








作者信息
网站
https://jianbojiao.com/
代码信息
https://bitbucket.org/JianboJiao/ldid/src/master/
具体的 模型代码:
https://bitbucket.org/JianboJiao/ldid/src/master/model.py
关键词
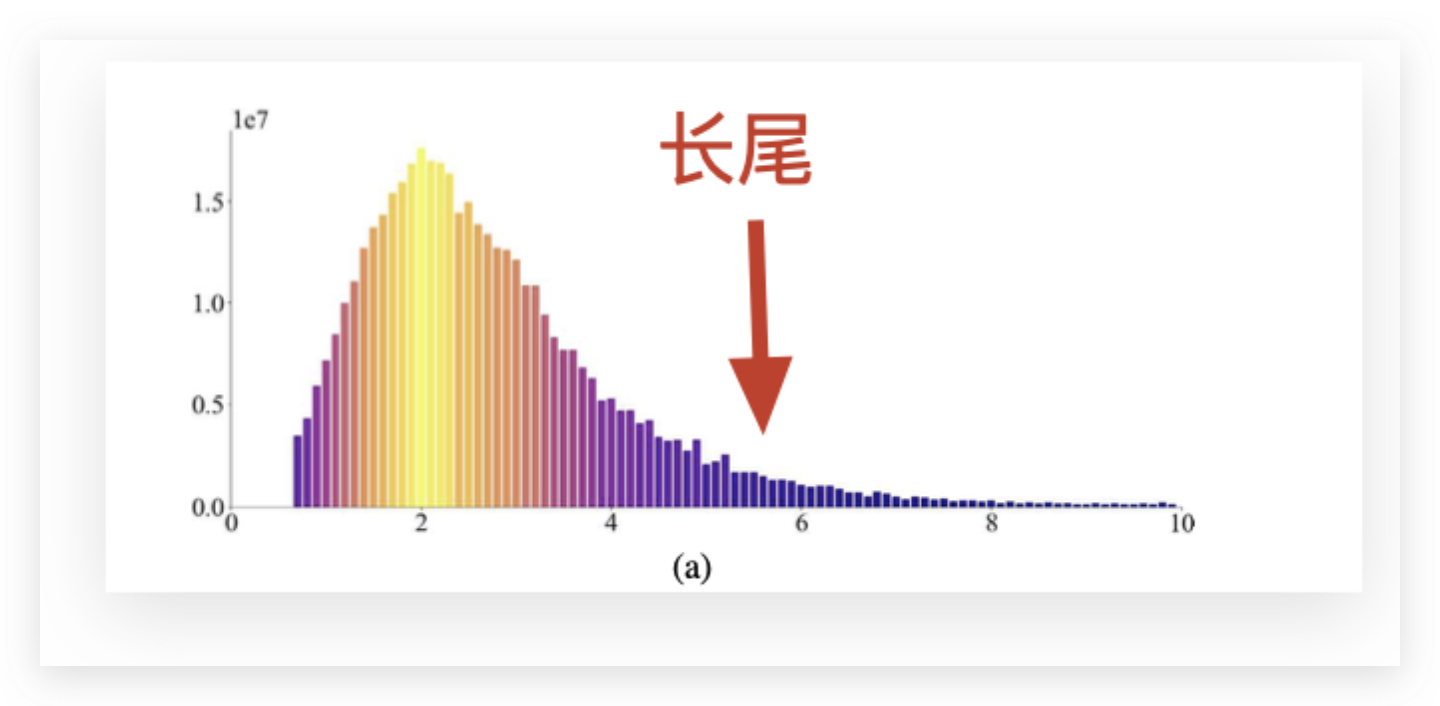
长尾:有很长的尾巴,这个意思;这就是文章再说的数据不平衡:data imbalance
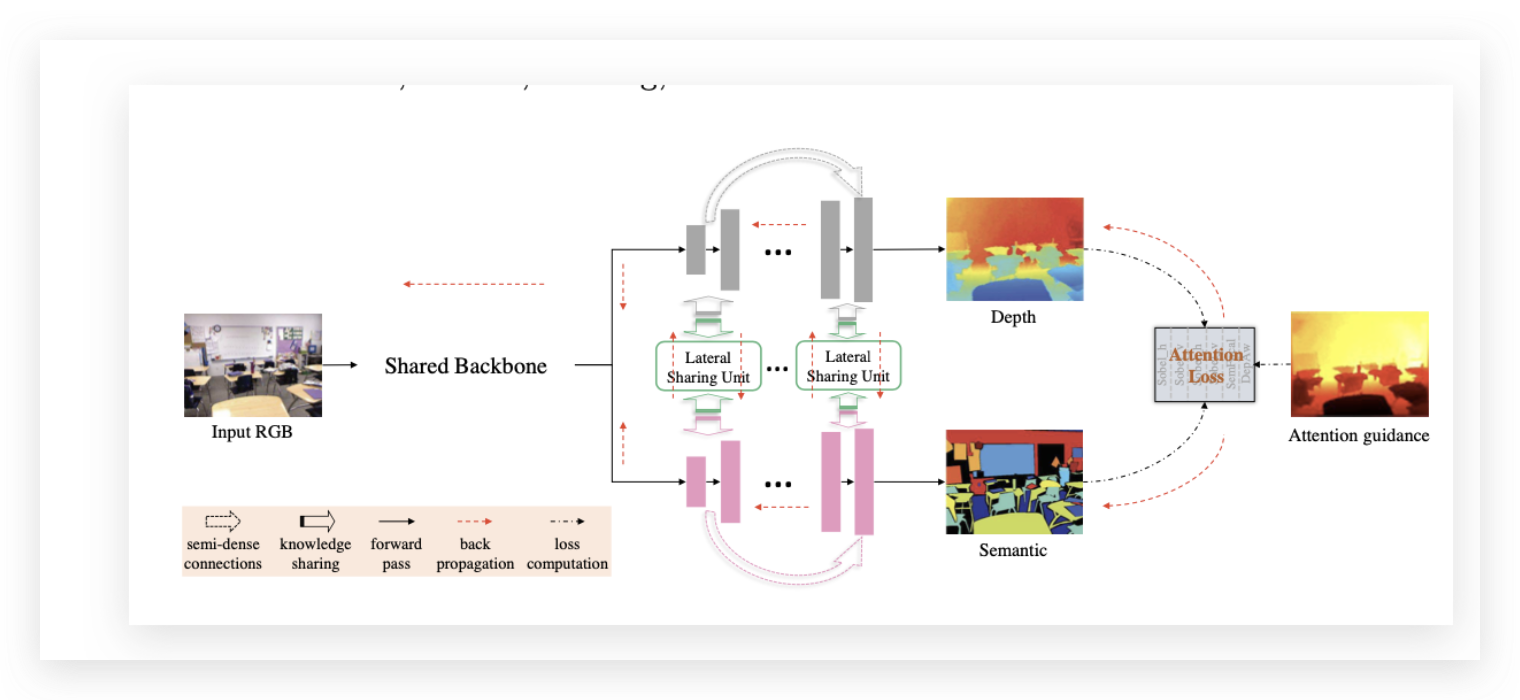
注意力驱动的损失函数;还是监督的
有两个任务:深度预测和语义标注任务,可以相互促进
SOTA 性能: state of the art ,牛逼的意思
这篇文章针对的问题: 使用朴素损失均等对待所有区域的像素,这会造成小深度值的像素,对损失函数的影响占据主导地位,进而,使得模型无法有效预测远距离物体的深度
协同网络中,用信息传播策略,以动态路由的形式,共享了标签信息给深度估计网络。
