



一、概述
作为一个新人,对于flink有很多问题
如何部署Flink?
如何开发任务?
如何发布任务?
如何在自己电脑上跑起来?
带着这些问题去了解并记录如下,还在持续完善中。
网上有很多资料,非常感谢!
1、流处理
流处理和批处理所提供的SLA(服务等级协议)是完全不相同, 流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。比较典型的有:实现批处理的开源方案有MapReduce、Spark;实现流处理的开源方案有Storm;Spark的Streaming 其实本质上也是微批处理。
2、版本路径
V1.14.0
1.有界流支持 Checkpoint;
2.批执行模式支持 DataStream 和 Table/SQL 混合应用;
3.新增 Hybrid Source 功能;
4.新增 缓冲区去膨胀 功能;
5.新增 细粒度资源管理 功能;
6.新增 DataStream 的 Pulsar 连接器;
V1.15.0
1.支持增量的 Savepoint;
2.保证作业级别的指标在 Reactive 模式下可以正常工作;
3.为自适应调度器添加了异常历史记录;
4.引入自适应批调度器,支持根据每个节点需要处理的数据量的大小自动决定批处理作业中各节点的并行度;
5.支持跨源节点的 Watermark 对齐;
6.SQL 通过保持拓扑不变的方式使相同的查询在升级 Flink 版本后仍然可以启动和执行;
7.支持基于 Changelog 的状态存储;
8.支持清理重试;
9.增加对 OpenAPI 的支持;
10.默认启用作业结束前的 Checkpoint;
11.优化 Application 模式;
12.批处理支持 Window table-valued 函数;
13.SQL 增加 CAST函数和JSON函数;
14.可以结合任何 Scala 版本 (包括 Scala 3) 使用 Flink的 Java API;
15.新增支持异步输出与端到端一致性的ES Sink;
16.支持 CSV 格式和 小文件压缩功能;
V1.16.0
1.批处理-SQL Gateway 支持 REST API 和 HiveServer2 协议;
2.批处理-完善Hive语法兼容,使用 HiveServer2 协议连接 SQL Gateway,SQL Gateway 会自动注册 Hive Catalog,自动切换到 Hive 方言,自动使用批处理模式提交作业;
3.批处理-支持Join Hint;
4.批处理-支持自适应 Hash Join;
5.批处理-支持批处理的预测执行;
6.批处理-支持混合 Shuffle 模式(实验);
7.批处理-优化Blocking shuffle;
8.批处理-支持动态分区裁剪;
9.流处理-支持Generalized Incremental Checkpoint;
10.流处理-改进 RocksDB Rescaling;
11.流处理-改善 State Backend 的监测体验和可用性;
12.流处理-支持透支缓冲区;
13.流处理-更新了从 Aligned Checkpoint(AC)切换到 Unaligned Checkpoint(UC)的时间点;
14.流处理-对于复杂的流作业可以在运行前检测并解决潜在的正确性问题;
15.流处理-维表关联-支持了通用的缓存机制和相关指标,可以加速维表查询;
16.流处理-维表关联-通过作业配置或查询提示支持可配置的异步模式(ALLOW_UNORDERED),在不影响正确性的前提下大大提升查询吞吐;
17.流处理-维表关联-支持可重试的查询,解决维表数据更新延迟问题;
18.流处理-异步 I/O 支持重试;
19.流处理-新语法-USING JAR 支持动态加载 UDF jar包,方便平台开发者轻松实现 UDF 的管理和相关作业的提交;
20.流处理-新语法-CREATE TABLE AS SELECT 方便用户基于已有的表和查询创建新的表;
21.流处理-新语法-ANALYZE TABLE 支持用户手工为原表生成统计信息,以便优化器可以生成更优的执行计划;
22.批处理-新语法-支持通过 DataStream#cache 缓存 Transformation 的执行结果;
23.History Server 及已完成作业的信息增强;
24.在 Table API 或 SQL 应用程序中支持 Protobuf 格式;
25.为异步 Sink 引入可配置的 RateLimitingStrategy;
V1.17.0
1.批处理-支持 Sink 算子预测执行,优化预测执行慢任务的检测;
2.批处理-自适应批处理调度器成为了批作业的默认调度器,改进自适应批调度器的配置,增强了自适应批处理调度器的能力;
3.批处理-混合 Shuffle 模式支持自适应批调度器和预测执行,混合 Shuffle 模式支持重用中间数据;
4.批处理-支持 SQL Client 的 gateway 模式,可以使用 SQL 语句来管理作业的生命周期;
5.批处理-为 Batch 模式引入了新的 Delete 和 Update API,扩展了 ALTER TABLE 语法,包括 ADD/MODIFY/DROP 列、主键和 Watermark 的能力;
6.批处理-优化Hive connector,在流批模式下均能自动地进行文件合并;
7.引入了动态规划 join-reorder 算法,引入了动态 local hash aggregation 策略,移除了不必要的虚拟函数调用;
8.流处理-引入实验性功能 PLAN_ADVICE;
9.流处理-增强 watermark 对齐;
10.流处理-扩展 Streaming FileSink;
11.流处理-解决 UC 会写入过多的小文件,导致 HDFS 的 namenode 负载过高的问题,提供了 REST API,可以在作业运行时手动触发具有自定义 Checkpoint 类型的 Checkpoint;
12.流处理-RocksDBStateBackend 升级,Calcite 升级;
13.在 Slack 频道加入了性能日常监控汇报来帮助开发者快速发现性能回退问题。
14.支持 Task 级别火焰图;
15.支持通用的令牌机制;
V1.18.0
1.FlinkSQL-新增 Flink SQL Gateway 的 JDBC Driver 支持
2.FlinkSQL-新增 Flink 连接器的存储过程(Stored Procedure)支持
3.FlinkSQL-新增 DDL 支持
4.FlinkSQL-新增 时间旅行(Time Traveling)SQL 支持
