






1. 概述
Java语言和XML数据格式都被认为是过去数十年中最为重要的IT技术之一,Java为编程提供了一种与平台无关的语言,而XML则为数据交换提供了一种与平台无关的表现形式。XML和Java常常被认为是最完美的组合,使用XML的半结构化模型描述各种各样的业务数据、表达复杂的业务信息,使用Java语言来实现独立于平台的、易于处理的面向对象的应用软件解决方案。
那么Java语言中针对于XML的解析器也随之出现,IBM、Apache以及其他许多公司,开发了很多用于XML数据处理的Java API。从JDK 1.4开始,Sun公司将其中一些非常重要的代码库继承到Java 2平台之中,并且到现在,这些API也一直更新。熟练掌握XML数据处理的程序开发技巧,对于现在的程序员来说,非常重要。
2. XML数据解析的概念
什么是XML数据解析呢?XML解析器实际上就是能够识别XML基本语法形式的特殊应用程序,并将纯文本XML文档转换成其他某种内存中表现形式(比如XML文档树、或者一系列的解析事件),以便客户端能够方便的对XML文档中的数据进行访问、提取、检索等。
目前市场上有很多XML解析器,各有各的优点和缺点,得到业界认可的XML解析器包括Apache Xerces、IBM XML4J、Oracle XML Parser for Java等等,JDK 1.5后,内置的就是经过修改的Apache Xerces解析器。
3. JAXP简介
用于XML数据处理的Java API(Java API for XML Processing),简称JAXP,这可能是Java中有关XML方便最庞大的API,主要包括4部分,SAX、DOM、TrAX和XPath API。它为解析、处理、验证XML文档数据的基本功能提供了相应的编程接口。
XML解析器种类繁多,开发人员肯定不希望更改一下XML解析器就要更改源代码,为此,就需要对抽象进行编程,JAXP就是很好的选择,它为使用DOM、SAX解析器进行XML数据处理提供了统一的接口,编程人员可以通过JDK提供的标准接口来操作XML文档,则可以随意切换底层的解析器。
如图所示:
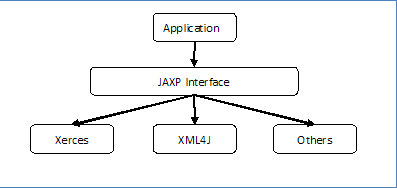
4. DOM和SAX解析模型
DOM和SAX是XML数据处理的两种形式。
4.1. DOM模型
DOM是Document Object Model文档对象模型的缩写,根据W3C的规范,DOM是一种与浏览器、平台、语言无关的接口。DOM是一种在浏览器内编程的模型。
DOM是以层次结构组织的节点或信息片断的集合,是以树结构来表示数据与数据之间的关系的,通过树中各节点以及节点之间的父子关系来表示XML文档中的元素、属性、文本内容以及元素之间关系的嵌套关系。
DOM模型,允许开发人员在树中访问节点、修改和创建节点。分析并构造一棵XML文档树需要加载整个XML文档,然后才能做其他的工作。
从DOM模型的结构可以分析DOM的优点和缺点。
优点:
1. 可以任意次的操作和访问文档树
2. 在树中可以上下导航,访问节点非常方便
3. 可以对树中的节点进行增删改查多种操作
缺点:
1. 必须加载整个XML文档并进行处理后才能进行操作,所以特别大的XML文档处理效率很低
4.2. SAX模型
SAX模型是不同于DOM模型的另一种解析方式,SAX是Simple API for XML的简称,它是一种顺序读取XML文档的解析器。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的标记的时候,它可以激活一个回调方法,告诉该方法指定的标记已经找到,然后回调方法会进行相应的处理。SAX的事件驱动模型,为它提供了很好的性能,SAX处理XML时,是从头开始,对XML元素是一个一个的处理,所以可以有效的抑制内存的消耗,适合处理大内容的XML文档。
也可以从SAX的解析方法来分析SAX的优缺点。
优点:
1. 性能很好,处理大文件时也很快
缺点:
1. 是一次性处理,只能进行读,不能进行其他的操作,不适合处理那些需要做复杂处理的XML文档
5. JAXP中DOM解析器
在JAXP中使用DOM解析器,首先必须要创建一个DOM解析器对象,在JAXP中,我们可以通过DocumentBuilderFactory、DocumentBuilder来创建具体的解析器工厂对象,然后再通过解析器对象来解析XML文档。
示例代码如下:
public void testDOMBuilder() {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
File file = new File("test.xml");
Document root = builder.parse(file);
System.out.println(builder.getClass());
printDomTree(root);
} catch (Exception e) {
e.printStackTrace();
}
}
在这里,我们要解释一下DocumentBuilderFactory.newInstance()是如何获得的解析器工厂对象的,在JAXP中,newInstance在确定具体解析器工厂实现类时,将按照如下顺序进行查找:
1. 使用javax.xml.parsers.DocumentBuilderFactory系统属性,可通过System.setProperties(…)方法设置或者使用java命令的-D选项设置系统属性
2. 使用JRE文件夹中的属性文件“lib/jaxp.properties”,可通过在其中增加以下javax.xml.parsers.DocumentBuilderFactory属性,值为解析器的工厂类
3. 使用Services API来确定类名称,Services API将查找在运行时可用的jar中META-INF/services/javax.xml.parsers.DocumentBuilderFactory文件中的类名,通常,解析器jar文件中会包含这个文件,这个过程由JDK自动进行
4. 平台默认的DOcumentBuilderFactory实例
