






 本文详细介绍了Hive的分区技术,包括分区的原因、方式、意义和操作,如分区创建、数据加载、分区修改与删除。接着讨论了分桶的概念,强调了分桶在数据管理和查询效率上的优势,并提供了分桶表的创建与数据导入方法。同时,文章通过实例解释了动态分区、静态分区和混合分区的使用,并总结了分区与分桶的关键点。
本文详细介绍了Hive的分区技术,包括分区的原因、方式、意义和操作,如分区创建、数据加载、分区修改与删除。接着讨论了分桶的概念,强调了分桶在数据管理和查询效率上的优势,并提供了分桶表的创建与数据导入方法。同时,文章通过实例解释了动态分区、静态分区和混合分区的使用,并总结了分区与分桶的关键点。
为什么要分区?
随着系统运行时间增长,表的数据量越来越大,而hive查询通常是全表扫描,这样会导致大量不必要的数据扫描,从而大大降低了查询效率。
从而引进了分区技术,使用分区技术,避免hive全表扫描,提升查询效率。
分区的技术
PARTITIONED BY (column_name data_type)
1、hive分区是区分大小写的
2、hive的分区本质是在表目录下创建分区目录,但是该分区字段是一个伪列,不真实存在于数据中。age=19
3、一张表中可以有一个或多个分区,分区下面也可以有一个或者多个分区。
如何分区?
根据业务需求,通常采用年、月、日、地区等。
分区的意义
可以让用户在做数据统计时缩小数据扫描的范围,因为可以在select时指定分区条件
创建一层分区
create table if not exists part1(
uid int,
uname string,
uage int
)
PARTITIONED BY (country string)
row format delimited
fields terminated by ','
;
分区表的数据导入方式:part1表名 然后指定分区partition(country='china'); 分区目录
将文件从哪里上传到哪个表里面,然后指定分区
load data local inpath '/hivedata/stu1.txt' into table part1 partition(country='china');
load data local inpath '/hivedata/stu_japan.txt' into table part1 partition(country='japan');
load data local inpath '/hivedata/stu1.txt' into table part1 partition(COUNTRY='CHINA');
做分区一定要带条件查询(内容是区分大小写的)
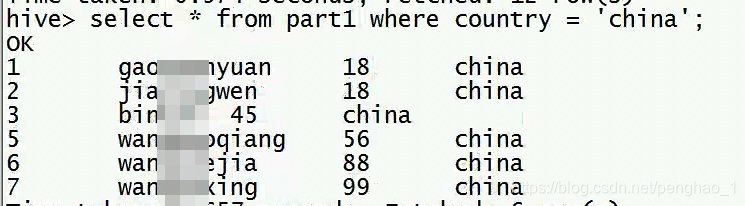
字段等于分区的内容

