




 本文介绍两种将CSV数据导入Elasticsearch的方法:使用DataX工具和Logstash工具。重点讲解了配置步骤及注意事项,包括解决中文乱码问题、DataX的Writeelasticsearch插件编译与使用、Logstash配置文件详解等。
本文介绍两种将CSV数据导入Elasticsearch的方法:使用DataX工具和Logstash工具。重点讲解了配置步骤及注意事项,包括解决中文乱码问题、DataX的Writeelasticsearch插件编译与使用、Logstash配置文件详解等。
1. 准备好ES、CSV文件
准备好一个es的集群环境,部署参考我的上一篇文章:
ELK部署:https://blog.youkuaiyun.com/pengge2/article/details/114533789
准备一个CSV的数据文件:
可以是mysql的连接工具sqlyong、navicat导出的csv数据文件,也可以是命令行mysql导出的>es.csv文件
也可以是手动写一个测试es.csv的文件
hdfs导出的csv文件等等等等
反正本篇就是写写如何将CSV数据文件写入ES
2. datax方式CSV写入es
准备一个阿里云的datax工具,不再废话啦直接下载解压就能用啦,特别注意的是write elasticsearch模块需要单独在make编译一下才会拥有哦
datax下载地址:
首先准备阿里的datax工具官网下载安装编译即可
https://github.com/alibaba/DataX
download 地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
Write elasticsearch plugin模块需要单独编译才能使用,使用需要下拉elastic的源码进行编译如下:

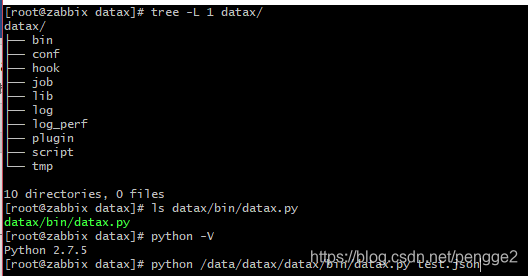
下载二进制文件之后,使用命令为:
python /data/datax/datax/bin/datax.py test.json
python为linux系统默认2.7.5版本即可
datax py为启动脚本文件
test.json为写入数据对应的数据模板文件
注:中文乱码可将字符集设置为"encoding": "GBK"即可解决乱码
cat > pengge.json << EOF
> {
> "setting": {},
> "job": {
> "setting": {
> "speed": {
> "channel": 2
> }
> },
> "content": [
> {
> "reader": {
> "name": "txtfilereader",
> "parameter": {
> "path": [
> "/data/datax/job/csv-es/data/es.csv"
> ],
> "encoding": "GBK",
> "column": [
> {
> "index": 0,
> "type": "string"
> },
> {
> "index": 1,
> "type": "string"
> },
> #......一直到97我这csv数据有99列数据字段,0读取的对应的就是第一列的字段内容,依次类推
> {
> "index": 98,
> "type": "string"
> }
> ],
> "fieldDelimiter": ","
> }
> },
> "writer": {
> "name": "elasticsearchwriter",
> "parameter": {
> "endpoint": "http://192.168.108.144:9200",
> "accessId": "admin",
> "accessKey": "123456",
