




 文章探讨了深度学习系统的鲁棒性测试问题,指出现有测试方法与模型鲁棒性关联有限。作者提出RobOT框架,通过量化测试用例的鲁棒性价值和模型收敛质量,有效提高模型对抗鲁棒性。实验结果显示,RobOT在多个基准数据集上显著提升了模型鲁棒性,对抗鲁棒性提升超过DeepGini。
文章探讨了深度学习系统的鲁棒性测试问题,指出现有测试方法与模型鲁棒性关联有限。作者提出RobOT框架,通过量化测试用例的鲁棒性价值和模型收敛质量,有效提高模型对抗鲁棒性。实验结果显示,RobOT在多个基准数据集上显著提升了模型鲁棒性,对抗鲁棒性提升超过DeepGini。
RobOT:深度学习系统的稳健性测试

摘要:
DL系统的对抗例子(又称bug)可以通过模糊或在某些测试指标的帮助下进行引导搜索来发现。然而,最近的研究表明,现有DL测试方法常用的神经元覆盖度量与模型鲁棒性无关。这也不是检验后对模型鲁棒性置信度的有效度量。作者提出了一种新的测试框架,称为面向鲁棒性测试(robust - oriented testing, RobOT),以弥补这一缺陷。RobOT的一个关键部分是定量衡量1)每个测试用例在提高模型鲁棒性方面的价值(通常是通过再训练),2)模型鲁棒性提高的收敛质量。RobOT利用所提出的度量自动生成测试用例,以提高模型的鲁棒性。提出的度量也是一个强大的指标,可以表明鲁棒性改进通过测试的收敛程度。在多个基准数据集上的实验验证了RobOT在提高DL模型鲁棒性方面的有效性和效率,对抗鲁棒性提高了67.02%,比目前最先进的DeepGini工作提高了50.65%。
介绍:
软件工程社区已经做出了显着的努力来减轻对抗性示例的威胁,并提高 DL 系统在存在对抗性示例时的鲁棒性。其中,形式验证旨在证明给定输入的附近不存在对抗性示例。使用抽象解释和可达性分析等方法已经取得了实质性进展。然而,形式验证技术通常很昂贵,并且只能扩展到有限的模型结构和属性(例如局部鲁棒性[17])。另一种流行的工作是深度学习测试,其目的是生成可以暴露 DL 模型漏洞的测试用例。然后可以使用测试用例通过重新训练模型来提高模型的鲁棒性,但是,这不应被视为理所当然,因为最近的研究表明,基于现有测试指标生成的测试用例与模型鲁棒性和鲁棒性改进的相关性有限。在这项工作中,我们强调并解决了有效生成测试用例以提高深度学习模型的对抗鲁棒性的问题。
测试深度学习系统有两个关键要素。第一个元素是用于评估测试用例或测试套件质量的测试指标。已经提出了多种测试指标,包括神经元覆盖、多粒度神经元覆盖率和意外充分性。第二个关键要素是测试用例生成所采用的方法,这通常是通过在测试指标的指导下操作给定的种子输入来完成的。现有的测试用例生成技术,如 DeepXplore 、DeepConcolic 、DeepHunter和 ADAPT 大多旨在改进神经元测试用例的覆盖率指标。虽然现有的测试方法在一定程度上有助于暴露深度学习系统的漏洞,但最近的研究发现神经元覆盖率指标对于提高模型的鲁棒性并无帮助。
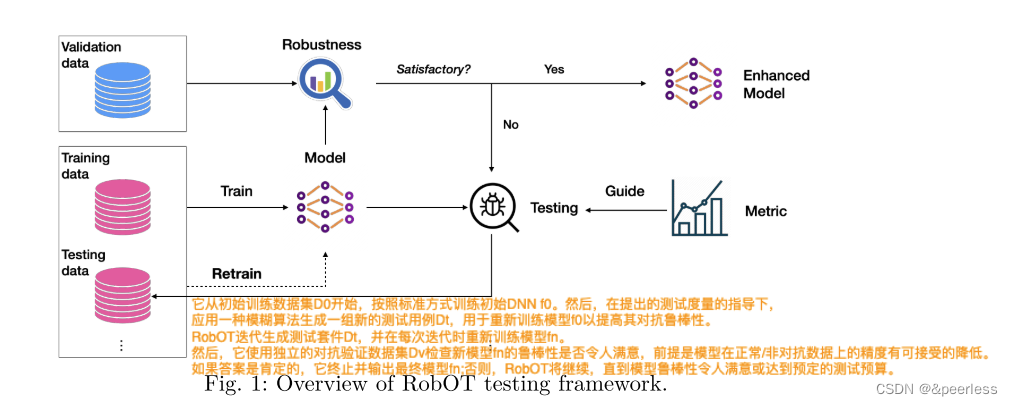