上面实例代码会打印出我们使用的默认XML解析器的class,为:class com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderImpl,可见默认的XML解析器是采用Apache Xerces,如果想要改变XML解析器,可以根据上述四个步骤来更改,也可以实现自己的XML解析器,通过以上步骤来使用,如:
System.setProperty("javax.xml.parsers.DocumentBuilderFactory",
"com.taobao.pengxing.xml.DocumentBuilderFactory");
DOM解析器提供了很多的编程接口:
1. org.w3c.xml.Node
2. org.w3c.xml.Document
3. org.w3c.xml.Element
4. org.w3c.xml.Attr
5. org.w3c.xml.CharacterData接口和子接口
6. ……
XML文档对应的DOM树由各种类型的节点构成,而Node则是这些不同类型的父类,如文档节点,元素节点,文本节点,处理指令节点等等。
在这里,需要着重讲一下org.w3c.xml.Document接口。没个XML文档都有一个文档节点,这个节点对应于整个XML文档,是根节点的父节点,是一个无形的节点,就是Document节点,所有的其他的节点都必须存在于这个Document上下文中,所以Document还包含了所需的创建这些对象的工厂方法:
1. createElement(String tagName)
2. createAttribute(String name)
3. createTextNode(String data)
4. ……
6. JAXP中SAX解析器
同样,要使用SAX模型解析XML文档时,也需要创建SAX解析器对象,和DOM解析器相似,也是通过工厂类SAXParserFactory来获得,代码如下:
public void testSAXParser() throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
XmlHandler handler = new XmlHandler();
File file = new File("test.xml");
parser.parse(file, handler);
printDomTree(handler.root);
}
同样,SAXParserFactory的获得过程和DocumentBuilderFactory一样,也是通过上述4个步骤来获得的,也可以通过打印得出默认SAX解析器的实现是:
class com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl
SAX解析模型是事件驱动的,但是在哪里注册的事件回调函数呢?我们可以对比DOM解析模型,SAX模型的parser方法需要两个参数,另一个是handler:org.xml.sax.helpers.DefaultHandler,就是这里,我们parser方法中传递了自己的Handler:XmlHandler,它继承了DefaultHandler。
在开始使用SAX解析器进行数据处理之前,必须为其注册一系列的事件处理程序接口,org.xml.sax包中给出了这些事件的处理接口的原型,具体包括:
1. ContentHandler 解析器将使用该实例报告与基本文档相关的事件
2. DTDHandler 解析器使用该实例想应用程序报告注释和未解析的实体声明
3. EntityResolver 允许应用程序在包含外部实体之前截取任何外部实体
4. ErrorHandler 解析器将通过此接口报告所有的错误和警告
SAXParser中并没有处理XML文档的逻辑,而解析任务交给了org.xml.sax.XMLReader,并在SAXParser的parse方法中给XMLReader实例指定了各个事件的handler,如下所示:
public void parse(org.xml.sax.InputSource arg0, org.xml.sax.helpers.DefaultHandler arg1) throws org.xml.sax.SAXException, java.io.IOException;
……
15 invokevirtual javax.xml.parsers.SAXParser.getXMLReader() : org.xml.sax.XMLReader [150]
……
org.xml.sax.XMLReader.setContentHandler(org.xml.sax.ContentHandler) : void [161] [nargs: 2]
……
org.xml.sax.XMLReader.setEntityResolver(org.xml.sax.EntityResolver) : void [163] [nargs: 2]
……
org.xml.sax.XMLReader.setErrorHandler(org.xml.sax.ErrorHandler) : void [164] [nargs: 2]
……
46 invokeinterface org.xml.sax.XMLReader.setDTDHandler(org.xml.sax.DTDHandler) : void [162] [nargs: 2]
……
53 invokeinterface org.xml.sax.XMLReader.parse(org.xml.sax.InputSource) : void [165] [nargs: 2]
58 return
而DefaultHandler同时实现了上面四个事件处理接口,所以SAXParserFactory、SAXParser、XMLReader、DefaultHandler、ContentHandler等之间的关系如下图所示:
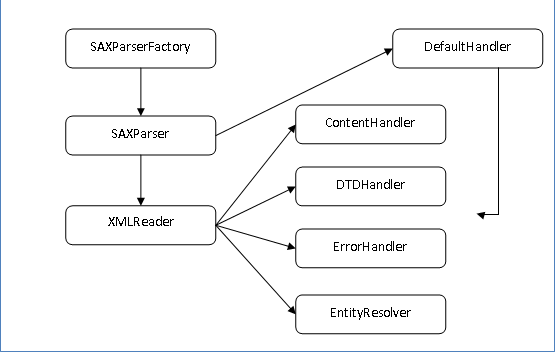