5.流处理-Table API & SQL 支持算子级别状态保留时间(TTL)
6.流处理-支持使用 SQL Hint 配置 水印对齐 和 数据源空闲超时
7.批处理-Hybrid Shuffle 支持远程存储
8.批处理-新增 Flink SQL 的运行时过滤(Runtime Filter)
9.批处理-新增 Flink SQL 算子的融合代码生成(Operator Fusion Codegen)
10.云原生-增强自动弹性化(Elasticity)
11.云原生-新增通过 REST API 控制动态细粒度扩缩容
12.云原生-支持更快地 RocksDB 扩缩容
13.新增 Java 17 支持
14.生产可用的水印对齐(Watermark Alignment)功能
15.可插拔式故障处理
16.SQL 客户端改进
17.Apache Pekko 代替 Akka
18.Calcite 升级
19.重要 API 弃用
- SourceFunction已经弃用
- SinkFunction 尚未正式弃用,即将被 SinkV2 所取代
- Queryable State现已弃用
- DataSet API现已弃用
二、Flink集群部署模式
1、Flink on YARN
在YARN模式下,Flink作为YARN集群上的应用程序运行,YARN负责资源分配和管理,Flink负责执行任务。
提供高可用性,可以与Hadoop生态系统其他组件无缝集成。
2、Flink on Kubernetes
在 Kubernetes 模式下,Flink 应用程序作为 Kubernetes 集群上的容器化应用程序运行。Kubernetes 负责集群的管理、资源的分配和服务的发现。
Flink 提供了与 Kubernetes 集成的 Native Kubernetes 部署模式,以及基于 Helm 的部署选项。
3、Standalone Mode
Standalone 模式允许 Flink 作为独立集群运行,不需要外部的资源管理器。
它有一个 Master 进程(JobManager)和多个 Worker 进程(TaskManager)。
默认情况下,Standalone 模式不提供高可用性(HA)。但可以通过配置多个 JobManager 实例并使用 ZooKeeper 来实现高可用性。
缺点是无法隔离资源。
4、Local Mode
Flink 可以在本地机器上以单进程的形式运行,所有任务都将在 JVM 进程中执行。这种模式主要用于开发和测试。
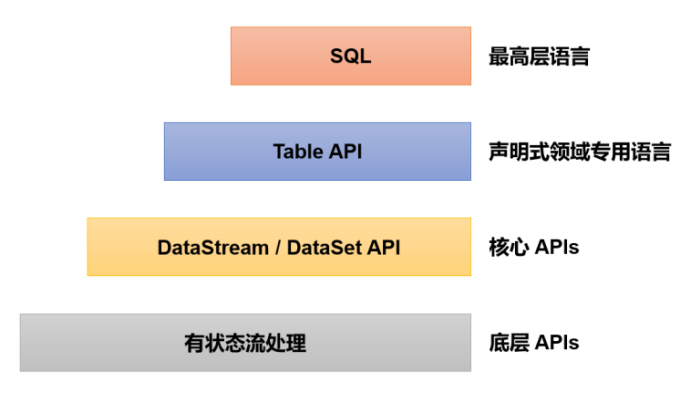
三、作业开发API
大部分数据开发不具备应用开发能力,因此数据开发通常都使用SQL来开发。
1、流处理 DataStream API
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java 集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用 DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
你可以通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后,你可以基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。
1.1、执行模式
执行模式可以通过 execution.runtime-mode 设置来配置,有三种可选的值:STREAMING、BATCH、AUTOMATIC
一些特殊情况下,你可以使用流模式运行有边界作业:
- 一种情况为使用有边界作业的运行结果去初始化一些作业状态,并将该状态在之后的无边界作业中使用。例如,通过
流模式运行一个有边界作业,获取一个 savepoint,然后在一个无边界作业上恢复这个 savepoint。目前来说这是一个可行但非常特殊的用例。当我们允许将 savepoint 作为批执行作业的附加输出时,这个用例会被以批执行模式运行有边界作业的更好实践所取代。 - 另一个可能使用
流模式运行有边界作业的情况是为无边界数据源写测试代码的时候。对于测试来说,在这些情况下使用有边界数据源可能更自然。
设置执行模式:
- 通过命令行参数指定:
bin/flink run -Dexecution.runtime-mode=BATCH <jarFile>- 通过代码指定:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);1.1.1、STREAMING(默认)
在流执行模式下,所有任务需要一直在线/运行。这使得 Flink可以通过整个管道立即处理新的记录,以达到我们需要的连续和低延迟的流处理。这同样意味着分配给某个作业的 TaskManagers 需要有足够的资源来同时运行所有的任务。
网络 shuffle 是 流水线 式的,这意味着记录会立即发送给下游任务,在网络层上进行一些缓冲。同样,这也是必须的,因为当处理连续的数据流时,在任务(或任务管道)之间没有可以实体化的自然数据点(时间点)。这与批执行模式形成了鲜明的对比,在批执行模式下,中间的结果可以被实体化,如下所述。
1.1.2、BATCH
在批执行模式下,一个作业的任务可以被分离成可以一个接一个执行的阶段。我们之所以能做到这一点,是因为输入是有边界的,因此 Flink 可以在进入下一个阶段之前完全处理管道中的一个阶段。
不同于流模式立即向下游任务发送记录,分阶段处理要求 Flink 将任务的中间结果实体化到一些非永久存储中,让下游任务在上游任务已经下线后再读取。这将增加处理的延迟,但也会带来其他有趣的特性。其一,这允许 Flink 在故障发生时回溯到最新的可用结果,而不是重新启动整个任务。其二,批作业可以在更少的资源上执行(就 TaskManagers 的可用槽而言),因为系统可以一个接一个地顺序执行任务。
TaskManagers 将至少在下游任务开始消费它们前保留中间结果(从技术上讲,它们将被保留到消费的流水线区域产生它们的输出为止)。在这之后,只要空间允许,它们就会被保留,以便在失败的情况下,可以回溯到前面涉及的结果。
1.1.3、AUTOMATIC
让系统根据数据源的边界性来决定
2、批处理 DataSet API(弃用)
DataSet API是Flink的批处理API,用于处理有界的数据集,适合用于静态数据,可以在数据全部可用时进行全面的批处理计算。
