



数据名称:上市公司人工智能年报73个词频文本统计
数据年份:1999-2023
数据范围:A股上市公司
数据来源:巨潮资讯网
数据格式:面板数据
样本数量:63052条,84个变量
参考文献
[1]姚加权,张锟澎,郭李鹏,等.人工智能如何提升企业生产效率?——基于劳动力技能结构调整的视角[J].管理世界,2024,40(02):101-116+133+117-122.

统计方法
参考《管理世界》中姚加权(2024)的方法,团队根据上市年报文本内容,对73个人工智能的相关词频进行统计,并计算上市公司-人工智能水平,包括精确词汇、扩展词汇两种方式。利用上市公司年报文本全文数据对“人工智能”73个相关词频进行了统计,最终衡量上市公司人工智能水平。
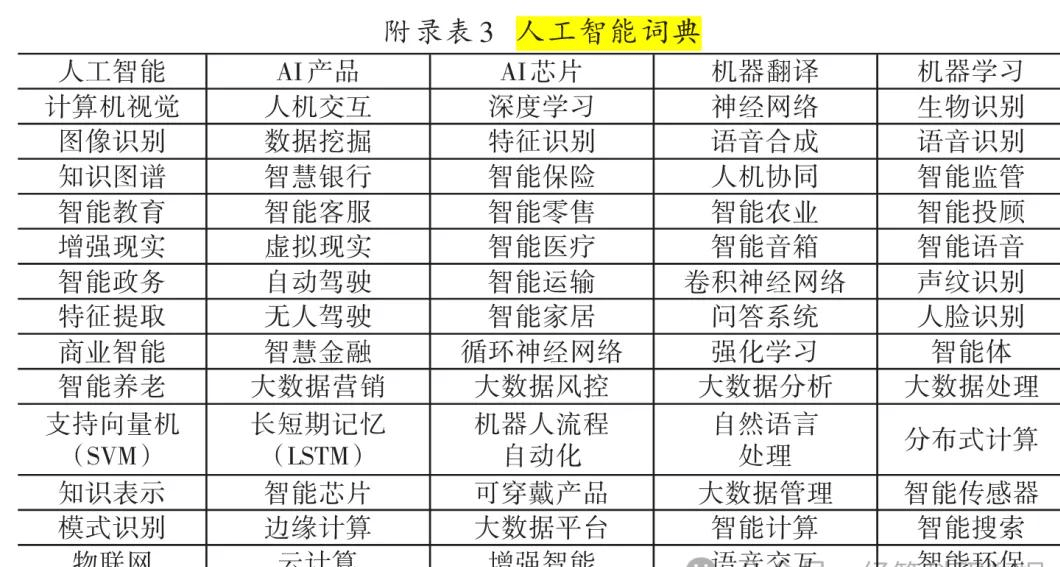
数据指标(部分)
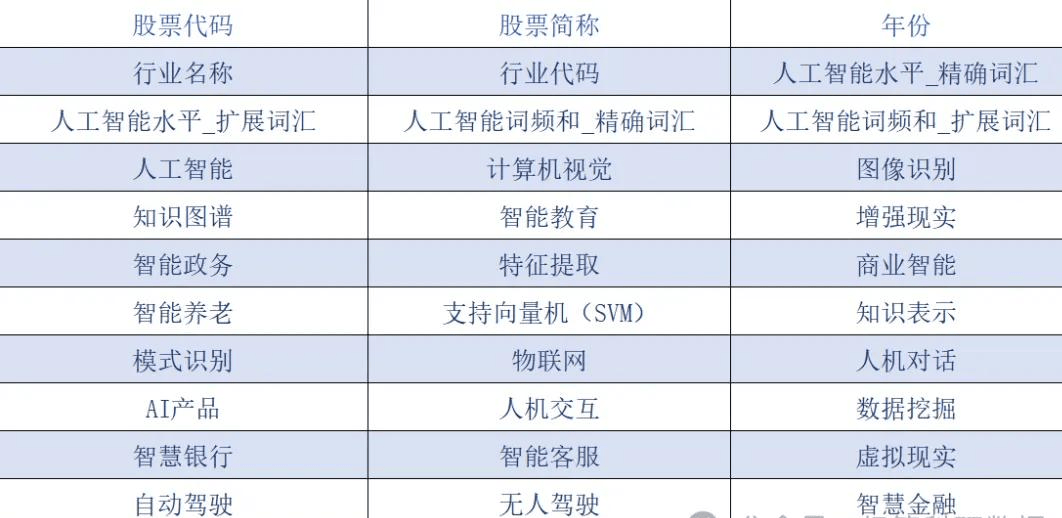
数据预览
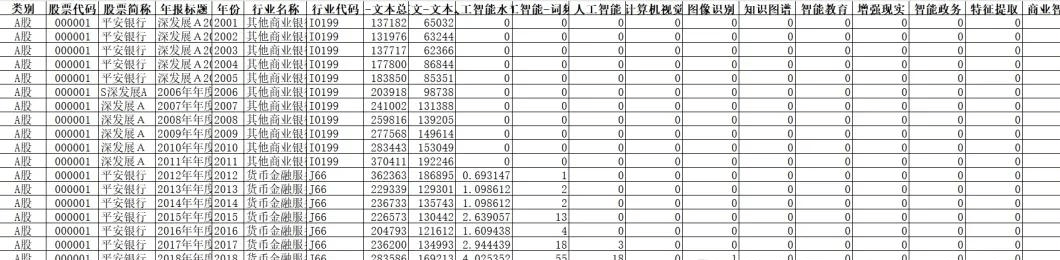
xlsx版
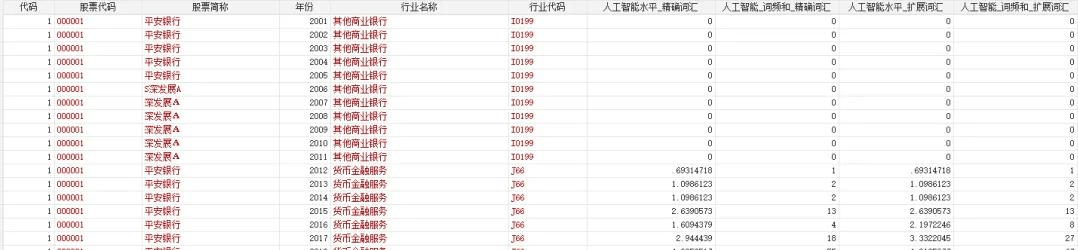
sta版
【下载→
方式一(推荐):主页个人简介
方式二:https://download.youkuaiyun.com/download/paperdata666/89922153】

















 3105
3105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









