







Transformer 模型是一种用于处理序列数据的深度学习模型,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。Transformer 的核心思想是通过 自注意力机制 来捕捉序列中各个位置之间的依赖关系,而无需依赖传统的循环神经网络(RNN)或卷积神经网络(CNN)。这一架构广泛应用于 NLP 领域,并成为如 BERT、GPT、T5 等大规模预训练模型的基础。
1. 模型架构
Transformer 模型由两大部分组成:
- 编码器(Encoder)
- 解码器(Decoder)
这两个部分是通过 自注意力机制 和 前馈神经网络 等操作相互连接的。Transformer 的核心优势是 并行计算 和 长距离依赖捕捉能力,这使得其在 NLP 任务中表现出色。
编码器(Encoder)
编码器的主要任务是处理输入序列,将输入的文本或数据转换为一个抽象的表示。每个编码器层包含两个主要部分:
- 自注意力机制(Self-Attention):帮助模型在处理每个单词时,能够动态地关注输入序列中的其他单词(无论其距离多远)。
- 前馈神经网络(Feedforward Neural Network):对每个位置的表示进行进一步的非线性变换。
编码器的输出是一个上下文相关的表示,用于捕捉输入序列中每个词的语义。
解码器(Decoder)
解码器的任务是生成目标序列(例如翻译任务中的翻译结果)。每个解码器层也包括三个主要部分:
- 自注意力机制(Self-Attention):用于关注生成的部分,确保生成时不会泄露未来的信息(即遮蔽自注意力,Masking)。
- 编码器-解码器注意力(Encoder-Decoder Attention):解码器通过与编码器的输出交互,获取输入序列的相关信息。
- 前馈神经网络(Feedforward Neural Network):对解码器的输出进行非线性转换,生成最终的结果。
2. 核心机制:自注意力(Self-Attention)
Transformer 模型的核心创新之一是 自注意力机制(Self-Attention),该机制允许模型在处理某个词时,能够关注输入序列中其他所有词的信息,而不是仅仅依赖于固定窗口的局部信息。这使得 Transformer 在处理长距离依赖的任务时比传统的 RNN 和 LSTM 更具优势。
自注意力计算: 每个输入单词(或词向量)会与其他所有单词的表示进行比较,通过计算它们的相似度来调整其在当前词表示中的权重,从而获得对该单词的上下文理解。具体计算包括:
-
- Query(查询)
- Key(键)
- Value(值)
通过将输入嵌入与 Query、Key 和 Value 进行内积操作,计算 Attention Scores,从而获取每个词在序列中其他词的权重。
Scaled Dot-Product Attention: 自注意力的计算采用了 缩放点积注意力(Scaled Dot-Product Attention),通过计算查询和键的点积,并进行缩放来避免梯度消失。
3. 多头注意力机制(Multi-Head Attention)
为了提高模型捕捉不同语义关系的能力,Transformer 采用了 多头注意力机制。通过将 自注意力机制 分成多个头(head),每个头可以关注序列中的不同部分或不同类型的关系,从而得到更多的上下文信息。
Transformer 流程
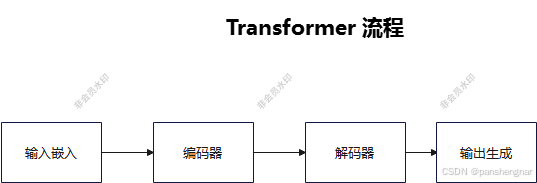
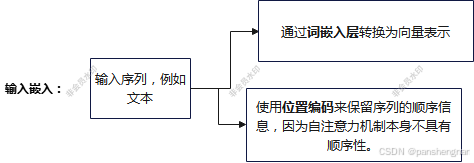


输入嵌入(Embedding):
-
- 输入序列(如文本)首先通过词嵌入层转换为向量表示。
- Transformer 使用位置编码(Position Encoding)来保留序列的顺序信息,因为自注意力机制本身不具有顺序性。
编码器(Encoder):
-
- 编码器由多个相同的层堆叠而成,每一层包含两个主要组件:自注意力层和前馈神经网络。
- 输入序列中的每个词向量会在每层进行自注意力计算,逐步生成更加丰富的上下文表示。
解码器(Decoder):
-
- 解码器同样由多个层组成,每层包括自注意力层、与编码器的交互层以及前馈神经网络。
- 解码器的任务是根据编码器的输出生成目标序列,例如在翻译任务中生成翻译结果。
- 解码器在自注意力机制中加入了遮蔽操作,确保每个生成的词只能依赖于之前的词。
输出生成:
-
- 解码器最终生成的输出向量通过 softmax 层 转化为具体的词或标记,形成最终的输出序列。
Transformer 的优势
并行化:由于 Transformer 不依赖于序列的顺序处理(不像 RNN 那样逐步计算),因此能够更高效地进行并行计算,提升了训练速度。
长距离依赖:自注意力机制可以捕捉序列中任意位置的依赖关系,不会受到 RNN 中长期依赖问题的限制。
灵活性:Transformer 适用于多种序列任务,包括文本生成、翻译、分类、问答等,且可以通过预训练(如 BERT、GPT 等)在多个任务上进行迁移学习。
Transformer 的应用
Transformer 在自然语言处理领域已经取得了巨大的成功,成为了多种任务的主流模型。其主要应用包括:
- 机器翻译:Transformer 在机器翻译任务中表现优异,像 Google Translate 就使用了基于 Transformer 的模型。
- 文本生成:如 GPT 和 T5 等模型,通过预训练和微调可以用于生成文本、对话等任务。
- 文本分类:基于 Transformer 的模型(如 BERT)广泛应用于情感分析、新闻分类等任务。
- 信息检索与问答系统:例如 BERT 在开放域问答和信息检索任务中的应用。
- 语言理解和推理:例如 RoBERTa 和 ALBERT 在自然语言理解任务中的应用。
总结
Transformer 模型通过 自注意力机制 彻底改变了序列数据的处理方式,相比传统的 RNN 和 LSTM,具有 更高的并行性 和 更强的捕捉长距离依赖 的能力。其编码器-解码器架构使得 Transformer 在机器翻译、文本生成、问答等任务中都取得了显著的成绩。
Transformers:
核心组件:Transformers 使用了 自注意力机制(Self-Attention),它能够有效捕捉文本中不同位置的依赖关系,无论这些位置之间的距离有多远。这使得 Transformer 模型特别适合处理长距离依赖的语言任务。
Transformer 的优势:由于自注意力机制,Transformer 不像 RNN 或 LSTM 那样需要按顺序处理输入,可以并行化处理,因此在训练效率和处理长文本方面具有优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