主要功能包括对静态数据进行批处理操作,将静态数据抽象成分布式数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理。Flink先将接入的数据(如通过读取文本或从本地集合)创建转换成DataSet数据集,并行分布在集群的每个节点上,然后进行各种转换操作(如map、filter、union、group等),最后通过DataSink操作将结果数据集输出到外部系统。
3、Table API & SQL(推荐)
无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用 TableAPI 或者 SQL 来实现;这两种 API 对于一张表执行相同的查询操作,得到的结果是完全一样的。
Table API 和 SQL 最初并不完善,在 Flink 1.9 版本合并阿里巴巴内部版本Blink 之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到 Flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的 1.13 版本中,Table API 和 SQL 也依然不算稳定,接口用法还在不停调整和更新。
在早期的版本中,有专门的用于输入输出的 TableSource 和 TableSink,这与流处理里的概念是一一对应的;不过这种方式与关系型表和 SQL 的使用习惯不符,所以已被弃用,不再区分 Source 和 Sink。例如:
// 创建表环境
val tableEnv = ...;
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector'= ...)")
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector'= ...)")
// 执行 SQL 对表进行查询转换,得到一个新的表
val table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ")
// 使用 Table API 对表进行查询转换,得到一个新的表
val table2 = tableEnv.from("inputTable").select(...)
// 将得到的结果写入输出表
val tableResult = table1.executeInsert("outputTable")四、作业交付形式
1、FlinkSql
2、Jar
3、组合形式
运行一个发布服务,接受sql参数,通过模版jar来提交,模版jar可以是下面的样子
public class SqlTemplate {
public static void main(String[] args) throws Exception {
ParameterTool parameters = ParameterTool.fromArgs(args);//获取传递的参数
String arg = parameters.get("arg",null);
if(arg == null){
return ;
}
arg = URLDecoder.decode(arg, StandardCharsets.UTF_8.toString());//URLDecoder解码
String[] programArgs = arg.split("\\|\\|");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置重启策略,最多重启三次,每次间隔5秒钟
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(5)
));
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Configuration configuration = tableEnv.getConfig().getConfiguration();
//任务名称设定
configuration.setString("pipeline.name",programArgs[0]);
// 任务并行度设定
env.setParallelism(Integer.parseInt(programArgs[1]));
//任务类型,流式任务强制开启checkpoint
if("stream".equals(programArgs[2])){
//检查点设定
if(!StringUtils.isNullOrWhitespaceOnly(programArgs[3])){
CheckPoint cp = JSON.parseObject(programArgs[3],CheckPoint.class);
//开启检查点
if(cp.getEnable()){
//开启检查点,1S一次
env.enableCheckpointing(cp.getCheckpointInterval());
//检查点策略 EXACTLY_ONCE 精准一次 AT_LEAST_ONCE至少一次
env.getCheckpointConfig().setCheckpointingMode(cp.getCheckPointingMode()==1?CheckpointingMode.EXACTLY_ONCE:CheckpointingMode.AT_LEAST_ONCE);
Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(cp.getCheckpointTimeout());
同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(cp.getMaxConcurrentCheckpoints());
//设置检查点保存位置
env.getCheckpointConfig().setCheckpointStorage(cp.getCheckpointDirectory());
//开启实验性的 unaligned checkpoints
if(cp.getUnalignedCheckpointsEnabled()){
env.getCheckpointConfig().enableUnalignedCheckpoints();
}
}
}else{//开启默认配置
//开启检查点,5S一次
env.enableCheckpointing(5000);
//检查点策略 EXACTLY_ONCE 精准一次 AT_LEAST_ONCE至少一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
