



使用高效网络和数码相机对楮名日本纸张进行分类的初步研究
摘要
对纸张等历史文献进行无损分析在历史文化阐释中至关重要。因为可以通过造纸方法和纸张纤维成分等信息,揭示书籍来源的背景。本文提出一种基于EfficientNet‐B0的日本楮纸图像块分类方法。我们整合图像块分类结果,以估计整张纸中楮纤维的产地。结果表明,该方法在楮的产地二分类中的平均成功率达到93.1%,四类分类中达到87.5%。此外,通过将分类后的图像块在原始图像上重新排列位置生成重建图像,进一步评估了整张纸张的分类准确率。结果显示,尽管实验次数有限,所有宏观图像均能正确完成由整幅宏观图像构成的楮四个产地的分类。未来,我们将研究多尺度技术,以考虑从图像块重建的宏观图像中各图像块之间的纤维连续性。
关键词 :无损纸张分析,数字宏观摄影,EfficientNet-B0,深度卷积神经网络
I. 引言
历史文献的无损分析对于文化遗产等历史文化阐释至关重要。在此,我们以楮纸(Kōzo paper)等纸张类历史文献为对象,促进历史文化研究[1]。此外,纸张的无损分析可作为验证纸张信息一致性的手段。从纸张中获取的信息能有效提供书籍制作背景的相关线索,如造纸方法、产地、纤维成分和工艺。我们此前提出一种针对纸张的无损图像分析方法,该方法使用高分辨率数码相机获取图像,已实现对三种纤维——麻纤维、桑纤维和楮——基于数码相机获取的宏观图像中提取的图像块进行自动分类,准确率达到95.3%[2–3]。然而,该方法仅限于基于原始三种种类的纤维图像块分类。
对于纸张整体,由单一类纤维组成的纸张的图像块分类以估计整个宏观图像的产地尚未充分研究。
本研究使用能有效捕捉纹理、亮度和分辨率的高效网络‐B0[4],将由相同纤维——楮——组成的日本纸的图像块进行分类,分为四种楮的产地:越前楮、土佐楮、骏河楮和甲斐楮。之后,我们整合基于图像块分类的结果,以估计整张纸张中楮纤维的来源产地。
II. 方法

首先,我们使用了一张分辨率为5000×3000像素、以ISO 216标准执行的数码宏观图像,该图像由高分辨率数码相机(Olympus,TG-5)获取。图像块基于此前研究中提出的纸张纤维成分自动分类方法[2–3],通过纹理特征进行分类。
此时,原始图像被预处理为灰度图像,但在此研究中仍使用RGB图像通道的数码图像将图像分割为图像块。此外,由于此前研究相比,用于训练的图像数量较少,因此用于分类的网络从VGG-16调整为EfficientNet‐B0。
在此步骤中,将数码宏观图像分割为250×250像素图像块。此外,对每个图像块进行数据增强,包括旋转和镜像。采用了三种旋转角度——90°、180°和270°——以及两种镜像方式——水平和垂直镜像——使得数据量增强了八倍。我们使用在ImageNet上预训练的EfficientNet‐B0网络。利用该预训练网络,通过在EfficientNet‐B0网络上进行有限块重训练,实现由相同纤维组成的纸张分类。具体而言,对最后输出的八个块进行了重训练,包括一个1×1卷积层和批归一化块,以及四个3×3卷积块。超参数设置为训练轮数50,学习率1e-4,学习率为0.001,并使用Adam优化器。此外,计算了各产地的训练准确率,并将最高训练准确率的产地作为图像块的分类结果输出。
III. 实验
分别使用普通数码相机(Olympus,TG-5)对越前楮、土佐楮、骏河楮和甲斐楮各拍摄30张宏观图像,共计120张宏观图像作为样本图像。这些图像为在相同光照条件下拍摄的宏观图像,具有高亮度、自动对焦、18倍光学变焦。如前所述,针对5000×3000像素的原始图像生成了250×250像素的图像块。因此,每张宏观图像生成了192个图像块。用于训练、验证和测试的原始图像数量分别为8、3和3,以达到8:1:1的比例。此外,由于用于训练、验证和测试的图像块数量分别为15360、2304和2304,因此将训练图像数量乘以6,使训练、验证和测试的图像块数量分别增至110592、2304和2304。