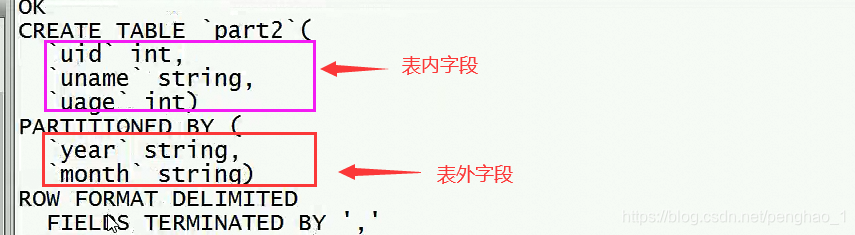
创建二级分区:
create table if not exists part2(
uid int,
uname string,
uage int
)
PARTITIONED BY (year string,month string)
row format delimited
fields terminated by ','
;
加载数据:
load data local inpath '/hivedata/stu1.txt' into table part2 partition(year='2019',month='07');
load data local inpath '/hivedata/stu_japan.txt' into table part2 partition(year='2019',month=08);
load data local inpath '/hivedata/stu1.txt' into table part2 partition(year='2018',month='07');
load data local inpath '/hivedata/stu1.txt' into table part2 partition(year='2019',month='09');
load data local inpath '/hivedata/stu1.txt' into table part2 partition(year='2019',month='06');
创建三级分区:
create table if not exists part3(
uid int,
uname string,
uage int
)
PARTITIONED BY (year string,month string,day string)
row format delimited
fields terminated by ','
;
加载数据:
load data local inpath '/hivedata/stu1.txt' into table part3 partition(year='2019',month='07',day='19');
load data local inpath '/hivedata/stu_japan.txt' into table part3 partition(year='2019',month='08',day='01');
load data local inpath '/hivedata/stu1.txt' into table part3 partition(year='2018',month='07',day='18');
显示分区:
show partitions part3;
修改分区:
分区的名字不能修改(可以手动改)
增加分区:
alter table part2 add partition(year='2018',month='08');
alter table part2 add partition(year='2018',month='09') partition(year='2018',month='10') ;
增加分区并且设置数据:
alter table part2 add partition(year='2018',month='06') LOCATION '/user/hive/warehouse/gp1923.db/part2/year=2019/month=08';
修改分区的hdfs的存储路径:(指定的路径是hdfs的绝对路径)
ALTER TABLE part2 PARTITION(year='2018',month='06') SET LOCATION 'hdfs://gp1923/user/hive/warehouse/gp1923.db/part2/year=2018/month=06';
删除分区:
alter table part2 drop partition(year='2018',month='06');
删除多个:
alter table part2 drop partition(year='2018',month='09'),partition(year='2018',month='10');
分区类型:
静态分区:加载数据时指定分区的值
动态分区:数据未知,根据分区的值确定需要创建的分区。
混合分区:静态+动态动态分区的属性:
<!---动态分区的属性-->
<property>
<name>hive.exec.dynamic.partition</name>
<value>true</value>
<description>Whether or not to allow dynamic partitions in DML/DDL.</description>
</property>
<!---动态分区的模式,有严格模式和非严格模式-->
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>strict</value>
<description>
In strict mode, the user must specify at least one static partition
in case the user accidentally overwrites all partitions.
In nonstrict mode all partitions are allowed to be dynamic.
</description>
</property>
<!---一条sql语句中动态分区最大的数量-->
<property>
<name>hive.exec.max.dynamic.partitions</name>
<value>1000</value>
<description>Maximum number of dynamic partitions allowed to be created in total.</description>
</property>
<!---每个节点多少个区-->
<property>
<name>hive.exec.max.dynamic.partitions.pernode</name>
<value>100</value>
<description>Maximum number of dynamic partitions allowed to be created in each mapper/reducer node.</description>
</property>
测试动态分区:
create table if not exists part_tmp
as
select * from part2
where year = '2019'
;
![]()
--然后往分区表里面写数据
create table if not exists dy_part(
uid int,
uname string,
uage int
)
partitioned by (year string,month string)
row format delimited
fields terminated by ','
;
动态分区不能使用load方式加载数据
load data local inpath '/hivedata/stu1.txt' into table dy_part partition(year='2019',month);
动态分区采用insert into的方式(动态分区来源于表)
set hive.exec.dynamic.partition.mode=nonstrict; 设置为动态分区
--分区来源于表
insert overwrite table dy_part partition(year,month)
select * from part_tmp
;