Checkpoint 必须在五分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(300000);
同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//开启实验性的 unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
}
}
//可执行的SQL单节点执行
String sql = programArgs[4];
//特殊符号在连接器里都会被使用,采用双特殊符号进行分割
String[] sqlExecu = sql.split(";;");
List<String> create = new ArrayList<>();
List<String> insert = new ArrayList<>();
for (String script : sqlExecu) {
if(!script.startsWith("insert") && !script.startsWith("INSERT")){
create.add(script);
}else{
insert.add(script);
}
}
//可执行的SQL单节点执行
create.forEach(tableEnv::executeSql);
// 运行多条 INSERT 语句,将原表数据输出到多个结果表中
StatementSet stmtSet = tableEnv.createStatementSet();
insert.forEach(stmtSet::addInsertSql);
//开始执行任务
TableResult execute = stmtSet.execute();
}五、作业提交方式
1、WebUI
2、CLI
2.1、sql-client.sh
一般只用于开发测试
3、Rest API
六、作业部署模式
1、Application模式(推荐)
Flink 1.11版本中引入的一种新的部署模式,旨在解决Session模式和Per-Job模式存在的问题。
为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在集群中(JobManager)运行用户程序的main方法,而不是在客户端,来生成JobGraph,从而减少了客户端的资源消耗,并在不同应用之间提供了资源隔离和负载平衡保证。
./bin/flink run-application \
-t yarn-application \
-Dparallelism.default=3 \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.application.name=FlinkAppName \
-Dtaskmanager.numberOfTaskSlots=3 \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist/lib;hdfs://myhdfs/my-remote-flink-dist/plugins" \
-c com.dake.FlinkAppName \
${JarFileDir}/FlinkStudy.jar如果通过Yarn来运行,还可以提前上传jar,并指定yarn.provided.lib.dirs参数来设置依赖包,避免大量的二进制文件传输。
./bin/flink run-application \
-t yarn-application \
-Dparallelism.default=3 \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.application.name=FlinkAppName \
-Dtaskmanager.numberOfTaskSlots=3 \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist/lib;hdfs://myhdfs/my-remote-flink-dist/plugins" \
-c com.dake.FlinkAppName \
hdfs://${JarFileDir}/FlinkStudy.jar也可以将 yarn.provided.lib.dirs 配置到 conf/flink-conf.yaml,这时提交作业就和普通作业没有区别了
2、Session模式
所有作业共享集群资源,可重用已启动的TaskManager资源,减少启动时间。
隔离性差,JM 负载瓶颈,main 方法在客户端执行。
2.1、启动会话
./bin/yarn-session.sh \
-jm <jm-memory> \
-tm <tm-memory> \
-s <slots-per-taskmanager> \
-z <zk-namespace> \
-nm <app-name> \
-d2.2、提交作业
./bin/flink run \
-c com.dake.FlinkAppName \
-yid application_1602374521458_0001 \
${JarFileDir}/FlinkStudy.jar3、Per-Job模式(已弃用)
每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行
这是最直接的提交方式,适用于单个作业的提交
./bin/flink run \
-t yarn-per-job \
-d -ynm FlinkAppName \
-Dyarn.application.name=FlinkRetention \
-c com.dake.FlinkAppName \
${JarFileDir}/FlinkStudy.jar七、Flink架构设计
1、架构

1.1、高吞吐、低延迟、高性能
支持高吞吐、低延迟、高性能。Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。Spark 只能兼顾高吞吐和高性能特性,无法做到低延迟保障,因为Spark是用批处理来做流处理。Storm 只能支持低延时和高性能特性,无法满足高吞吐的要求。
实现原理类似kafka的缓存机制,可以调节缓存大小来平衡低延迟和高吞吐。
并不是同时支持低延迟和高吞吐,而是需要根据需要来取舍。
1.2、容错
1.3、内存管理
