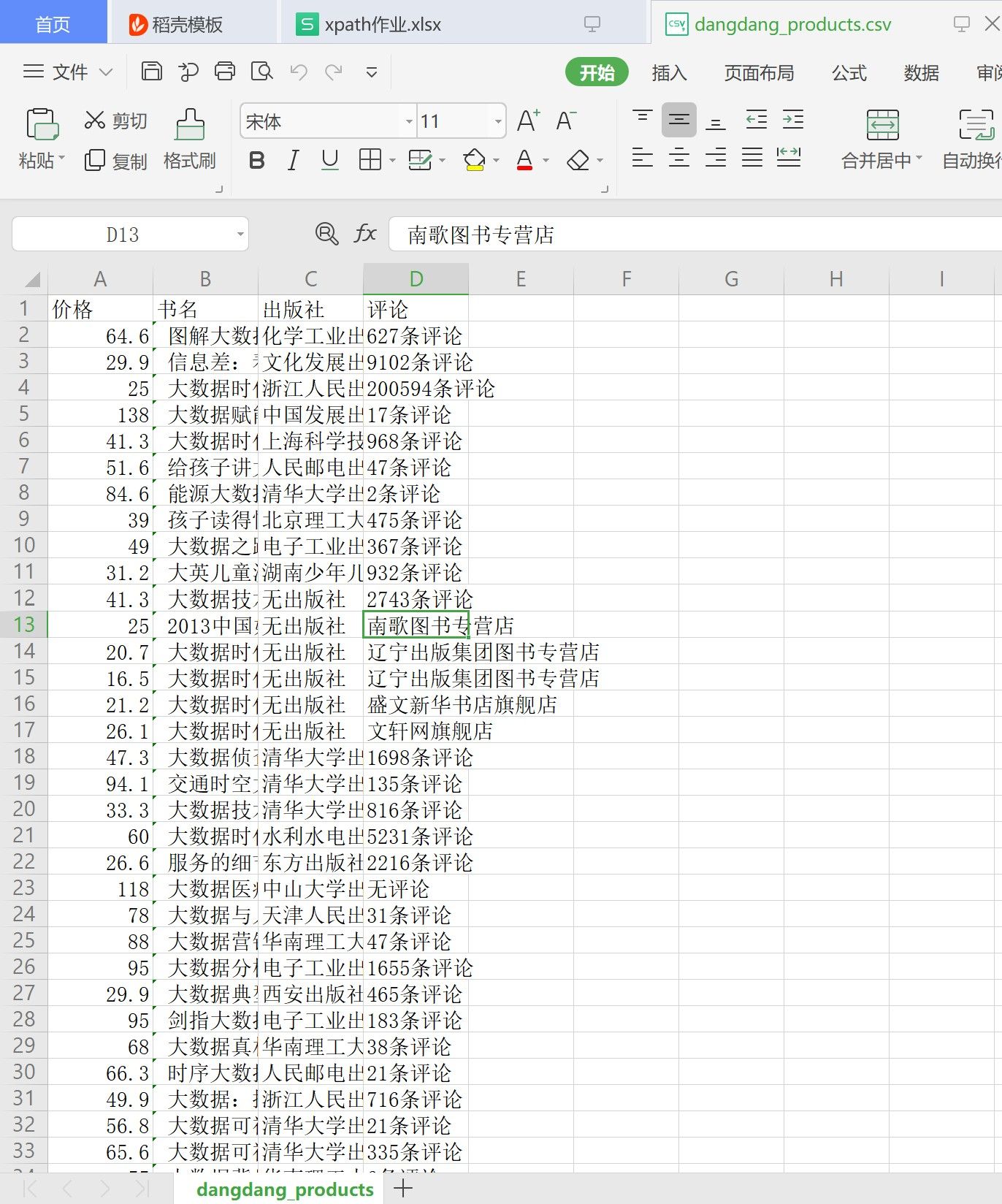
这样既是爬取成功!
六、总结与实践建议
通过拆解scrape_dangdang_books函数,我们清晰梳理了请求发送→重试机制→XPath 解析→数据存储的完整流程,每个环节都蕴含着应对网络波动、反爬策略、网页结构变动的技巧 。
实践建议:
- 先静态分析:用浏览器开发者工具(F12 )查看网页结构,确认 XPath 表达式有效性,再编写代码 。
- 小步调试:先爬取 1 页数据,验证解析逻辑、存储流程无误后,再扩展分页、反爬策略 。
- 关注反爬动态:当当网反爬规则可能调整(如新增验证码、限制请求频率 ),定期检查爬虫运行状态,及时优化代码 。
掌握这些知识点,不仅能灵活修改本爬虫适配其他电商平台(如京东图书、天猫图书 ),更能搭建起通用爬虫开发的思维框架,面对不同网站的数据采集需求,快速拆解、实现方案 。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