混合:(注意字段的个数匹配)
--严格模式下要指定一个静态分区
--2019是不用再查的了,已经指定了,其他的字段需要查询出来
insert overwrite table dy_part partition(year='2019',month)
select uid,uname,uage,month from part_tmp
;
设置hive执行的严格模式:
<property>
<name>hive.mapred.mode</name>
<value>nonstrict</value>
<description>
The mode in which the Hive operations are being performed.
In strict mode, some risky queries are not allowed to run. They include:
Cartesian Product.
No partition being picked up for a query.
Comparing bigints and strings.
Comparing bigints and doubles.
Orderby without limit.
</description>
</property>
注意事项:
1、hive的分区使用的是表外字段,分区字段是一个伪列但是可以做查询过滤。
2、分区字段不建议使用中文
3、不太建议使用动态分区,因为动态分区将会使用mr来进行查询数据。如果分区数量过多将会导致namenode和yarn的性能瓶颈,所以建议动态分区前尽可能的预知分区数量。(分区的本质在表目录下创建子目录,目录是在hdfs上,namenode管理目录树结构,创建一个写一个,创建目录时namenode则一直在写文件)
4、分区属性修改均可以使用手动元数据和hdfs数据内容的方式来进行
--分桶---------------------------
为什么要分桶
单个分区或者表中的数据量越来越大,当分区不能更细粒度的划分数据时,所以会采用分桶技术将数据更细粒度的划分和管理。
分桶技术:
[CLUSTERED BY (COLUMN_NAME)
[SORTED BY COLUMN_NAME ASC| DESC ] INTO 4 BUCKETS]
分桶关键字:bucket
默认采用对分桶字段进行hash值%总桶数的的余数就是分桶的桶数。
分桶的意义
1、为了保存分桶查询结果的分桶结构(数据已经按照分桶字段进行了hash散列)
2、分桶的应用场景:数据抽样和JOIN时可以提高MR的执行效率
##创建分桶表(可以按照id分,也可以按照名字分)
create table if not exists buc1(
uid int,
uname string,
uage int
)
clustered by (uid) into 4 buckets --按照什么字段来分桶,这个设置为4桶
row format delimited
fields terminated by ','
;
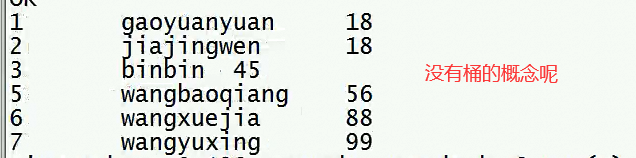
加载数据:
不能通过load方式加载,否则看到的是下面的截图,没有分桶的概念
load data local inpath '/hivedata/stu1.txt' into table buc1;
1、设置强制分桶属性:先打开,默认是fase
<property>
<name>hive.enforce.bucketing</name>
<value>false</value>
<description>Whether bucketing is enforced. If true, while inserting into the table, bucketing is enforced.</description>
</property>

select uid,uname,uage
from part_tmp
where year = '2019' and month = '06'
cluster by (uid)
;
2、需要设置reduce的数量:(如果reducer的数量和分桶的个数不一致时,请手动设置:)
set mapreduce.job.reduces=4;(设置分桶的数量)

Reduce是的数量是1个时候才可以跑本地,多个时候是不可以跑本地的
![]()

分桶数据需要通过insert into 方式加载
insert overwrite table buc1
select * from t4
cluster by (id)
;
创建分桶表,指定排序字段和排序规则
create table if not exists buc2(
uid int,
uname string,
uage int
)
clustered by (uid)
sorted by (uid asc) into 4 buckets--4桶 sorted by (uid asc) 对数据的排序没有影响
row format delimited --指定排序规则
fields terminated by ','
;