Flink的内存管理机制也是Flink的一大亮点。Flink在JVM内部实现了自己的内存管理。
NetworkBufferPool 负责管理和分配MemorySegment给每个Task的LocalBufferPool,而数据则是序列化成byte[]或者堆外内存,存放在这个MemorySegment中。而MemorySegment则是在TaskManager启动的时候就已经初始化好了,不需要再次去申请。当不需要这块数据的时候,可以直接调用MemorySegment的free或者release方法。release方法是对free的一层封装,其实内部使用的还是free,去释放内存。
这样就可以实现自主的内存管理了。对于堆内存来说,直接获取所有内存并放入老年代,并令用户对象只在新生代存活,可以极大的减少Full GC。
1.3.1、MemorySegment
MemorySegment是Flink内存管理的核心,是Flink的内存抽象。默认情况下,一个MemorySegment可以被看做是一个32KB大小的内存块抽象。这个内存即可以是JVM里的一个byte[],也可以是堆外内存,这个可以从MemorySegment的构造方法中看出来。
Flink为MemorySegment提供了两个实现类:
- org.apache.flink.core.memory.HeapMemorySegment:已废弃
- org.apache.flink.core.memory.HybridMemorySegment:可管理堆外内存
1.3.2、NetworkBufferPool
NetworkBufferPool是在TaskManager启动的时候创建的:
- TaskManagerRunner的runTaskManager方法创建TaskManagerRunner实例
- 再运行startTaskManager
- startTaskManager中会调用TaskManagerServices.fromConfiguration方法,去创建NetworkBufferPool。
所以NetworkBufferPool在每个TaskManager上只有一个,负责所有子Task的内存管理。其实例化时,就会获取所有可由它管理的内存。
1.3.3、LocalBufferPool
NetworkBufferPool是一个总的管理TaskManager内存的类。而TM上,每个task的内存隔离是通过LocalBufferPool来实现的,每个Task都有一个和其他Task隔离的LocalBufferPool。NetworkBufferPool负责分配MemorySegments给各个LocalBufferPool,LocalBufferPool在初始化的时候就需要有numberOfRequiredMemorySegments个MemorySegments,这个是由ResultPartition的subpartition决定。LocalBufferPool就是来管理各自task上的MemorySegments的。
2、四大组件
2.1、作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
2.2、任务管理器(TaskManager)
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
2.3、资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
2.4、分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
3、四大基石
3.1、窗口Window
流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算
Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口
类似离线批处理分析中开窗函数中窗口大小设置
3.1.1、传统DB开窗函数
在ISO SQL规定了这样的函数为开窗函数,在 Oracle中则被称为分析函数,而在DB2中则被称为OLAP函数。
SELECT FCITY , FAGE , COUNT(*) OVER()
FROM T_Person
WHERE FSALARY<5000 等价于:
SELECT FCITY , FAGE ,
(
SELECT COUNT(* ) FROM T_Person
WHERE FSALARY<5000
)
FROM T_Person
WHERE FSALARY<5000 3.1.2、Flink窗口函数
3.2、时间Time
Flink中窗口计算,基本上都是基于时间设置窗口
Flink还实现了Watermark的机制,能够支持基于事件时间的处理,能够容忍迟到/乱序的数据
基于事件时间窗口计算:EventTime事件时间、窗口计算Window、窗口类型
3.3、状态State
Flink计算引擎,自身就是基于状态计算框架,默认情况下程序自己管理状态
提供一致性的语义,使得用户在编程时能够更轻松、更容易地去管理状态
提供一套非常简单明了的State API,包括ValueState、ListState、MapState,BroadcastState
3.4、检查点Checkpoint
Flink Checkpoint检查点:保存状态数据
基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义
进行Checkpoint后,可以设置自动进行故障恢复
保存点Savepoint,人工进行Checkpoint操作,进行程序恢复执行
4、SQL Gateway
知乎文章:Flink深入浅出:Sql Gateway源码分析
在Flink SQL Gateway的配置中,sql-gateway.session.max-num参数用于设置允许的最大活跃会话数,其默认值为1000000。
5、算子
Map算子
6、Connector
7、SQL语法
8、作业优化
8.1、维表 JOIN 优化
优快云文章:Flink SQL 优化实战 - 维表 JOIN 优化
9、高级玩意
9.1、UDF
- 标量函数(Scalar functions 或
UDAF):输入一条输出一条,将标量值转换成一个新标量值,对标 Hive 中的 UDF; - 表值函数(Table functions 或
UDTF):输入一条条输出多条,对标 Hive 中的 UDTF; - 聚合函数(Aggregate functions 或
