



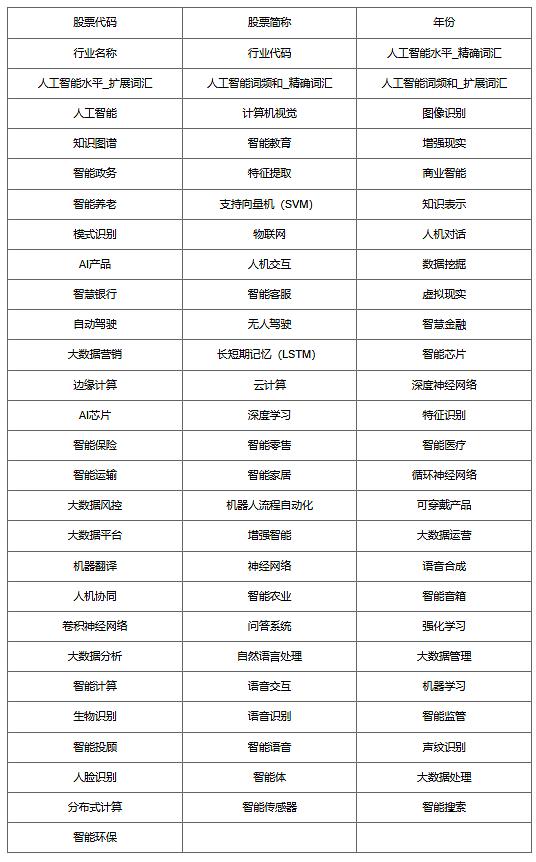
参考《管理世界》中姚加权(2024)的做法,团队根据上市年报文本内容,对73个人工智能的相关词频进行统计,并计算上市公司-人工智能水平,包括精确词汇、扩展词汇两种方式
在前文,利用上市公司年报文本全文数据,对“人工智能”73个相关词频进行了统计,衡量上市公司人工智能水平,本次继续更新数据至2024年
一、数据介绍
数据名称:上市公司人工智能-年报词频统计
数据范围:A股上市公司
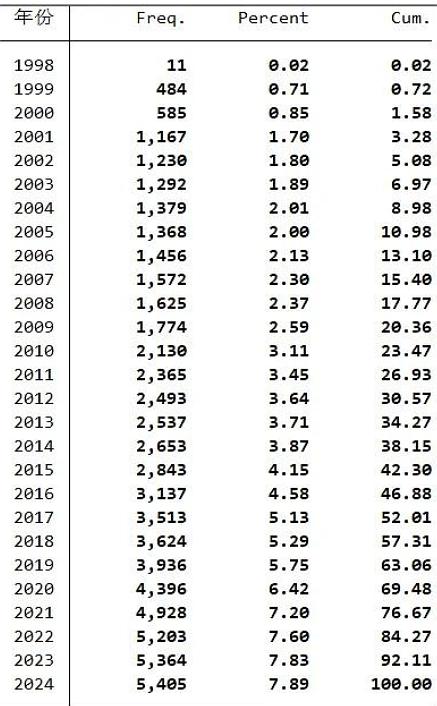
数据年份:1998-2024年
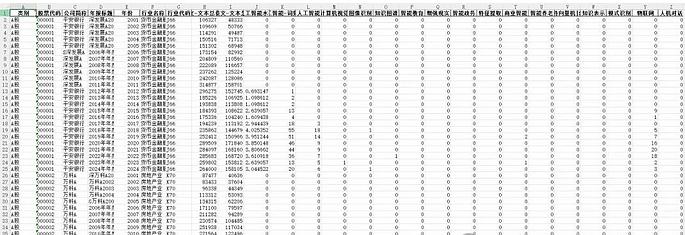
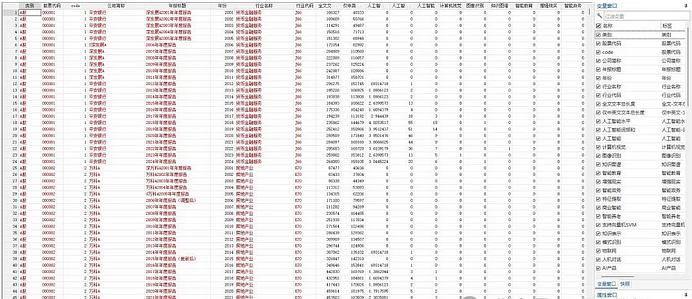
样本数量:68470条,85个变量
数据说明:内含人工智能73个词频、精确和扩展词汇两种方式
二、整理说明
➤爬取上市公司年报原始文件1998-2024年
➤将原始报告文本整理为面板数据
➤统计年报全文的文本长度
➤统计全文中,中英文部分的文本长度
➤构建人工智能术语词典,将词汇扩充到python的jieba库
➤去除停顿词,统计精确词汇、扩展词汇数目
➤计算两种方式下的人工智能水平
三、指标说明
四、数据概览
上市公司数目
上市公司人工智能-excel版本
上市公司人工智能-stata版本
【下载→
方式一(推荐):主页 ↓个人↓简介
方式二:数据下载地址汇总_-优快云博客

















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