> "index": "pengge",
> "type": "default",
> "cleanup": true,
> "settings": {
> "index": {
> "number_of_shards": 12,
> "number_of_replicas": 1
> }
> },
> "discovery": false,
> "batchSize": 2048,
> "trySize": 50,
> "splitter": ",",
> "column": [
> {
> "name": "cust_code",
> "type": "text"
> },
> {
> "name": "member_id",
> "type": "text"
> },
> #......一直到很多字段名称,太长就不显示啦没什么意思0读取的对应的就是第一列的字段内容,依次类推
> {
> "name": "statis_date",
> "type": "text"
},> },
> {
> "name": "statis_time",
> "type": "text"
> }
> ]
> }
> }
> }
> ]
> }
> }
> EOF
然后就这样简简单单的完事了,注意上面配置的几个点
GBK设置给kibana、elasticsearch查询的时候不会使中文乱码,出现那个不好看的字体“熊样子”,影响心情
这是我上传的es.csv测试数据表格文件的目录位置指定好:
/data/datax/job/csv-es/data/es.csv
下面es用到的账号密码随便写一个就行,因为我的es没有设置登录账号密码,但是不写这个字段datax会提示让加上不然写入不进去-.-
"accessId": "admin",
"accessKey": "123456",
然后启动datax写入es数据即可啦,就这么简单
python /data/datax/datax/bin/datax.py csv-es.json
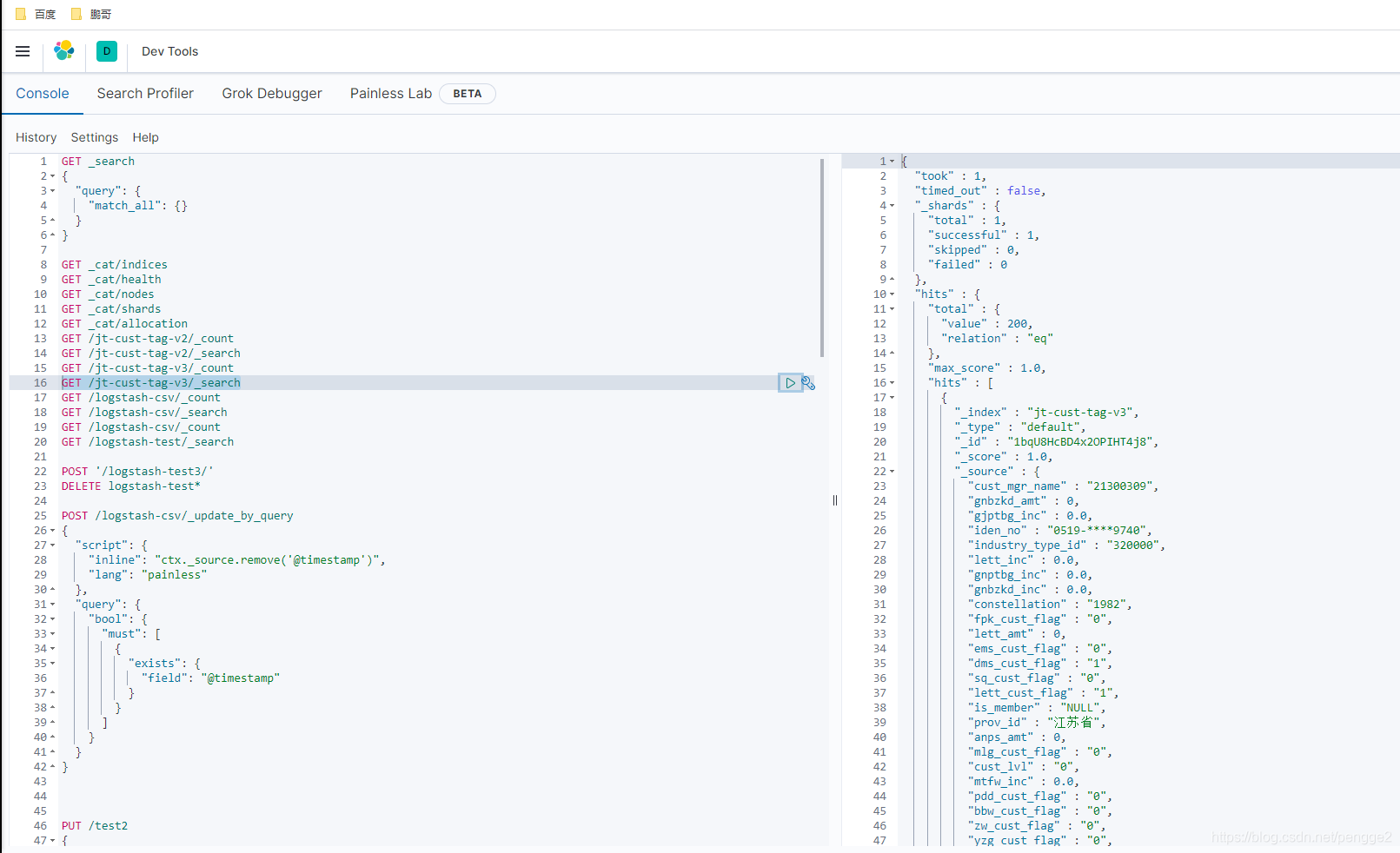
插入完毕查询一下就是下面这个样子啦
3. logstash方式CSV写入es
准备一个logstash必须要与elasticsearch版本一致
可能版本一致用的比较舒服吧,你如果非要用不同的版本给es写入数据也可以测试试试,自己开心就好
logstash部署没啥部署的,参考我上一篇给的人家官网下载地址下载一个就好啦
我这里放一个logstash安装包你在下载不是多此一举,浪费时间嘛,嘿嘿
省得的你翻到第一行再次贴一下上一篇文章地址:
https://blog.youkuaiyun.com/pengge2/article/details/114533789
=============================================================================
准备好logstash命令工具之后,需要注意的几个点:
每次执行完毕会在data目录生成一个隐藏文件
需要删除清空才能---成功---写入es哦!!!!!
测试的时候一直没有删除这个影藏文件以为有用,结果一直调试调试....真是"吐了老血啦"
导致一直无法正常写入es,你不想删除也可以自己开心就好 (#^.^#)
[root@zabbix file]# pwd
/data/kinbana/logstash7.8.1/logstash-7.8.1/data/plugins/inputs/file
[root@zabbix file]# ll -a
total 12
drwxr-xr-x 2 root root 4096 Mar 5 11:35 .
drwxr-xr-x 3 root root 4096 Feb 26 19:38 ..