DefaultHandler实现了其他4个接口,并包含这四个接口的方法,这样一来,我们只需继承这个类,并重写其中我们感兴趣的回调函数即可。在这个例子中,我们继承DefaultHandler的类是XmlHandler,通过这个类我们建立了一个XML文档树,代码见附录B。DefaultHandler中有很多事件方法供我们使用, 如:
1. startDocument()
2. endDocument()
3. startElement(String uri, String localName, String qName, Attributes attributes)
4. endElement(String uri, String localName, String qName)
5. characters(char[] ch, int start, int length)
6. ……
7. DOM和SAX之间性能比较
在这里,我们不列出DOM和SAX的性能比较过程,只列出结论:SAX模型在处理XML文档时,速度快,性能好,无论是在查找还是计算,SAX的性能都胜DOM一筹。
8. 基于SAX的Digester
Apache Commons Digester是一种将XML文档映射成Java对象的工具包,最初是Struts的工具包,后来从Struts中分离出来,独立成Apache的一个项目。
Digester和SAX的处理流程相似,通过注册一系列的规则,然后在SAX事件触发后,根据这些rule来构造对应的对象,执行规则指定好的方法等等。如下有一个XML文档:
<?xml version='1.0'?>
<address-book>
<person id="1" category="acquaintance">
<name>Gonzo</name>
<email type="business">gonzo@muppets.com</email>
<address>
<type>home</type>
<street>123 Maine Ave.</street>
<city>Las Vegas</city>
<state>NV</state>
<zip>01234</zip>
<country>USA</country>
</address>
<address>
<type>business</type>
<street>234 Maple Dr.</street>
<city>Los Angeles</city>
<state>CA</state>
<zip>98765</zip>
<country>USA</country>
</address>
</person>
</address-book>
先指定要映射的对象,然后我们可以通过注册Digester已经提供的规则来完成这个XML文档对应的对象的创建,如下:
AddressBook book = new AddressBook();
d.push(book);
d.addObjectCreate("address-book/person", Person.class);
d.addSetProperties("address-book/person");
d.addSetNext("address-book/person", "addPerson"); d.addCallMethod("address-book/person/name", "setName", 0);
d.addCallMethod("address-book/person/email", "addEmail", 2);
d.addCallParam("address-book/person/email", 0, "type");
d.addCallParam("address-book/person/email", 1);
d.addObjectCreate("address-book/person/address", Address.class);
d.addSetNext("address-book/person/address", "addAddress");
d.addSetNestedProperties("address-book/person/address");
根据注册的规则,每当SAX事件触发,根据对应的处理方法,分别调用对应的rule的begin()、body()和end()方法,来完成我们所期望达到的副作用。在调用digester.parse(file)后,Digester就会自动的给book对象中的属性赋值。
我们也可以通过继承Rule抽象类,并实现其中的一些方法,来定制我们的Rule,apache tomcat就是用的Digester来解析XML配置文件的,其中就有它自己的Rule,如:org.apache.catalina.startup.ConnectorCreateRule,并将这个Rule注册给Digester,在Catalina类的createStartDigester()方法中就注册了该Rule,如下所示:
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
Appendix A: 示例代码的XML文件test.xml
<?xml version="1.0"?> <person> <?author 彭星 ?> <name>PengXing</name> <age>21</age> <address> <country code="86">China</country> <city>HangZhou</city> </address> </person>
Appendix B: SAX的事件处理类XmlHandler
class XmlHandler extends DefaultHandler {
public Document root;
private DocumentBuilderFactory factory = null;
private DocumentBuilder builder = null;
private Stack<Node> stack = new Stack<Node>();