联合表征共享:不同任务之间的表征共享
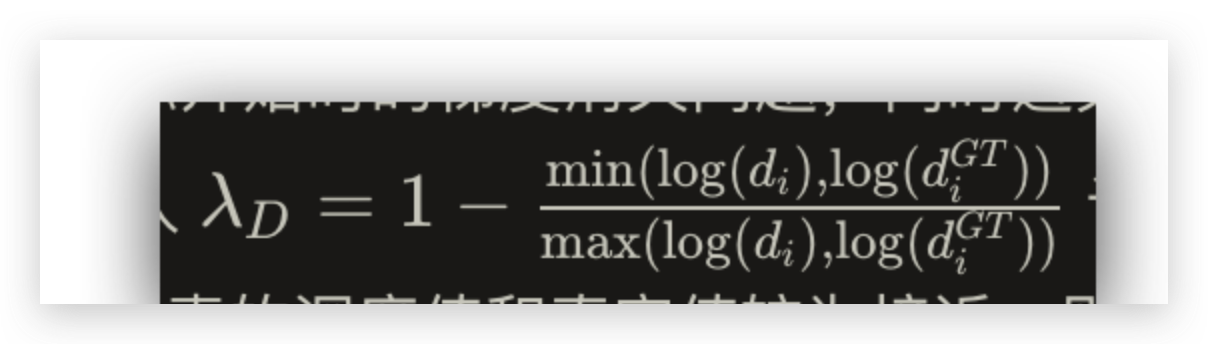
对于深度,具有一个 跟距离成正比 的 loss 函数,称为 depth aware loss function
L D A = 1 N ∑ i = 1 N ( α D + λ D ) ⋅ l ( d i , d i G T ) L L_{DA}=\frac 1 N \sum_{i=1}^{N}(\alpha_D+\lambda_D)\cdot \mathit l(d_i,d_i^{GT})L LDA=N1∑i=1N(αD+λD)⋅l(di,diGT)L
网络架构
侧向共享单元 LSU(Lateral Sharing Unit)
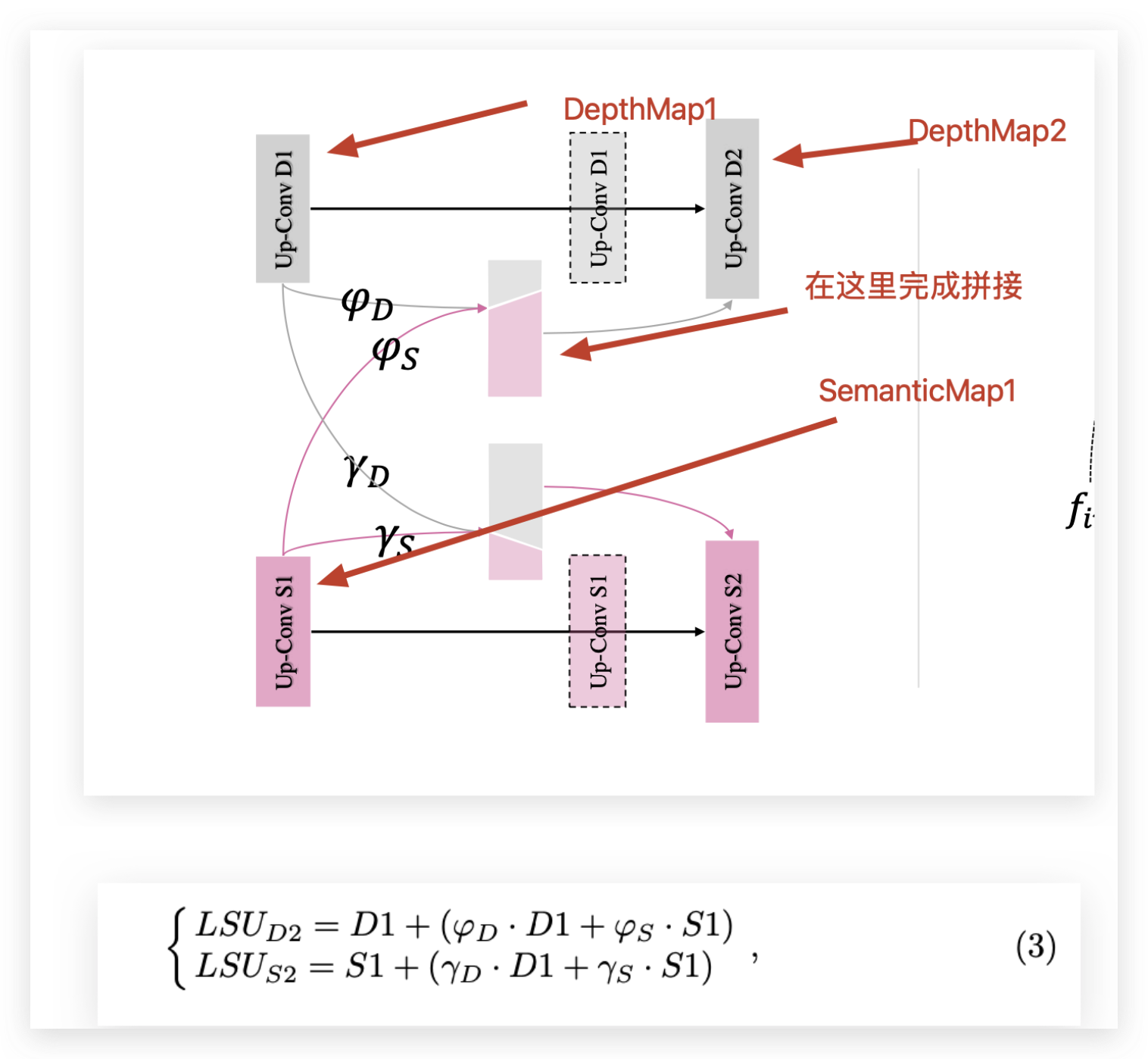
intra-task : 内任务;
3公式里面的 D1 和S1 保留着,就是保留着identity mappings;这会让内任务的信息传播得到保证,这个保证也意味着,自己的内任务不会被任务间的信息共享所污染/覆盖。