UDAF):输入多条输出一条,对标 Hive 中的 UDAF; - 表值聚合函数(Table aggregate functions 或
UDTAF):仅仅支持 Table API,不支持 SQL API,其可以将多行转为多行; - 异步表值函数(Async table functions):这是一种特殊的 UDF,支持异步查询外部数据系统,用在前文介绍到的 lookup join 中作为查询外部系统的函数。
9.2、扩展 Flink 的 Catalog
9.3、flink CEP
9.4、flink SQL Gateway
9.5、Cube计算
9.6、曲线图回溯
9.7、监控
- Job 级别监控指标:监控 Job 状态、Checkpoint 状态及耗时,当 Job 异常时自动通过实时计算平台重启。
- Operator 级别监控指标:监控 Flink 任务的时延、反压、Source/Sink 流量,并对每个 Operator 进行指标聚合,以便用户查看。
- TaskManager 级别监控指标:监控 CPU 使用率、内存使用率、JVM GC 等常规指标。
9.8、恢复(savepoint、checkpoint)
- 主动重启:通过计算平台主动重启 Flink job 前,系统会先对 job 进行 savepoint 操作再关闭 job,然后从该 savepoint 启动(flink run -s :savepointPath)。
- 异常重启:当平台监测到 Flink job 异常时,会自动从上次 checkpoint 开始启动该 job。一旦 job 进入到 RUNNING 状态,会先做一次 savepoint,解除对上一个 checkpoint 的依赖。
9.9、backend
FsStateBackend和RocksDBStateBackend。FsStateBackend支持较小的状态,但不支持增量的状态。

10、作业执行过程
优快云参考文章,实际上都是用SQL开发,不太会用api,上面的文章可以用来参考。
1、pre-flight
在main()方法调用之后开始。
使用Flink的API(DataStream API,Table API,DataSet API)之一构造用户程序。
通常包括以下过程:
-
下载应用所需的依赖
-
执行
main()方法提取job graph -
将依赖和
job graph传输到集群 -
有可能需要等待结果
这样客户端大量消耗资源,因为它可能需要大量的网络带宽来下载依赖项并将二进制文件运送到集群,并且需要CPU周期来执行main()方法。随着更多用户共享同一客户端,此问题会更加明显。
2、runtime
一旦用户代码调用 execute() 就会触发该阶段。用户定义的pipeline将转换为Flink运行时可以理解的形式,称为job graph,并将其传送到集群中。
一般来说,任务的处理流程分为3段:
- 数据源(Source):各种Connector
- 转换(Transformation):各种算子
- 输出(Sink):各种Connector
八、实战
1、说明
flink现在已经不提供windows版本的启动脚本,想要在本地运行local模式比较麻烦。
可以使用单测框架flink-table-test-utils、flink-test-utils提供的MiniCluster来模拟运行,缺点是没有WebUI,优点是不依赖源码以外的资源。
2、依赖
<!-- clients引用了flink-core、flink-runtime、flink-optimizer、flink-java、flink-streaming-java等其他的必须依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.18.1</version>
</dependency>
<!-- 例子是用sql查询source csv,并写入sink csv,需要下面两个依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.18.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.18.1</version>
<scope>provided</scope>
</dependency>
<!-- 单测框架,可以启动MiniCluster模拟执行,不依赖外部flink集群 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-test-utils</artifactId>
<version>1.18.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-test-utils</artifactId>
<version>1.18.1</version>
<scope>test</scope>
</dependency>
3、测试用例
3.1、Datastream Api
public class DataStreamApiTest {
@ClassRule
public static MiniClusterWithClientResource flinkCluster =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setNumberSlotsPerTaskManager(2)
.setNumberTaskManagers (1)
.build());
@Test
public void testIncrementPipeline() throws Exception t {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
Collectsink.values.clear();
env.fromElements (1L, 21L, 22L)
.map( i -> i + 1)
.addSink(new CollectSink());
env.execute();
assertTrue(CollectSink.values.containsAll(Lists.newArrayList(2L, 22L, 23L)));
}
private static class CollectSink implements SinkFunction<Lon> (
// must be static
public static final List<Long> values = Collections.synchronizedList(new ArrayList<>());