随后,将从宏观图像生成的图像块分类到四个楮的产地中,以评估图像块的分类准确率。在本研究中,我们评估了四类分类(越前楮、土佐楮、骏河楮和甲斐楮)以及楮的产地之间的二分类的分类准确率。
然后,将图像块的分类结果进行整合,生成重建图像,并将其重新排列为分割前的原始图像形式。在本实验中,明确了图像块的分类准确率与整张纸张重建后分类准确率之间的关系。重建后整张纸张各图像块的训练准确率通过热力图进行表示。具体而言,使用Score-CAM [5],生成图像块的显著图,可可视化EfficientNet‐B0在分类过程中关注的位置。
IV. 结果
表I列出了使用来自四个不同产地的相同纤维楮纤维制成的日本纸对越前、土佐、骏河和甲斐楮进行二分类的结果;表II展示了四类分类的结果。楮纤维产地的分类准确率为二分类93.1%,四分类87.5%。
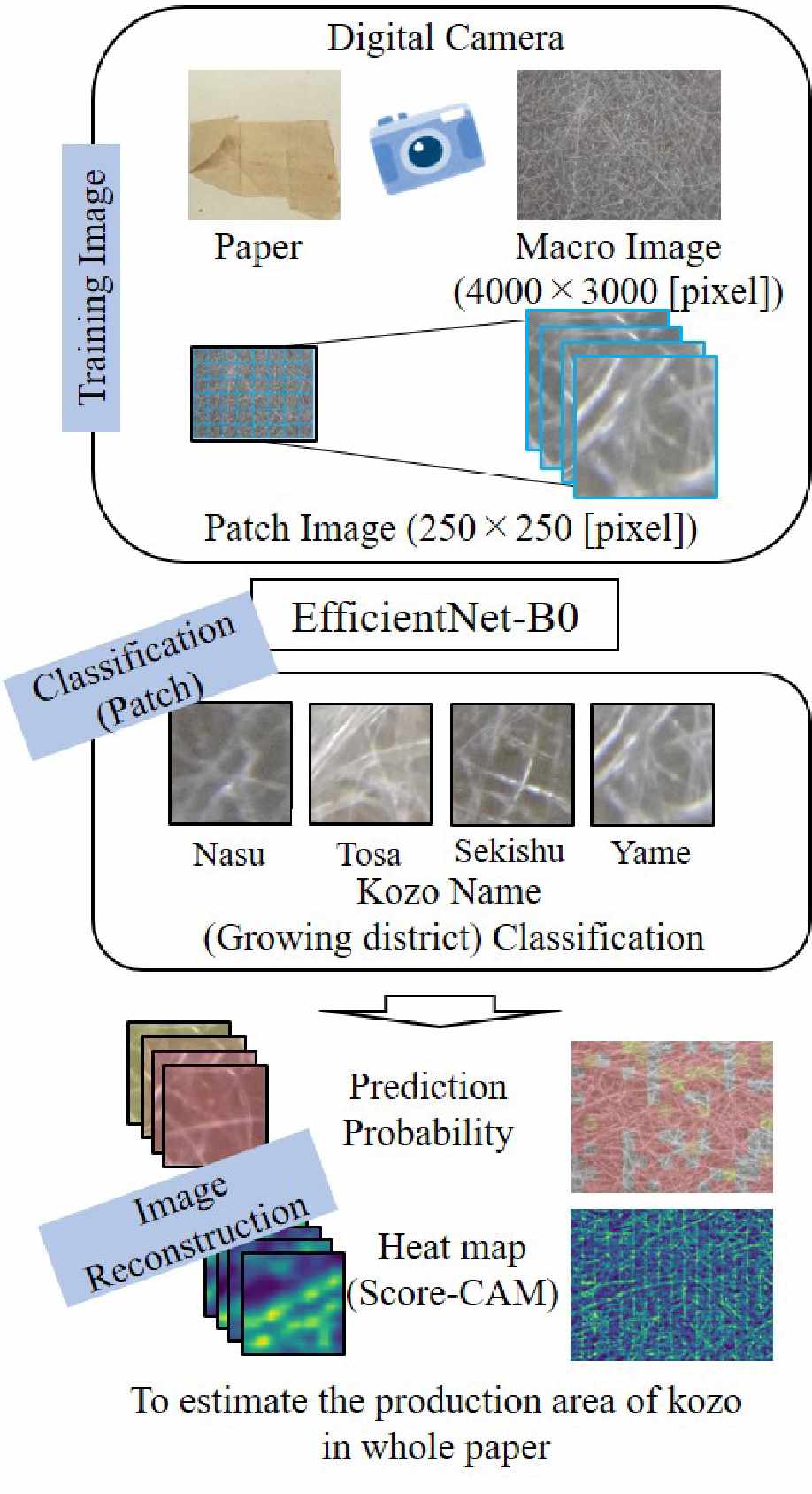
图2显示了一幅重建图像,其中图像块的分类准确率在图像上以30%透明度的热力图编码,并将其位置重新排列在原始图像上。图2 (A) 展示了越前楮的重建图像,其中未能分类的图像块数量较多,为576个中的151个(26.2%)。图2 (C) 展示了土佐楮的重建图像,其中未能分类的图像块数量极少,为576个中的2个(0.35%)。图2 (B-1) 显示了一个带有显著图的图像块重建图像,且被准确分类为越前楮。
此外,图2 (B-2) 至 (B-5) 显示了图像块分类中被错误分类为其他楮的结果;它们均为带有分类准确率热力图的重建图像。具体而言,对于图2中的原始图像,使用Score-CAM生成图像块的显著图;重建结果如图3所示。热力图颜色越深,表示卷积神经网络对该区域的关注度越高。
表I. 两类纸名分类的准确率
| 分类对 | 准确率 |
|---|---|
| 越前 vs 土佐 | 94.7% |
| 越前 vs 骏河 | 93.1% |
| 土佐 vs 骏河 | 98.8% |
| 越前 vs 甲斐 | 92.2% |
| 土佐 vs 甲斐 | 97.9% |
| 骏河 vs 甲斐 | 94.0% |
表II. 四种楮名之间的分类准确率
| 多类别分类任务 | 准确率 |
|---|---|
| 越前、土佐、骏河、甲斐 | 87.5% |