Semi-dense Up-skip Connections (SUCs)
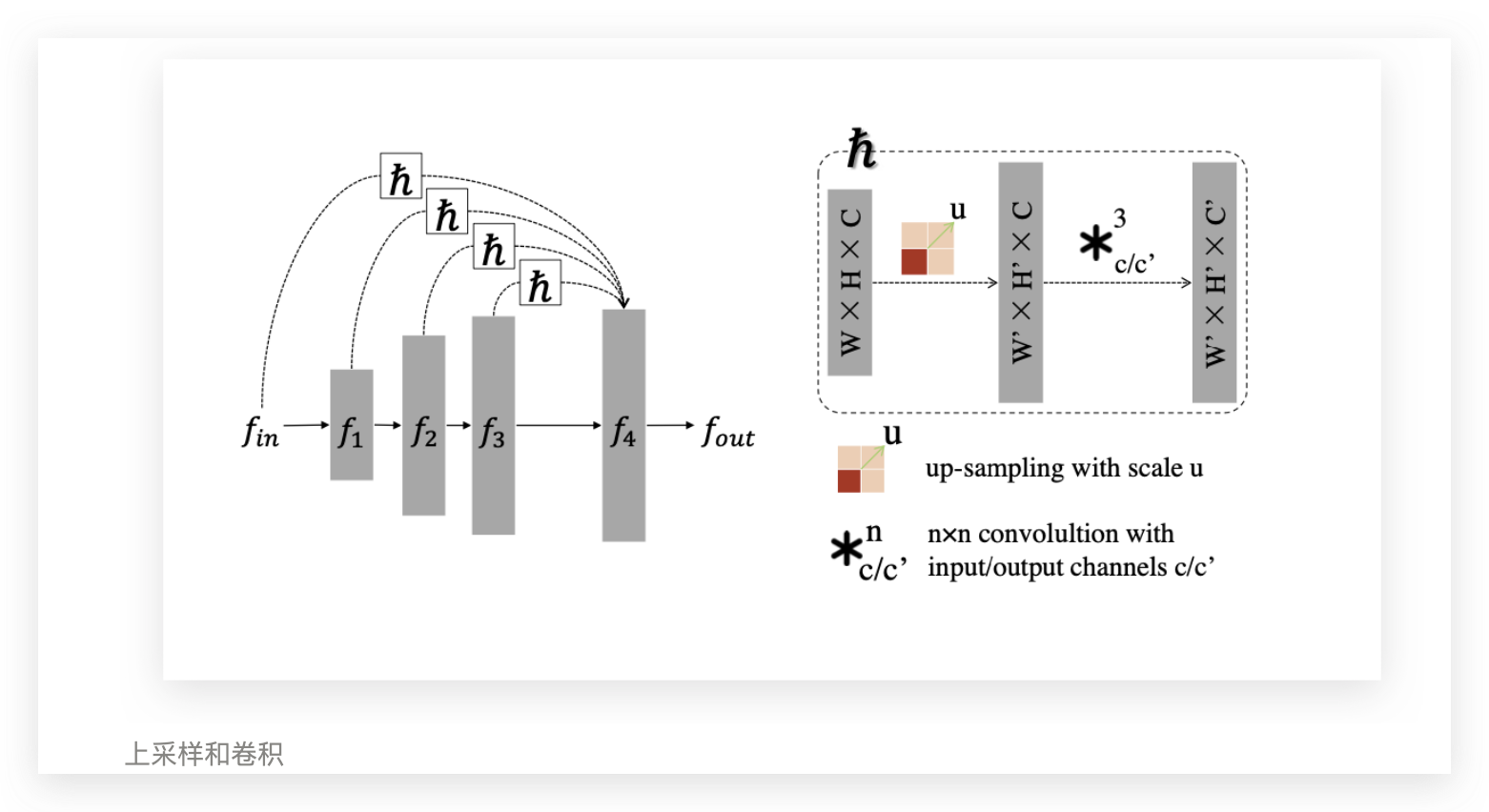
公式如下:
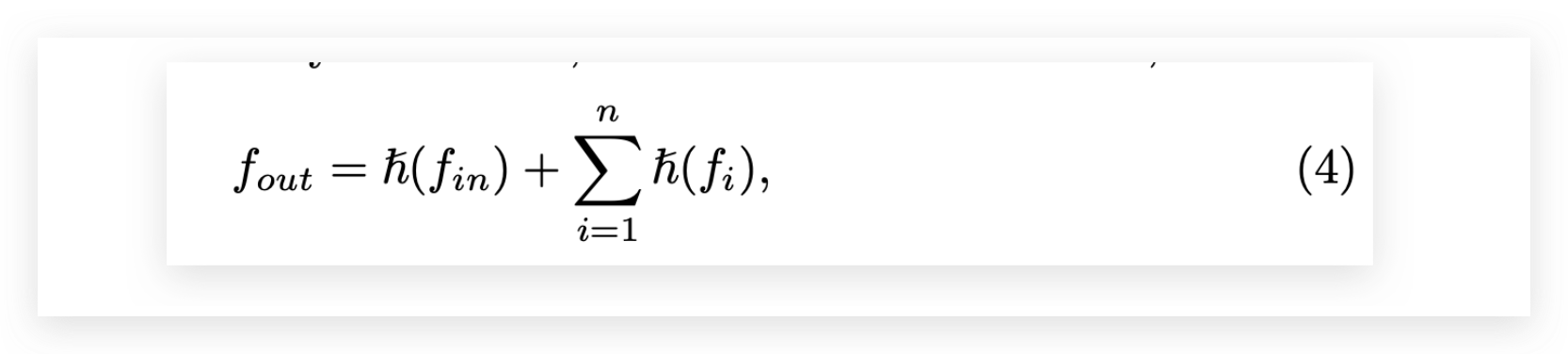
suc 的好处是 ,比 fully dense 的 encoder 架构,就是节省内存,性能上有提升。同时存在 一些 长短的隔层连接,会发生一个奇妙的事情:会观察到 global & local 的信息,有助于 网络 从 coarse to fine 的效果提升。
loss
第一个:


第二个:

第三那个:

总的loss
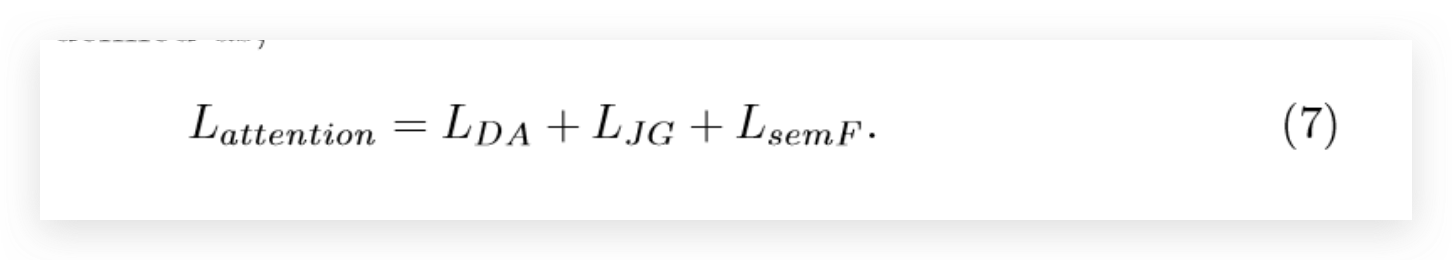
比我写的更好的文章
https://blog.youkuaiyun.com/kingsleyluoxin/article/details/108378019
代码部分
from: https://bitbucket.org/JianboJiao/ldid/annotate/master/model.py?at=master
# Model implementation in PyTorch
import torch
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
##########################################
class ResidualBlock(nn.Module):
def __init__(self, in_channels, d1, d2, skip=False, stride = 1):
super(ResidualBlock, self).__init__()
self.skip = skip
self.conv1 = nn.Conv2d(in_channels, d1, 1, stride = stride,bias = False)
self.bn1 = nn.BatchNorm2d(d1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(d1, d1, 3, padding = 1,bias = False)
self.bn2 = nn.BatchNorm2d(d1)
self.conv3 = nn.Conv2d(d1, d2, 1,bias = False)
self.bn3 = nn.BatchNorm2d(d2)
if not self.skip:
self.conv4 = nn.Conv2d(in_channels, d2, 1, stride=stride,bias = False)
self.bn4 = nn.BatchNorm2d(d2)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.skip:
residual = x
else:
residual = self.conv4(x)
residual = self.bn4(residual)
out += residual
out = self.relu(out)
