




一、什么是HASH?
哈希表是一种高级的数据结构。
哈希表的基本原理:使用哈希函数h将U映射到表T[0..m-1]的下标上(m=O(|U|))。这样以U中关键字为自变量,以h为函数的运算结果就是相应结点的存储地址。从而达到在O(1)时间内就可完成查找。
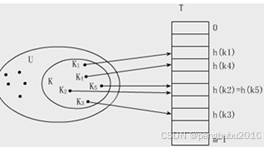
二、哈希函数的构造方法
选择适当的哈希函数是重中之重,构造哈希函数有两个标准:简单和均匀。
简单是指哈希函数的计算要简单快速;
均匀是指对于关键字集合中的任一关键字,哈希函数能以等概率将其映射到表空间的任何一个位置上。也就是说,哈希函数能将子集U随机均匀地分布在表的地址集{0,1,...,m-1}上,以使冲突最小化。
三、整数的Hash函数构造方法
1.直接取余法
关键字k除以m,取余数作为在Hash表中的位置。函数表达式可以写成:h(k)=k mod m,一般m选择为大素数
2.数字分析法
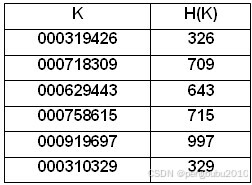
关键字的位数比较多时,可以对关键字的各位进行分析,丢掉分布不均匀的位留下分布均匀的位作为地址。
比如下表中的关键字k的第4、8、9位分布比较均匀,所以留下这3位作为地址
3.乘积取整法
关键字k乘以一个在(0,1)中的实数A(最好是无理数),得到一个(0,1)之间的实数;取出其小数部分,乘以m,再取整数部分,即得k在Hash表中的位置。函数表达式可以写成:

4.平方取中法
把关键字k平方,然后取中间的[log2m]位作为Hash函数值返回。
由于k的每一位都会对其平方中间的若干位产生影响,因此这个方法的效果也是不错的。但是对于比较小的k值效果并不是很理想,实现起来也比较繁琐。
为了充分利用Hash表的空间,m最好取2的整数次幂。
四、字符串的Hash函数构造方法
字符串本身就可以看成一个256进制(ansistring为128进制)的大整数,因此我们可以利用直接取余法,在线性时间内直接算出Hash函数值。
为了保证效果,我们选择的进制仍然不能选择太接近2n的数;尤其是当我们把字符串看成一个2p进制数的时候,选择m=2p-1会使得该字符串的任意一个排列的Hash函数值都相同。
对于固定长度字符串模式匹配,Rabin-Karp设计了一个巧妙的hash算法。首先计算pattern的hash值,然后在从string的开头,计算相同长度字符串的hash值。若hash值相同,则表示匹配,若不同,则向右移动一位,计算新的hash值。
整个过程,与暴力的字符串匹配算法很相似,但由于计算hash值时,可以利用上一次的hash值,从而使新的hash值只需要加上新字母的计算,并减去上一次的第一个字母的计算,即可。这样相当于后面的每次匹配,只需要考虑一个新的字母,并减去一个老的字母,无疑极大的提高了效率——尤其是pattern的字符串很长的情况下。
那么这个hash是如何实现的呢?
hash(w[0 .. m-1])=(w[0]*2m-1+ w[1]*2m-2+···+ w[m-1]*20) mod q
where q is a large number.
Then, rehash(a,b,h)= ((h-a*2m-1)*2+b) mod q
上面给出这个hash的一个设计是当不匹配时,rehash为再次hash的值,a为上次的第一个字母,b为新的字母。
应用(假设进制位J,模为P,预处理F[i]位J的i次方模P的值,’A’=0):
- 已知H(“ABC”)求H(“ABCD”):H[“ABCD”]=(H[ “ABC”]*J%P+3)%P
2、两个字符串连接后A+B的hash值:
设H(A)=a,H(B)=b,则H(AB)=(a*F[len(B)]%P+b)%P //J表示进制,len(B)表示B串的长度
- 预处理出字符串S的所有前缀HASH值h[i],求S的任意字串H(l,r)的值
H(l,r)=(h[r]-h[l-1]*F(r-l+1)%P+P)%P
- 注意:
字符串哈希易冲突,建议再采用不同的进制J1,模P1,两个联合判断可减少冲突到忽略不计程度,见例题“好文章”
若只有大写或小写字母,建议:J=31/131,P=9997/70177 (都是质数)
五、排列的Hash函数
让排列与数1--A(m,n)之间建立一一对应的关系
从0到n!-1的任何自然数可唯一地表示为:
m=an-1(n-1)!+an-2(n-2)!+…+a11!
不妨设n个元素为1,2,..,n。对应的规则如下:
设序列(an-1 ,…, a1) 对应的某一排列p,其中ai可以看做是排列p中数i+1所在位置右边比i+1小的数的个数。
以排列4213为例,它是元素1,2,3,4的一个排列。4的右边比4小的数的数目为3,所以a3=3。3右边比3小的数的数目为0,即a2=0 。同理a1=1 。所以排列4213对应于变进制的301,也就是十进制的19;反过来也可以从19反推到301,再推到排列4213。
六、Hash函数的冲突
(1)冲突:两个不同的关键字,由于哈希函数值相同,因而被映射到表的同一位置上,这个现象叫做冲突(碰撞)。
(2)完全避免冲突的条件:
最理想的解决冲突的方法是完全避免冲突。要做到这一点必须满足两个条件:
①|U|≤m
②选择合适的散列函数
这仅适用于|U|较小,且关键字均事先已知的情况,此时经过精心设计散列函数h有可能完全避免冲突。
理论上是可以设计出一个几乎完美、没有冲突的哈希函数。然而,这样的函数设计浪费时间而且编码复杂,还不如用一个虽然冲突多一些但是编码简单的哈希函数。
(3)影响冲突的因素
冲突的频繁程度除了与hash函数h相关外,还与表的填满程度相关。
设m和n分别表示表长和表中填入的结点数,则将α=n/m定义为散列表的装填因子(Load Factor)。容易想象,α越大,表装得越满,冲突的机会也越大。特别当а>1时冲突是不可避免的,通常取α<1。
装填因子的大小要取得适当,使得既不过多地增加冲突,有较快的检索速度,也不浪费存储空间。
(4)处理冲突的方法基本上有两类:
a)拉链法
当发生冲突时就拉出一条链,建立一个链接方式的子表。若n个关键字映射到散列表的m个存储单元上,最多可以建立m个子表,冲突的关键字存放在以这m个单元为首结点链接的子表里。
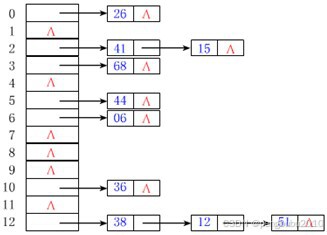
b)开放地址法
冲突发生时,使用某种探查技术在散列表中形成一个探查序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