在这项工作中,通过提出一种名为 RobOT(即稳健性导向测试)的新型深度学习测试框架来解决现有深度学习测试方法的上述局限性,该框架将深度学习(重新)训练与测试集成在一起。如图1所示,RobOT在以下重要方面区别于现有的神经元覆盖引导测试工作。首先RobOT注重鲁棒性。 RobOT 将用户定义的模型鲁棒性要求作为输入,并将重新训练过程集成到测试流程中。 RobOT 通过基于测试指标生成测试用例并重新训练模型,迭代地提高模型的稳健性。其次,在 RobOT 中,我们提出了一组与模型鲁棒性密切相关的新颖的轻量级指标。这些指标可以定量地衡量每个测试用例与模型再训练的相关性,并且旨在支持能够显著提高模型鲁棒性的测试用例。
背景:
1、DNN的结构
2、覆盖引导的测试用例生成
与现有的覆盖引导测试工作不同,我们的目标是设计一个面向稳健性的测试框架,通过测试来提高深度学习模型的稳健性。有两个关键问题需要回答:1)如何设计与模型稳健性强相关的测试指标? 2)我们如何自动生成有利于建议的测试指标的测试用例?
直观上,测试指标的设计方式应使得在使用生成的测试用例进行重新训练后,可以提高模型的鲁棒性。该目标将测试指标与模型稳健性直接联系起来。
3、我们的目标是设计与模型健壮性密切相关的测试指标。我们注意到,在机器学习领域已经有一些努力来修改标准的训练过程,以获得一个更健壮的模型。例如,到目前为止最有效和最成功的方法是鲁棒训练(PGD),它在训练过程中加入了一个对手,这样训练后的模型可以通过在第一个位置上最小化对抗性例子的损失来实现鲁棒性。
鲁棒训练的核心是识别一个正常示例 x 周围的强(理想情况下最坏情况)对抗性示例 并训练模型,以便最大限度地减少强对抗性示例的损失。鲁棒训练在训练更鲁棒的模型方面显示出令人鼓舞的结果。这启发我们在如何生成测试用例(围绕正常示例)并使用测试用例重新训练模型以提高模型鲁棒性方面类似地考虑深度学习测试。关键的含义是,当我们设计面向稳健性的测试指标来指导测试时,我们应该从面向损失的角度评估测试用例的有用性。
让x0作为测试的种子。我们假设测试用例 xt 是在 x0 周围的邻域使用测试方法或对抗性攻击。主要的直觉是,引起更高损失的测试用例是更强的对抗性示例,因此对于训练鲁棒模型更有帮助。基于这种直觉,我们在损失之上提出了两个级别的测试指标,如下所示:
- 零阶损失(ZOL):第一个指标直接计算测试用例相对于深度学习模型的损失。形式上,给定一个测试用例 xt(从种子 x 生成)、一个 DL 模型 f,f 上 xt 的损失定义为:
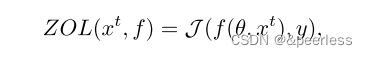 其中 y 是 x 的真实标签。对于相同种子生成的测试用例,我们更喜欢损失较高的测试用例,这更有利于通过再训练提高模型的鲁棒性。