return out
# 上投影 block,没用到?
class UpProj_Block(nn.Module):
def __init__(self, in_channels, out_channels, batch_size):
super(UpProj_Block, self).__init__()
self.batch_size = batch_size
self.conv1 = nn.Conv2d(in_channels, out_channels, (3,3))
self.conv2 = nn.Conv2d(in_channels, out_channels, (2,3))
self.conv3 = nn.Conv2d(in_channels, out_channels, (3,2))
self.conv4 = nn.Conv2d(in_channels, out_channels, (2,2))
self.conv5 = nn.Conv2d(in_channels, out_channels, (3,3))
self.conv6 = nn.Conv2d(in_channels, out_channels, (2,3))
self.conv7 = nn.Conv2d(in_channels, out_channels, (3,2))
self.conv8 = nn.Conv2d(in_channels, out_channels, (2,2))
self.bn1_1 = nn.BatchNorm2d(out_channels)
self.bn1_2 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv9 = nn.Conv2d(out_channels, out_channels , 3,padding = 1)
def prepare_indices(self, before, row, col, after, dims):
x0, x1, x2, x3 = np.meshgrid(before, row, col, after)
dtype = torch.cuda.FloatTensor
x_0 = torch.from_numpy(x0.reshape([-1]))
x_1 = torch.from_numpy(x1.reshape([-1]))
x_2 = torch.from_numpy(x2.reshape([-1]))
x_3 = torch.from_numpy(x3.reshape([-1]))
linear_indices = x_3 + dims[3] * x_2 + 2 * dims[2] * dims[3] * x_0 * 2 * dims[1] + 2 * dims[2] * dims[3] * x_1
linear_indices_int = linear_indices.int()
return linear_indices_int
def forward(self, x, BN=True):
out1 = self.unpool_as_conv(x, id=1)
out1 = self.conv9(out1)
if BN:
out1 = self.bn2(out1)
out2 = self.unpool_as_conv(x, ReLU=False, id=2)
out = out1+out2
out = self.relu(out)
return out
def unpool_as_conv(self, x, BN=True, ReLU=True, id=1):
if(id==1):
out1 = self.conv1(torch.nn.functional.pad(x,(1,1,1,1)))
out2 = self.conv2(torch.nn.functional.pad(x,(1,1,1,0)))
out3 = self.conv3(torch.nn.functional.pad(x,(1,0,1,1)))
out4 = self.conv4(torch.nn.functional.pad(x,(1,0,1,0)))
else:
out1 = self.conv5(torch.nn.functional.pad(x,(1,1,1,1)))
out2 = self.conv6(torch.nn.functional.pad(x,(1,1,1,0)))
out3 = self.conv7(torch.nn.functional.pad(x,(1,0,1,1)))
out4 = self.conv8(torch.nn.functional.pad(x,(1,0,1,0)))
out1 = out1.permute(0,2,3,1)
out2 = out2.permute(0,2,3,1)
out3 = out3.permute(0,2,3,1)
out4 = out4.permute(0,2,3,1)
dims = out1.size()
dim1 = dims[1] * 2
dim2 = dims[2] * 2
A_row_indices = range(0, dim1, 2)
A_col_indices = range(0, dim2, 2)
B_row_indices = range(1, dim1, 2)
B_col_indices = range(0, dim2, 2)
C_row_indices = range(0, dim1, 2)
C_col_indices = range(1, dim2, 2)
D_row_indices = range(1, dim1, 2)
D_col_indices = range(1, dim2, 2)
all_indices_before = range(int(self.batch_size))
all_indices_after = range(dims[3])
A_linear_indices = self.prepare_indices(all_indices_before, A_row_indices, A_col_indices, all_indices_after, dims)
B_linear_indices = self.prepare_indices(all_indices_before, B_row_indices, B_col_indices, all_indices_after, dims)
C_linear_indices = self.prepare_indices(all_indices_before, C_row_indices, C_col_indices, all_indices_after, dims)
D_linear_indices = self.prepare_indices(all_indices_before, D_row_indices, D_col_indices, all_indices_after, dims)
A_flat = (out1.permute(1, 0, 2, 3)).contiguous().view(-1)
B_flat = (out2.permute(1, 0, 2, 3)).contiguous().view(-1)
C_flat = (out3.permute(1, 0, 2, 3)).contiguous().view(-1)
D_flat = (out4.permute(1, 0, 2, 3)).contiguous().view(-1)
size_ = A_linear_indices.size()[0] + B_linear_indices.size()[0]+C_linear_indices.size()[0]+D_linear_indices.size()[0]
Y_flat = torch.cuda.FloatTensor(size_).zero_()
Y_flat.scatter_(0, A_linear_indices.type(torch.cuda.LongTensor).squeeze(),A_flat.data)