-rw-r--r-- 1 root root 104 Mar 5 11:35 .sincedb_09e88075688d5bfff1ad626ac9075d2e
=============================================================================
cat job/csv-es-pengge.conf
input
{
file{
path => ["/data/kinbana/logstash7.8.1/logstash-7.8.1/bin/job/data/es.csv"]
start_position => "beginning"
}
}
filter{
csv{
separator => ","
columns => ["cust_code","member_id","is_member","mem_reg_date","busi_code","cust_type_id","cust_status_id","cust_name","gender","zodiac","constellation","bir_y","bir_m","bir_d","iden_type_id","iden_no","cont_number","cust_lvl","grp_cust_lvl","industry_type_id","prov_id","prov_name","city_id","city_name","county_id","county_name","org_code","org_name","cust_mgr_code","cust_mgr_name","mgr_org_code","mgr_org_name","lett_amt","aphil_amt","anps_amt","dms_amt","whfw_amt","mtfw_amt","ec_amt","gnptbg_amt","gjxb_amt","gjptbg_amt","ec_jyx_amt","ec_cx_amt","gnbzkd_amt","kdbg_amt","gjkd_amt","wl_amt","all_amt","lett_inc","aphil_inc","anps_inc","dms_inc","whfw_inc","mtfw_inc","ec_inc","gnptbg_inc","gjxb_inc","gjptbg_inc","ec_jyx_inc","ec_cx_inc","gnbzkd_inc","kdbg_inc","gjkd_inc","wl_inc","all_inc","aphil_cust_flag","dms_cust_flag","lett_cust_flag","fpk_cust_flag","yzg_cust_flag","active_cust_flag","dorm_cust_flag","effic_cust_flag","ineffic_cust_flag","valid_cust_flag","invalid_cust_flag","xyyd_cust_flag","nbk_cust_flag","nkb_cust_flag","ems_cust_flag","ebg_cust_falg","eyb_cust_flag","ibc_cust_flag","tbw_cust_flag","jdw_cust_flag","ylw_cust_flag","bbw_cust_flag","ddw_cust_flag","mlg_cust_flag","smt_cust_flag","jpw_cust_flag","pdd_cust_flag","zw_cust_flag","sq_cust_flag","ds_cust_flag","qd_cust_flag","statis_date","statis_time","month_id","day_id"]
}
mutate{
convert => {
}
remove_field => [ "host", "path", "message", "@version", "@timestamp" ]
}
}
output{
elasticsearch{
hosts => ["192.168.108.144:9200"]
index => "logstash-csv"
}
}
准备好这个写入conf文件就可以启动命令写入啦
写入前可以使用-t检查一下运行conf文件语法使用是否正确,如下就是ok的啦看到ok就ok
