






点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
野火烧不尽,春风吹又生。
大家好,我是Python进阶者。
一、前言
前几天在帮助粉丝解决问题的时候,遇到一个简单的小需求,这里拿出来跟大家一起分享,后面再次遇到的时候,可以从这里得到灵感。昨天给大家分享了使用Python批量筛选上千个Excel文件中的某一行数据并另存为新Excel文件(上篇),今天继续给大家分享下篇。
二、需求澄清
需求澄清这里不再赘述了,感兴趣的小伙伴请看上篇。
三、实现过程
这里的思路和上篇稍微有点不同。鉴于文件夹下的Excel格式都是一致的,这里实现的思路是先将所有的Excel进行合并,之后再来筛选,也是可以的。
关于Excel进行合并,之前的写的文章已经好几篇了,大家如果感兴趣的话,也可以前往查阅。手把手教你4种方法用Python批量实现多Excel多Sheet合并、盘点4种使用Python批量合并同一文件夹内所有子文件夹下的Excel文件内所有Sheet数据、补充篇:盘点6种使用Python批量合并同一文件夹内所有子文件夹下的Excel文件内所有Sheet数据、手把手教你用Python批量实现文件夹下所有Excel文件的第二张表合并。
这里给出【小小明】大佬的一个合并代码,如下所示:
import pandas as pd
result = []
path = r"./新建文件夹"
for root, dirs, files in os.walk(path, topdown=False):
for name in files:
if name.endswith(".xls") or name.endswith(".xlsx"):
df = pd.read_excel(os.path.join(root, name))
result.append(df)
df = pd.concat(result)
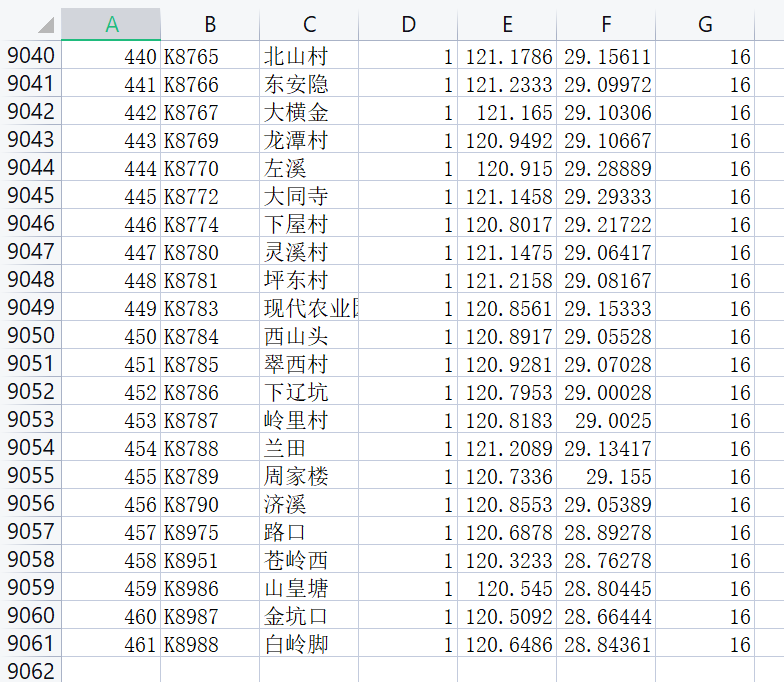
df.to_excel("hebing.xlsx", index=False)之后可以看到合并的后的数据如下图所示:
现在就可以针对合并后的数据进行筛选了,代码和上篇一样的,如下所示:
# import os
import pandas as pd
df = pd.read_excel("hebing.xlsx")
df1 = df[df['id'] == '58666']
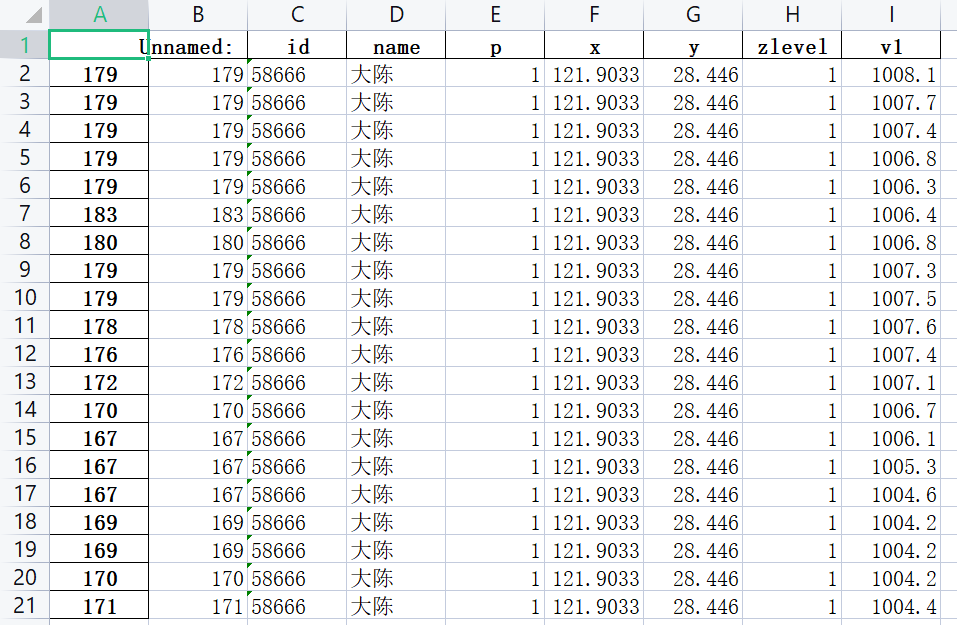
df1.to_excel('res.xlsx')最后实现的效果如下图所示:
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点一个Python自动化办公的实用案例,这个案例可以适用于实际工作中文件处理,大家也可以稍微改进下,用于自己的实际工作中去,举一反三。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