Y_flat.scatter_(0, B_linear_indices.type(torch.cuda.LongTensor).squeeze(),B_flat.data)
Y_flat.scatter_(0, C_linear_indices.type(torch.cuda.LongTensor).squeeze(),C_flat.data)
Y_flat.scatter_(0, D_linear_indices.type(torch.cuda.LongTensor).squeeze(),D_flat.data)
Y = Y_flat.view(-1, dim1, dim2, dims[3])
Y=Variable(Y.permute(0,3,1,2))
Y=Y.contiguous()
if(id==1):
if BN:
Y = self.bn1_1(Y)
else:
if BN:
Y = self.bn1_2(Y)
if ReLU:
Y = self.relu(Y)
return Y
# 就是封装了一个 扩大 size 的conv layer
class SkipUp(nn.Module):
def __init__(self, in_size, out_size, scale):
super(SkipUp,self).__init__()
self.unpool = nn.Upsample(scale_factor=scale,mode='bilinear')
self.conv = nn.Conv2d(in_size,out_size,3,1,1)
# 没用到:
self.conv2 = nn.Conv2d(out_size,out_size,3,1,1)
def forward(self,inputs):
outputs = self.unpool(inputs)
outputs = self.conv(outputs)
# outputs = self.conv2(outputs)
return outputs
##########################################
class Model(nn.Module):
def __init__(self, block1, block2, batch_size):
super(Model, self).__init__()
self.batch_size=batch_size
# Layers for Backbone 骨干网络,第一阶段
self.conv1 = nn.Conv2d(3, 64, kernel_size = 7, stride=2, padding=4)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.max_pool = nn.MaxPool2d(3,stride=2)
# (self, block, in_channels, d1, d2, stride = 1, pad=0):
self.proj_layer1 = self.make_proj_layer(block1, 64 , d1 = 64, d2 = 256, stride = 1)
self.skip_layer1_1 = self.make_skip_layer(block1, 256, d1 = 64, d2 = 256, stride=1)
self.skip_layer1_2 = self.make_skip_layer(block1, 256, d1 = 64, d2 = 256, stride=1)
self.proj_layer2 = self.make_proj_layer(block1, 256 , d1 = 128, d2 = 512, stride = 2)
self.skip_layer2_1 = self.make_skip_layer(block1, 512, d1 = 128, d2 = 512)
self.skip_layer2_2 = self.make_skip_layer(block1, 512, d1 = 128, d2 = 512)
self.skip_layer2_3 = self.make_skip_layer(block1, 512, d1 = 128, d2 = 512)
self.proj_layer3 = self.make_proj_layer(block1, 512 , d1 = 256, d2 = 1024, stride=2)
self.skip_layer3_1 = self.make_skip_layer(block1, 1024, d1 = 256, d2 = 1024)
self.skip_layer3_2 = self.make_skip_layer(block1, 1024, d1 = 256, d2 = 1024)
self.skip_layer3_3 = self.make_skip_layer(block1, 1024, d1 = 256, d2 = 1024)
self.skip_layer3_4 = self.make_skip_layer(block1, 1024, d1 = 256, d2 = 1024)
self.skip_layer3_5 = self.make_skip_layer(block1, 1024, d1 = 256, d2 = 1024)
self.proj_layer4 = self.make_proj_layer(block1, 1024 , d1 = 512, d2 = 2048, stride=2)
self.skip_layer4_1 = self.make_skip_layer(block1, 2048, d1 = 512, d2 = 2048)
self.skip_layer4_2 = self.make_skip_layer(block1, 2048, d1 = 512, d2 = 2048)
self.conv2 = nn.Conv2d(2048,1024,1)
self.bn2 = nn.BatchNorm2d(1024)
#depth 深度网络
self.dep_up_conv1 = self.make_up_conv_layer(block2, 1024, 512, self.batch_size)
self.dep_up_conv2 = self.make_up_conv_layer(block2, 512, 256, self.batch_size)
self.dep_up_conv3 = self.make_up_conv_layer(block2, 256, 128, self.batch_size)
self.dep_up_conv4 = self.make_up_conv_layer(block2, 128, 64, self.batch_size)
self.dep_skip_up1 = SkipUp(512,64,8)
self.dep_skip_up2 = SkipUp(256,64,4)
self.dep_skip_up3 = SkipUp(128,64,2)
self.dep_conv3 = nn.Conv2d(64,1,3, padding=1)#64,1
#self.upsample = nn.UpsamplingBilinear2d(size = (480,640))
self.upsample = nn.Upsample(size = (480,640),mode='bilinear')
#sem 语义网络
self.sem_up_conv1 = self.make_up_conv_layer(block2, 1024, 512, self.batch_size)
self.sem_up_conv2 = self.make_up_conv_layer(block2, 512, 256, self.batch_size)
self.sem_up_conv3 = self.make_up_conv_layer(block2, 256, 128, self.batch_size)