上面调试的"老血",就是一直ok配置文件没有问题一直写入不进去的原因就是上面的每次任务执行完毕file目录会生成的影藏文件导致的,可以这么理解要保证file目录下"干净纯洁"才能使用
[root@zabbix bin]# ./logstash -f job/csv-es-debug.conf -t
Sending Logstash logs to /data/kinbana/logstash7.8.1/logstash-7.8.1/logs which is now configured via log4j2.properties
[2021-03-09T15:24:03,282][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-03-09T15:24:05,485][INFO ][org.reflections.Reflections] Reflections took 46 ms to scan 1 urls, producing 21 keys and 41 values
Configuration OK
[2021-03-09T15:24:06,291][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
完事就可以-f指定 & 放入后台进行运行使用可爱的logstash啦~
./logstash -f job/csv-es-debug.conf &> job/log & && tail -f job/log
不在废话啦应该能看懂,不能浪费观看老板的任何一点点无用时间
=============================================================================
读取csv文件时需要手动修改后缀名称csv为txt
使用notepad打开将其内容修改为utf-8 然后再次修改为csv上传linux服务器进行引用
进入文件vim :set ff 查看是否为unix 若为doc 设置成unix即可 :set ff=unix
修改utf-8 vim打开csv中文显示乱码这个不必在意 csv识别不了utf-8导致
最终能让es以及linux服务器读取中文识别即可
其中上面可以直接添加remove_field来删除不需要的字段比如path time之类的
remove_field => [ "host", "path", "message", "@version", "@timestamp"
再贴一个kibana的查询字段语法吧,方便写入完毕数据粘贴一下命令省的敲字母,"浪费时间"
GET _cat/indices
GET _cat/health
GET _cat/nodes
GET _cat/shards
GET _cat/allocation
GET /pengge/_count
GET /pengge/_search
GET /logstash-csv/_count
GET /logstash-csv/_search
删除索引
DELETE test*
删除索引内的指定字段
POST /logstash-csv/_update_by_query
{
"script": {
"inline": "ctx._source.remove('@timestamp')",
"lang": "painless"
},
"query": {
"bool": {
"must": [
{
"exists": {
"field": "@timestamp"
}
}
]
}
}
}
创建索引以及字段
PUT /test2
{
"mappings": {
"properties": {
"cust_code":{"type":"text","index":"true"},
"member_id":{"type":"text","index":"true"},
中间有99个字段一坨省略了 写太长也没啥意思,
"statis_time":{"type":"text","index":"true"}
}
},
"settings" : {
"number_of_shards" : 12,
"number_of_replicas" : 1
}
}
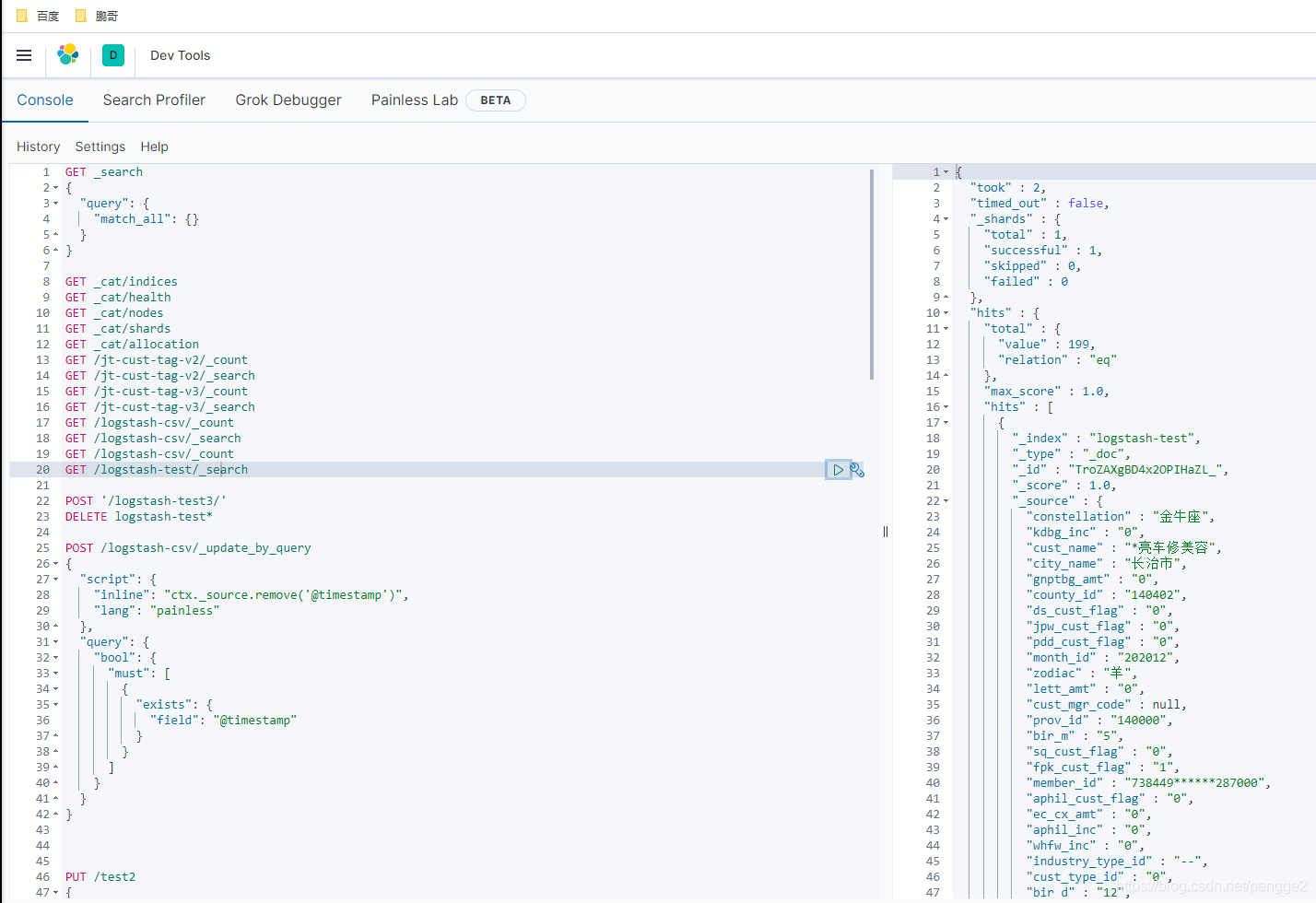
到这里就完事啦,写完之后就是下面这个"熊样子"
好啦,祝愿各位观看的老板,天天开心,开开心心生活,快快乐乐的工作,迎接美好的每一天~~

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