@Override
public void invoke(Long value, SinkFunction.Context context) throws Exception {
values.add(value);
}
}
}3.2、TableApiTest
public class TableApiTest {
@CLassRule
public static MiniClusterWithClientResource flinkCluster =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setNumberStotsPerTaskManager(2)
.setNumberTaskManagers(1)
.build();
@Test
public void testTableQuery {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTabLeEnvironment tableEnv = StreamTableEnvironment.create(env);
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
env.setParallelism(1);
// source
String sourceDDL = "CREATE TEMPORARY TABLE MyTable (" +
" id INT," +
" name STRING" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'file:///d:/data.txt'," +
" 'format' = 'csv'" +
")";
tableEnv.executeSq(s sourceDDL);
//transform
Table sourceTable = tableEnv.sqlQuery("SELECT id, name FROM MyTable WHERE id = 1");
// sink
String sinkDDL = "CREATE TEMPORARY TABLE MyTable2 (" +
" id INT," +
" name STRING" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'file:///d:/data2.txt'," +
" 'format' = 'csv'" +
")";
tabLeEnv.executeSql(sinkDDL);
sourceTable.executeInsert("MyTable2").print();
}
}3.3、LambdaTest
泛型和返回类型需要显示的指定
public class LambdaApiTest {
@CLassRule
public static MiniClusterWithClientResource flinkCluster =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setNumberStotsPerTaskManager(2)
.setNumberTaskManagers(1)
.build();
@Test
public static void test() throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source
DataStreamSource<Integer> input = env.fromElements(1, 2, 3);
// transformation
// 必须声明 collector 类型
input.flatMap((Integer number, Collector<String> out) -> {
StringBuilder builder = new StringBuilder();
for (int i = 0; i < number; i++) {
builder.append("a");
out.collect(builder.toString());
}
})
// sink
// 显式提供类型信息
.returns(Types.STRING)
.print();
// execute
env.execute();
}
}
4、其他案例
公众号:六大方法彻底解决Flink Table & SQL维表Join
5、坑
- 第一,避免跨 TaskManager 的 Shuffle,避免不必要的序列化成本;
- 第二,务必设计脏数据收集旁路和失败反馈机制;
- 第三,利用 Flink 的 Accumulators 对批任务设计优雅退出机制;
- 第四,利用 S3 统一管理 Reader/Writer 插件,分布式热加载,提升部署效率。
九、案例
腾讯云文章:50000字,数仓建设保姆级教程,离线和实时一网打尽(理论+实战) 上
阿里云文章合集2020:十大行业经典案例!Apache Flink 的 40 个最佳实践
1、作业帮实时平台
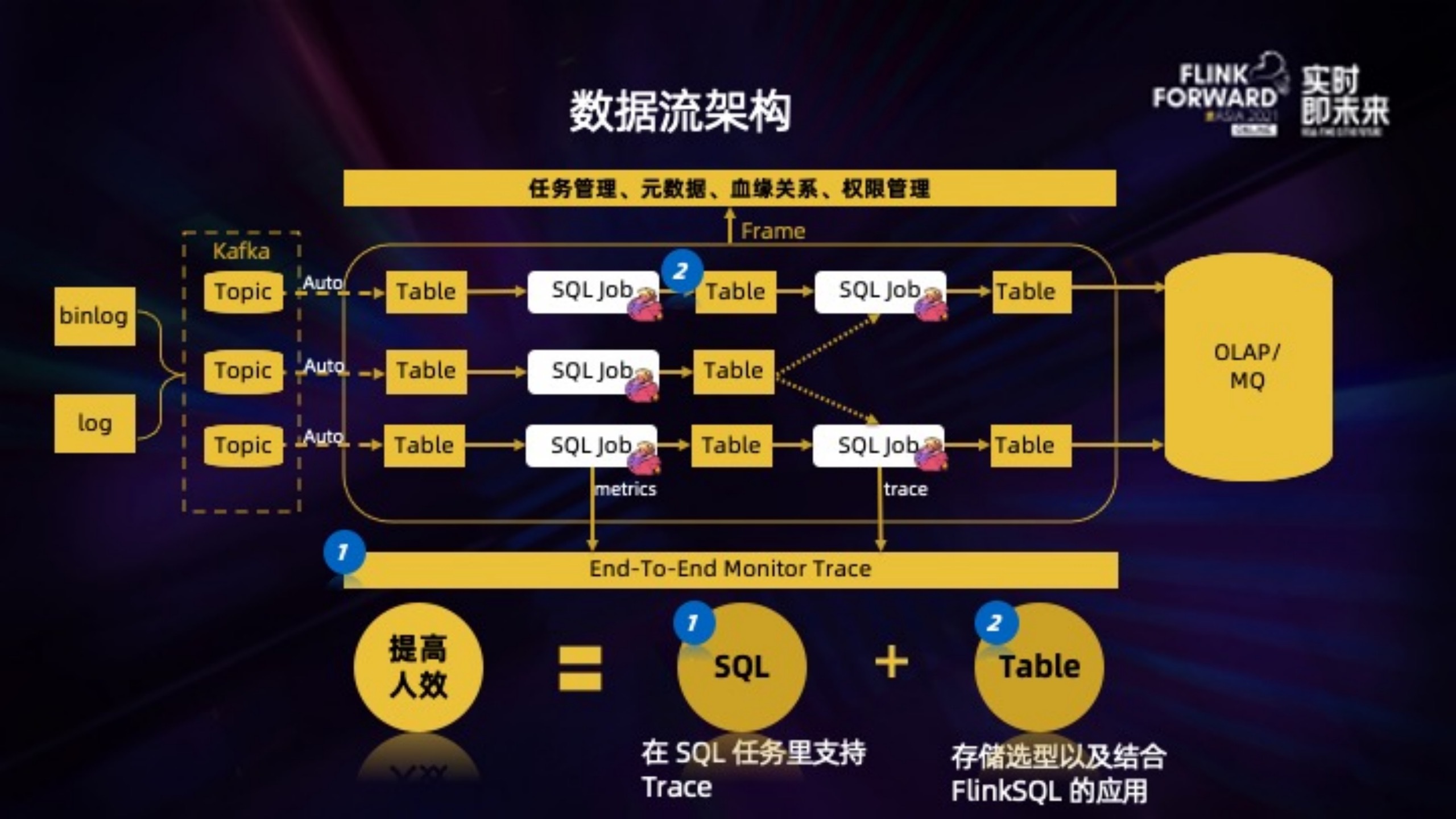
2、腾讯QQ看点基于 Flink 的实时数仓及多维实时数据分析实践
本章节的内容、图片来自
阿里云文章:腾讯看点基于 Flink 的实时数仓及多维实时数据分析实践(有较多实际问题分析)
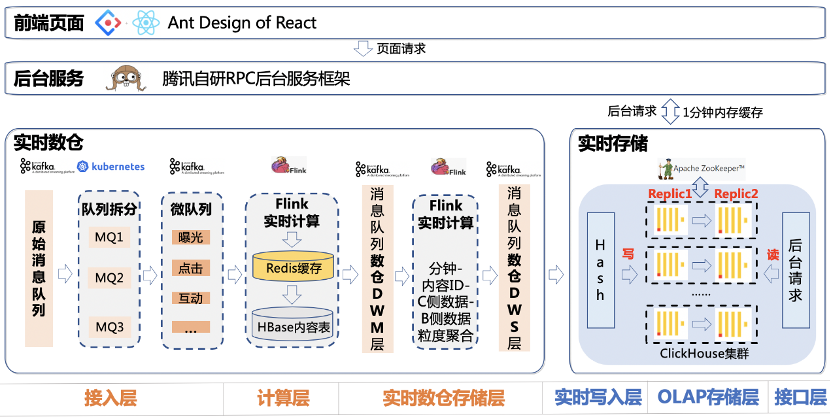
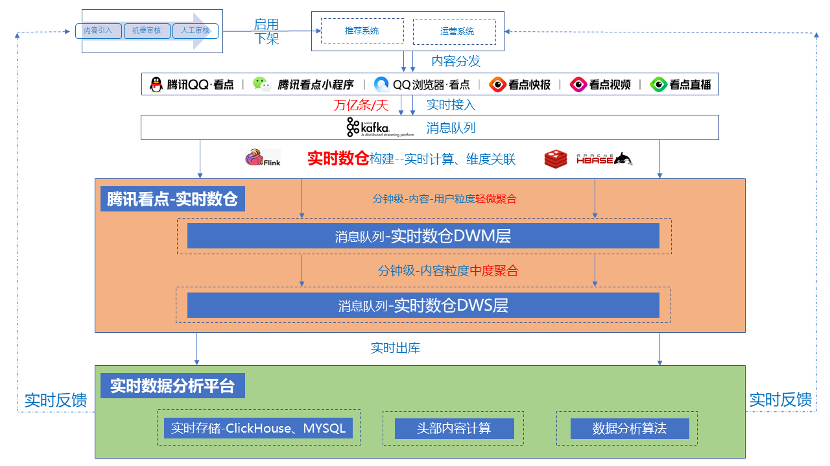
腾讯看点实时数据仓库:DWM 层和 DWS 层,数据延迟 1 分钟。
远见多维实时数据分析系统:亚秒级响应多维条件查询请求,在未命中缓存情况下,过去 30 分钟的查询,99%的请求耗时在 1 秒内;过去 24 小时的查询,90%的请求耗时在 5 秒内,99%的请求耗时在 10 秒内。
2.1、应用架构
多维实时数据分析系统分为三大模块
- 实时计算引擎
- 实时存储引擎
- App层
2.2、实时数仓架构
2.3、解决的痛点案例
多维实时数据分析系统可以解决哪些痛点。比如:
- 推荐同学 10 分钟前上了一个推荐策略,想知道在不同人群的推荐效果怎么样?
- 运营同学想知道,在广东省的用户中,最火的广东地域内容是哪些,方便做地域 Push。
- 审核同学想知道,过去 5 分钟,游戏类被举报最多的内容和账号是哪些?