其中 y 是 x 的真实标签。对于相同种子生成的测试用例,我们更喜欢损失较高的测试用例,这更有利于通过再训练提高模型的鲁棒性。 - 一阶损失(FOL):对于不同的种子,生成的测试用例的损失可能有很大不同。一般来说,在种子周围生成高损失的测试用例更容易,不幸的是,这些测试用例不能很好地概括。因此,ZOL无法统一衡量测试用例的价值。为了解决这个问题,我们提出了一个更细粒度的指标,它可以帮助我们衡量我们在种子邻域中实现最高损失的程度。直觉是,给定种子输入,如果我们按照梯度方向修改种子,则其周围的损失通常首先增加并最终收敛。因此,衡量损失收敛程度的标准可以作为测试指标。具有更好收敛质量的测试用例对应于比其邻居更高的损失。接下来,我们引入一阶平稳条件(FOSC)来测量生成的测试用例的损耗收敛质量。形式上,给定种子输入 x0,其邻域面积 X = {x| ||x − x0||p ≤ },以及测试用例 xt,xt 的 FOSC 值计算为:
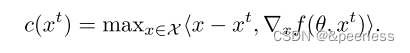
- 请注意,FOSC(在方程 6 和方程 7 中)计算起来很便宜,其主要成本是一次性梯度计算(所有深度学习框架都很容易获得)。 FOSC 值表示给定测试用例的一阶损失。如果 FOSC 值为零,则测试用例的损失收敛并达到最高值。因此,较小的 FOSC 值意味着较好的收敛质量和较高的损耗。
4、FOL指导测试用例选择:给定一组测试用例 Dt,我们引入两种基于 FOL 的策略来选择较小的集合 Ds ⊂ Dt 来重新训练模型,如下所示。令 Dt = [x1, x2, · · · , xm] 为按 FOL 值降序排列的列表,即,对于 i ∈ [1,m− 1],FOL(xi) ≥ FOL(xi+1)。
- K-Multisection Strategy (KM-ST):KM-ST的思想是对Dt的FOL空间进行均匀采样。算法。图2显示了细节。假设我们需要从Dt中选择n个测试用例。我们在第 3 行将 FOL 的范围等分为 k 个部分(KR)。然后对于每个范围 r ∈ KR,我们在第 5 行随机选择相同数量的测试用例。
- 双向策略(BE-ST): BE-ST的思想是通过平均组合具有小和大FOSC值的测试用例来形成D。该策略混合了强对抗强度和弱对抗强度的测试用例,其灵感来自于最近关于改进标准鲁棒训练的工作[21]。给定一个排序的 Dt,我们可以简单地从列表的两端取出相同数量的测试用例来组成 Ds。
5、FOL 引导模糊测试

实验:
鲁棒性评估:采用Def. 2对模型的鲁棒性进行了实证评估。在实践中,我们通过结合使用FGSM和PGD(每个10000)生成的对抗例子,为每个数据集构建一个对抗例子Dv的验证集。攻击参数与Tab相同。ii。然后通过计算模型在Dv上的精度来评估模型的鲁棒性。
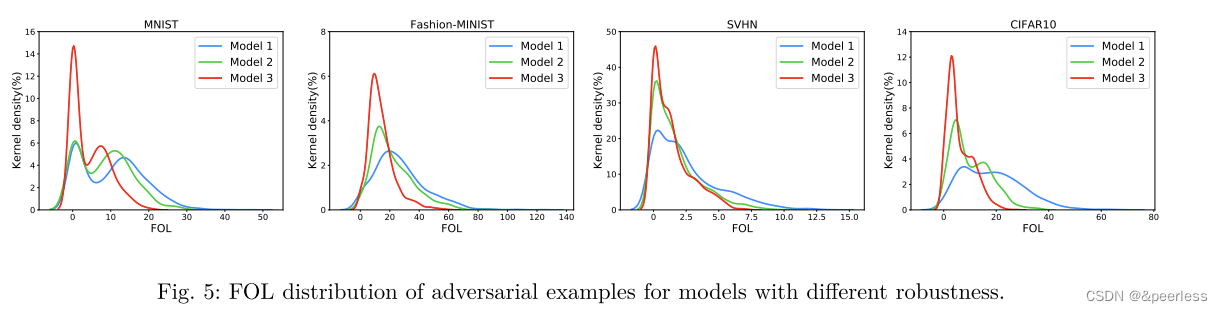
实验一:FOL度量标准和模型鲁棒性之间的关系是什么,首先为每个数据集选择三个具有不同稳健性级别的模型。第一个模型(模型1)是原始训练模型。第二个模型(模型2)是一个健壮性增强的模型,它通过增加5%的生成测试用例来重新训练2,并且比模型1更健壮。第三个模型(模型3)是一个健壮性增强模型,它通过增加10%的生成测试用例来重新训练,并且是最健壮的。然后,对每个模型进行对抗攻击,获得相同数量的对抗实例(FGSM为10000,PGD为10000)。