桶内有序,桶与桶是无序的
导数据:(数据最后的顺序是由语句来操作的)
--正序
insert into buc2
select * from t4
distribute by (id) sort by (id asc)
;
--倒序
insert overwrite table buc2
select * from t4
distribute by (id) sort by (addr desc)
;
--字段的正序逆序排列,是由语句来决定的
对分桶进行查询:
-- out of相当于一个循环,后面是循环的数量
--查询全部:
select * from buc2;
select * from buc2 tablesample(bucket 1 out of 1);
--bucket 1表示从从第几桶开始取数据,out of 1就是把整体的数据重制为1桶
--查询第几桶:将数据分为4桶,4桶里面取第二桶。余数+1是桶数
select * from buc2 tablesample(bucket 2 out of 4);
--4桶里面取第二桶
--查询余数为1的
select * from buc2 tablesample(bucket 2 out of 2);
select * from buc2 tablesample(bucket 2 out of 2 on uid);
--8桶里面取第二桶
select * from buc2 tablesample(bucket 2 out of 8);
--指定分桶依据,可以用uid作为分桶字段
select * from buc2 tablesample(bucket 2 out of 7 on uid);
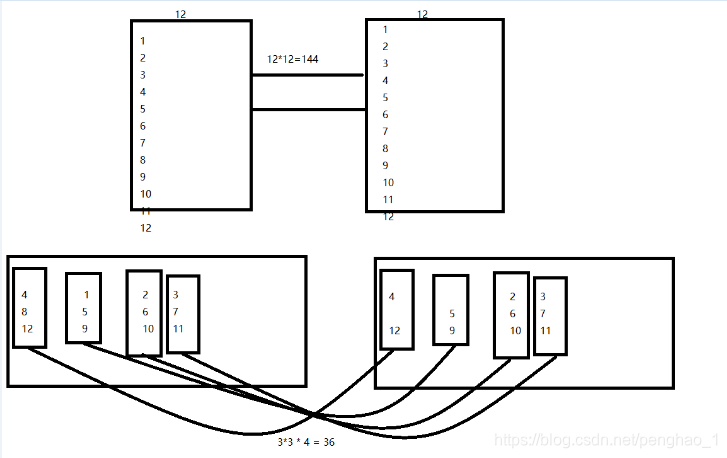
tablesample(bucket x out of y on uid)
x:代表从第几桶开始
y:查询的总桶数,y可以是总桶数的倍数或者因子,x不能大于y
规律如下
1、不压缩不拉伸:
1 2 3 4
1 1+4 --如果没拿完,则继续从1开始
for 1 to 4 --从1开始循环4桶
i=1 1 --i等于1,取第一桶
i=2 x --i等于2,不拿
3 x --i等于3,不拿
4 x --i等于4,不拿
y --到这里就已经结束了
5 1
压缩:
1 1+4/2 1+4/2+4/2
1 2 3 4
1 out of 2 ---这个2表示多少个数进行循环,1是循环中取第一桶。这个是i循环完了桶没有迭代完
for 1 to 2
i=1 1 --第一桶拿出来
i=2 x --不拿
i=1 3 -- 没循环完 ,所以还要循环取
i=2 x --不拿
i=1 5
拉伸:
1 2 3 4
2 out of 8
for i=1 to 8 --只有4桶,但是循环8次,也就是到i5的时候,同数循环完了,但是循环的次数还没有完,则继续回到第一桶开始
i=1 1
2 2
3
4
i=5 1 --其实就是原来数据的第一桶
i=6 2 --其实就是原来数据的第二桶
需求:查询所有id为奇数的学生
--也就是将获取余数为1的记录
select * from buc2 tablesample(bucket 2 out of 2 on uid)
;
查询:
limit 3--查3行
select * from part_tmp limit 3;--直接查询3行
select * from part_tmp tablesample(3 rows);--查询3行
select * from part_tmp tablesample(50 percent);--查询50%
select * from part_tmp tablesample(50B);k M G --字节读取
查询任意的3条数据
select * from t4 order by rand() limit 3;
分桶总结:
1、定义
clustered by (uid) -- 指定分桶的字段
sorted by (uid) -- 指定数据的排序规则,表示预期的数据就是以这种规则进行排序。
2、导数据时
cluster by(uid) --指定getPartition以哪个字段来进行hash,并且排序字段也是指定的字段,排序规则默认按正序进行排列
distribute by (uid) --指定getPartition以哪个字段来进行hash
sort by (age desc) --指定排序字段以及排序规则
cluster by(uid)
跟
distribute by (uid)
sort by (uid asc)
的执行效果是一样的
distribute by (uid)
sort by (age desc)
的方式更灵活
分区下的分桶:(先对数据分区,在分区条件下分桶)
按照性别分区(1男2女),在分区下按照id的奇偶分桶
1 gyy1 1
2 gyy2 2
3 gyy3 2
4 gyy4 1
5 gyy5 1
6 gyy6 1
7 gyy7 2
8 gyy8 1
9 gyy9 2
10 gyy10 2
11 gyy11 1
1、2,写sql
create table if not exists buc3(
id int,
name string
)
partitioned by(sex int) --先分区,按sex分区
clustered by(id) into 2 buckets--后分桶,按id进行分桶
row format delimited
fields terminated by '\t' --按tab进行分隔
;
--因为数据不能直接加载进来,所以需要创建一个临时表
create table if not exists buc_tmp(
id int,
name string,
sex int
)
row format delimited
fields terminated by '\t'
;
3、将数据放到某个目录下面,然后将数据放到临时表
![]()
4、将数据从临时表导入到分区分桶表(上面已经分区了)
set mapreduce.job.reduces=2;--设置桶数
insert overwrite table buc3 partition(sex)
select * from buc_tmp
cluster by (id) --分桶查询
;
5、查询性别为女、并且学号为奇数的学生:(查询奇数号的学生,通过性别进行过滤)
select *
from buc3 tablesample(bucket 2 out of 2 on id)
where sex=2
;
注意:
分区使用的表外字段(数据文件里面没有的字段),分桶使用的表内字段(数据文件里面有的字段)
分桶是更细粒度的管理数据,更多的用来做数据抽样、JOIN操作
---------------------
复习:
使用场景
关键字
3、导数据

















 2414
2414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