- 老板可能想了解,过去 10 分钟有多少用户在看点消费了内容,对消费人群有一个宏观了解。
2.4、技术选型
2.4.1、离线Spark+Hdfs
问题:
- 最少 3-6 个小时,目前比较常见的都是提供隔天的查询
- 腾讯看点的数据量太大,带来的不稳定性也比较大,经常会有预料不到的延迟
2.4.2、准实时Kudu+Impala
事业群内部提供了准实时数据查询的功能,底层技术用的是 Kudu+Impala,Impala 虽然是 MPP 架构的大数据计算引擎,并且访问以列式存储数据的 Kudu。但是对于实时数据分析场景来说,查询响应的速度和数据的延迟都还是比较高,查询一次实时 DAU,返回结果耗时至少几分钟,无法提供良好的交互式用户体验。
所以(Kudu+Impala)这种通用大数据处理框架的速度优势更多的是相比(Spark+Hdfs)这种离线分析框架来说的,对于我们这个实时性要求更高的场景,是无法满足的。
2.4.3、实时Flink+Clickhouse
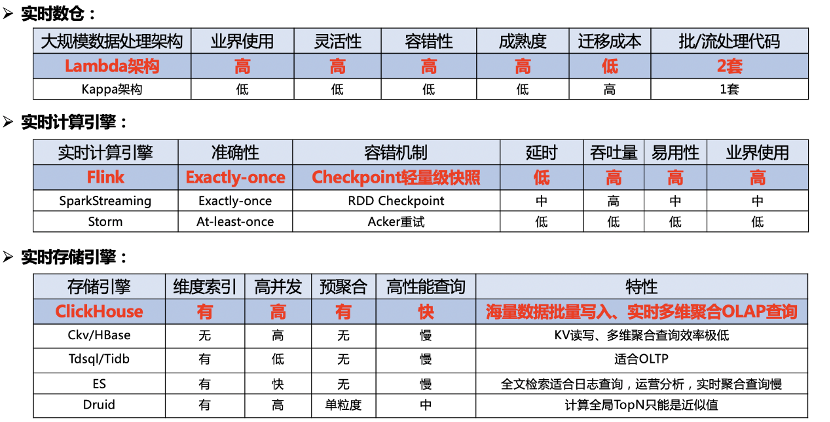
- 第一块是实时数仓的选型,我们选择的是业界比较成熟的 Lambda 架构,他的优点是灵活性高、容错性高、成熟度高和迁移成本低;缺点是实时、离线数据用两套代码,可能会存在一个口径修改了,另一个没改的问题,我们每天都有做数据对账的工作,如果有异常会进行告警。
- 第二块是实时计算引擎选型,因为 Flink 设计之初就是为了流处理,SparkStreaming 严格来说还是微批处理,Strom 用的已经不多了。再看 Flink 具有 Exactly-once 的准确性、轻量级 Checkpoint 容错机制、低延时高吞吐和易用性高的特点,我们选择了 Flink 作为实时计算引擎。
- 第三块是实时存储引擎,我们的要求就是需要有维度索引、支持高并发、预聚合、高性能实时多维 OLAP 查询。可以看到,Hbase、Tdsql 和 ES 都不能满足要求,Druid 有一个缺陷,它是按照时序划分 Segment,无法将同一个内容,存放在同一个 Segment上,计算全局 TopN 只能是近似值,所以我们选择了最近两年大火的 MPP 数据库引擎 ClickHouse。
2.5、难点
- 千万级/s 的海量数据如何实时接入,并且进行极低延迟维表关联。
- 实时存储引擎如何支持高并发写入、高可用分布式和高性能索引查询,是比较难的。
2.5.1、优化点
- 行转列,相当于批处理n行。小时级别降到十几分钟
- 替换hbase维表增加redis缓存。十几分钟降到几秒
- 过滤不存在的防穿透
- 定时缓存防雪崩
- 磁盘阵列raid5
- batch写入,减轻Clickhouse的zk压力(每批十几万)
- 数据分片,同一个id落到一个分片,解决topN不精准的问题
我们这里听取的是 Clickhouse 官方的建议,借助 ZK 实现高可用的方案。数据写入一个分片,仅写入一个副本,然后再写 ZK,通过 ZK 告诉同一个分片的其他副本,其他副本再过来拉取数据,保证数据一致性。
这里没有选用消息队列进行数据同步,是因为 ZK 更加轻量级。而且写的时候,任意写一个副本,其它副本都能够通过 ZK 获得一致的数据。而且就算其它节点第一次来获取数据失败了,后面只要发现它跟 ZK 上记录的数据不一致,就会再次尝试获取数据,保证一致性。
数据写入遇到的第一个问题是,海量数据直接写入 Clickhouse 的话,会导致 ZK 的 QPS 太高,解决方案是改用 Batch 方式写入。Batch 设置多大呢,Batch 太小的话缓解不了 ZK 的压力,Batch 也不能太大,不然上游内存压力太大,通过实验,最终我们选用了大小几十万的 Batch。
2.6、扩容
HBase原始数据都存放在 HDFS 上,扩容只是 Region Server 扩容,不涉及原始数据的迁移。
Redis 是哈希槽这种类似一致性哈希的方式,是比较经典分布式缓存的方案。Redis slot 在 Rehash 的过程中虽然存在短暂的 ask 读不可用,但是总体来说迁移是比较方便的,从原 h[0]迁移到 h[1],最后再删除 h[0]。
Clickhouse 的每个分片数据都是在本地,是一个比较底层存储引擎,不能像 HBase 那样方便扩容。 Clickhouse 大部分都是 OLAP 批量查询,不是点查,而且由于列式存储,不支持删除的特性,一致性哈希的方案不是很适合。目前扩容的方案是,另外消费一份数据,写入新 Clickhouse 集群,两个集群一起跑一段时间,因为实时数据就保存 3 天,等 3 天之后,后台服务直接访问新集群。
3、字节跳动 Flink 单点恢复功能实践

在机器故障下线的时候,只让在这台机器上的 Tasks 进行 Failover,而这些 Tasks 的上下游 Tasks 能恰好感知到这些失败的 Tasks,并作出对应的措施:
- 上游:将原本输出到 Failed Tasks 的数据直接丢弃,等待 Failover 完成后再开始发送数据。
- 下游:清空 Failed Tasks 产生的不完整数据,等待 Failover 完成后再重新建立连接并接受数据
4、好未来
阿里云文章:好未来实时平台建设(比较详细的说明了实现方法)

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