在图5中显示了不同模型对抗例子的FOL分布。我们观察到,在对抗例子的FOL分布和模型鲁棒性之间有很强的相关性。具体地说,更健壮模型的对抗性实例具有更小的FOL值。图5清楚地证明了这一点,即对于每个数据集,模型3(最健壮的模型)的概率密度集中分布在零附近,而模型2和模型1(模型1比模型2大)的概率密度则稳步扩大到更大的FOL值。其根本原因是,更健壮的模型通常具有更平坦的损失分布,因此FOL值更小(因为它是基于在损失梯度上)。
实验二:FOL度量标准对于测试用例的选择有多有效,首先使用不同的方法生成大量的测试用例,然后采用不同的测试用例选择策略(如BE-ST、KM-ST和DeepGini)来选择一个相同大小的测试用例子集来重新训练模型。如果用所选测试用例重新训练的模型更健壮,那么选择策略就会被认为更有效。
区分了两种不同类型的测试用例生成算法,它们都在文献中使用,即对抗攻击和神经元覆盖引导算法,以进行更细粒度的分析。对于对抗性攻击,我们采用FGSM(弱攻击)和PGD(强攻击)生成一组组合的测试用例。对于DeepXplore、DLFuzz和ADAPT,我们为它们各自生成了一组测试用例。
对于所有策略,重新训练的模型在一定程度上提高了对抗性示例的弹性。此外,随着我们增加更多的测试用例(从 1% 到 10%)进行再训练,模型的稳健性稳步提高。然而,我们也可以观察到,在几乎所有情况下(除了 1 例),我们的 FOL 引导策略(BE-ST 和 KMST)的性能明显优于 DeepGini,即达到 30.48%、84.62%、54.91% 和 35.92%四组不同的测试用例的平均鲁棒性提高更多。原因是FOL能够选择比DeepGini具有更高且更多样化的损失的测试用例(如图4所示),这与模型鲁棒性具有更好的相关性。同时,我们观察到重新训练的模型在测试集上也保持了高精度(如表 III 中总结)。

实验三:FOL 引导模糊测试算法的有效性和效率如何,将 FOL 引导模糊算法 (FOL-Fuzz) 与最先进的神经元覆盖引导模糊算法 ADAPT 进行比较,如下所示。我们运行 FOL-fuzz 和 ADAPT 相同的时间(即 5 分钟、10 分钟和 20 分钟)来生成测试用例。然后我们用测试用例重新训练模型,以比较它们的鲁棒性改进。
在相同的时间限制下,ADAPT生成的对抗性例子稍微多一些,即10457(取平均值),而FOLFuzz的为7897。仔细观察就会发现,ADAPT倾向于围绕一个种子生成大量测试用例,以改进神经元覆盖率度量。然而,并不是所有这些测试都对提高模型的稳健性有意义。另一方面,fl - fuzzy能够发现更有价值的测试用例。我们可以观察到,使用foll - fuzzed测试用例(虽然小于ADAPT)对模型进行再训练,模型的鲁棒性显著提高,平均为39.67%,而ADAPT为24.79%。


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