self.sem_up_conv4 = self.make_up_conv_layer(block2, 128, 64, self.batch_size)
self.sem_skip_up1 = SkipUp(512,64,8)
self.sem_skip_up2 = SkipUp(256,64,4)
self.sem_skip_up3 = SkipUp(128,64,2)
self.sem_conv3 = nn.Conv2d(64,41,3, padding=1)#64,1
# LSU 侧向共享单元
self.LS_d11=nn.Conv2d(512,512,1)
self.LS_s11=nn.Conv2d(512,512,1)
self.LS_d12=nn.Conv2d(512,512,1)
self.LS_s12=nn.Conv2d(512,512,1)
self.LS_d21=nn.Conv2d(256,256,1)
self.LS_s21=nn.Conv2d(256,256,1)
self.LS_d22=nn.Conv2d(256,256,1)
self.LS_s22=nn.Conv2d(256,256,1)
self.LS_d31=nn.Conv2d(128,128,1)
self.LS_s31=nn.Conv2d(128,128,1)
self.LS_d32=nn.Conv2d(128,128,1)
self.LS_s32=nn.Conv2d(128,128,1)
def make_proj_layer(self, block, in_channels, d1, d2, stride = 1, pad=0):
return block(in_channels, d1, d2, skip=False, stride = stride)
def make_skip_layer(self, block, in_channels, d1, d2, stride=1, pad=0):
return block(in_channels, d1, d2, skip=True, stride=stride)
def make_up_conv_layer(self, block, in_channels, out_channels, batch_size):
return block(in_channels, out_channels, batch_size)
def forward(self,x_1):
# 骨干网络流程
out_1 = self.conv1(x_1)
out_1 = self.bn1(out_1)
out_1 = self.relu(out_1)
out_1 = self.max_pool(out_1)
out_1 = self.proj_layer1(out_1)
out_1 = self.skip_layer1_1(out_1)
out_1 = self.skip_layer1_2(out_1)
out_1 = self.proj_layer2(out_1)
out_1 = self.skip_layer2_1(out_1)
out_1 = self.skip_layer2_2(out_1)
out_1 = self.skip_layer2_3(out_1)
out_1 = self.proj_layer3(out_1)
out_1 = self.skip_layer3_1(out_1)
out_1 = self.skip_layer3_2(out_1)
out_1 = self.skip_layer3_3(out_1)
out_1 = self.skip_layer3_4(out_1)
out_1 = self.skip_layer3_5(out_1)
out_1 = self.proj_layer4(out_1)
out_1 = self.skip_layer4_1(out_1)
out_1 = self.skip_layer4_2(out_1)
out_1 = self.conv2(out_1)
out_1 = self.bn2(out_1)
#Upconv section
# 制作两个任务网络流程,同时制作 LSU 链接结构
# LSU 链接结构 第一部分
#Depth Prediction Branch 深度预测分支
dep_out_1up1 = self.dep_up_conv1(out_1)
# 语义预测 分支
sem_out_1up1 = self.sem_up_conv1(out_1)
# 这就是 LSU 的公式
LS_dep_out_1up1=dep_out_1up1+self.LS_d11(dep_out_1up1)+self.LS_s11(sem_out_1up1)
LS_sem_out_1up1=sem_out_1up1+self.LS_s12(sem_out_1up1)+self.LS_d12(dep_out_1up1)
# LSU 链接结构 第二部分
dep_out_1up2 = self.dep_up_conv2(LS_dep_out_1up1)
sem_out_1up2 = self.sem_up_conv2(LS_sem_out_1up1)
LS_dep_out_1up2=dep_out_1up2+self.LS_d21(dep_out_1up2)+self.LS_s21(sem_out_1up2)
LS_sem_out_1up2=sem_out_1up2+self.LS_s22(sem_out_1up2)+self.LS_d22(dep_out_1up2)
# LSU 链接结构 第三部分
dep_out_1up3 = self.dep_up_conv3(LS_dep_out_1up2)
sem_out_1up3 = self.sem_up_conv3(LS_sem_out_1up2)
LS_dep_out_1up3=dep_out_1up3+self.LS_d31(dep_out_1up3)+self.LS_s31(sem_out_1up3)
LS_sem_out_1up3=sem_out_1up3+self.LS_s32(sem_out_1up3)+self.LS_d32(dep_out_1up3)
# 经过3 个LSU 共享信息处理后 的 深度输出 和 语义输出
dep_out_1 = self.dep_up_conv4(LS_dep_out_1up3)
sem_out_1 = self.sem_up_conv4(LS_sem_out_1up3)
# 这是 SUC: semi-dense up-skip connection
# depth的 SUC
dep_skipup1=self.dep_skip_up1(dep_out_1up1)
dep_skipup2=self.dep_skip_up2(dep_out_1up2)
dep_skipup3=self.dep_skip_up3(dep_out_1up3)
dep_out_1=dep_out_1 + dep_skipup1 + dep_skipup2 + dep_skipup3
dep_out_1 = self.dep_conv3(dep_out_1)
dep_out_1 = self.upsample(dep_out_1)
# semantic 的 SUC
sem_skipup1=self.sem_skip_up1(sem_out_1up1)
sem_skipup2=self.sem_skip_up2(sem_out_1up2)
sem_skipup3=self.sem_skip_up3(sem_out_1up3)
sem_out_1=sem_out_1 + sem_skipup1+sem_skipup2+sem_skipup3
sem_out_1 = self.sem_conv3(sem_out_1)
sem_out_1 = self.upsample(sem_out_1)
return dep_out_1, sem_out_1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