private Element tempElem;
private String elemName;
{
factory = DocumentBuilderFactory.newInstance();
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
}
@Override
public void startDocument() {
root = builder.newDocument();
stack.add(root);
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attrs) throws SAXException {
elemName = qName;
tempElem = root.createElement(elemName);
tempElem = root.createElement(elemName);
if (attrs != null) {
for (int i = 0; i < attrs.getLength(); i++) {
tempElem.setAttribute(attrs.getQName(i), attrs.getValue(i));
}
}
stack.peek().appendChild(tempElem);
stack.push(tempElem);
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
stack.pop();
}
@Override
public void processingInstruction(String target, String data)
throws SAXException {
Node instruction = root.createProcessingInstruction(target, data);
stack.peek().appendChild(instruction);
}
@Override
public void characters(char[] ch, int start, int length) {
Node text = root.createTextNode(new String(ch, start, length));
stack.peek().appendChild(text);
}
@Override
public void ignorableWhitespace(char[] ch, int start, int length) {
characters(ch, start, length);
}
}
Appendix C: 工具类Utility
package com.taobao.pengxing.xml;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Utility {
public static void printDomTree(Node node) {
int type = node.getNodeType();
switch (type) {
case Node.DOCUMENT_NODE:
println("<?xml version=\"1.0\" ?>");
printDomTree(((Document) node).getDocumentElement());
break;
case Node.ELEMENT_NODE:
print("<");
print(node.getNodeName());
NamedNodeMap attrs = node.getAttributes();
for (int i = 0; i < attrs.getLength(); i++) {
printDomTree(attrs.item(i));
}
print(">");
NodeList children = node.getChildNodes();
if (children != null) {
for (int i = 0; i < children.getLength(); i++) {
printDomTree(children.item(i));
}
}
print("</" + node.getNodeName() + ">");
break;
case Node.ATTRIBUTE_NODE:
String value = ((Attr) node).getValue();
print(" " + node.getNodeName() + "=\"" + value + "\"");
break;
case Node.ENTITY_REFERENCE_NODE:
print("&");
print(node.getNodeName());
print(";s");
break;
case Node.CDATA_SECTION_NODE:
print("<!CDATA[" + node.getNodeValue() + "]]>");
break;
case Node.TEXT_NODE:
print(node.getNodeValue());
break;
case Node.PROCESSING_INSTRUCTION_NODE:
print("<?" + node.getNodeName() + " "
+ node.getNodeValue() + "?>");
break;
case Node.COMMENT_NODE:
print("<!-- " + node.getNodeValue() + " -->");
break;
}
}
public static void println(String str) {
System.out.println(str);
}
public static void print(String str) {
System.out.print(str);
}
}

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