V. 讨论
在图2 (A) 的重建图像中,越前楮纸的宏观图像虽被正确分类为越前楮,其中被错误分类为土佐楮的图像块数量为12,骏河楮为2,甲斐楮为34,表明甲斐楮的误分类较多。然而,如图2 (B-1) 所示,在成功分类的图像块中,宏观图像中分类准确率超过60%的图像块占比为72.3%。因此,即使基于构成重建图像的多数图像块进行分类,仍可准确判定整个宏观图像中楮的产地。
在土佐楮的重建图像中,如图2 (C-1) 所示,未能分类的图像块数量极少,所有图像块均成功分类。此外,在验证所用的土佐楮日本纸生成的图像块中,仅有2个图像块未能分类,因此土佐楮的分类实现了高准确率。同样,在四种产地对楮进行的四类分类中,尽管实验次数有限,但在重建图像(即完整的宏观图像)中仍可对所有四类楮进行分类。
此后,我们考虑了使用越前楮、骏河楮和甲斐楮进行三分类,排除土佐楮。这是为了验证是否可通过优先对易于分类的土佐楮进行分类,再对剩余的楮进行分类,从而提高整体分类准确率。结果表明,排除土佐楮后,越前、骏河和甲斐楮图像块的准确率为82.7%,低于表II中四类分类的87.5%准确率。相反,基于四分类的结果,探讨了在三分类中使用重建图像进行分类的可能性。图4展示了骏河楮在四分类和三分类中的重建图像。
在构成重建图像的576个图像块中,41个(7.5%)在四类分类中未能成功分类,23个(3.9%)在三分类中未能成功分类。因此,尽管三分类的整体分类准确率低于四分类,但骏河楮的未成功分类图像块数量有所减少。此外,可以确认在三分类中成功分类的图像块在四分类中具有更高的分类准确率。因此,我们建议可通过优先对高准确率可分类的楮进行分类,再对剩余的楮进行分类,从而提高整体分类准确率。通过合理组织分类顺序,可能更可靠地判定重建图像中楮的产地。
此外,对Score-CAM生成的显著图进行了可视化评估,如图3所示。该显著图对比了分类置信度较高的越前楮(576个中有151个,即26.2%)和分类置信度较低的土佐楮(576个中有2个,即0.35%)。在显著图中,越前楮和土佐楮的纤维走向在各个图像块中均呈现高响应,表明在整个纸张中均可观察到纤维走向的连续性。因此,在EfficientNet‐B0的初始层中,本研究所关注的纤维区域得到了准确关联。然而,相较于土佐楮的显著图,在位于中间位置的图像块中,越前楮的显著图显示出相邻图像块之间同一纤维走向的连续性更为明显。因此,未来有必要在使用重建图像进行分类时,结合多尺度技术,考虑图像块间纤维走向的连续性。
VI. 结论
本文中,我们提出了一种使用EfficientNet‐B0对日本楮纸进行分类的方法。我们提出了一种通过重建分类后的图像块来估计纸张中所用楮的来源的方法。结果表明,在楮产地的二分类中,平均成功率达到93.1%。特别是对土佐楮和骏河楮的分类,成功率达到97.7%。四类分类的平均成功率为87.5%。此外,通过将分类后重新排列位置的重建图像与原始图像对比,评估了整张纸张的分类准确率。因此,尽管实验数量有限,所有宏观图像中的四类楮产地均得以成功分类。本研究针对四种产地对楮进行分类,且可视为分析由单一纤维组成的纸张的重要技术。
未来,我们将研究多尺度技术,以考虑通过Score-CAM揭示的图像块在重建宏观图像中的纤维连续性。


















 3239
3239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









