







Redis可重入锁的核心流程--可重入锁的加锁机制
(1)相同线程重复加锁-重入加锁
我们继续看下执行加锁的脚本:
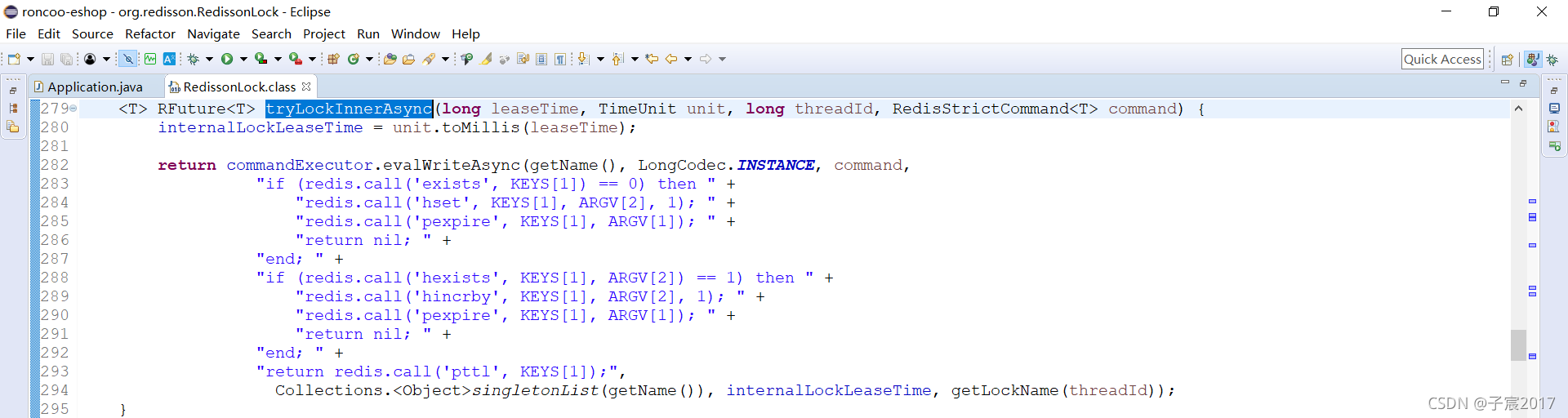
记得第一次加锁时,key是不存在的,所以那时我们才能成功将当前线程的信息、设置到key的hash数据结构中,表示当前线程已经加锁成功。
但是现在是相同线程再次过来对同一key加锁,那么key已经存在这个条件当然就不成立了,接下来就到下一个if分支。
下一个if分支逻辑为:
hexists anyLock UUID:ThreadId
也就是判断当前key是否被当前线程持有,因为是相同的线程再次对同一个key加锁,此时当然能够在key中的hash数据结构中找到记录,所以条件成立,执行如下指令:
hincrby KEYS[1] ARGV[2] 1 即 hincrby anyLock UUID:ThreadId 1
表示对anyLock这个key中的hash数据结构里面的UUID:ThreadId的value增加1
从:
anyLock {
UUID:ThreadId 1
}变为:
anyLock {
UUID:ThreadId 2
}然后再对key重置过期时间为30s
看到这里还记得我们上文留的一个悬念吗,也就是key的hash数据结构中,UUID:ThreadId对应的1到底是什么意思呢?其实就是线程对key加锁的次数;当一个线程第一次过来加锁,线程当然就只是加了一次锁而已,所以对应key中的UUID:ThreadId对应的value值当然就是1;那现在我们看到线程第二次过来对同一个key加锁,那当然就是对应2了,表示当前线程对这个key加了两次锁了,这就是重入加锁。
然后重入锁加成功之后,当然也是后台开启一个watchdog后台线程,每隔10s检查一下key,如果key存在就重置key的过期时间为30s。
这下我们又知道了,原来Redisson可重入加锁的语义,竟然是通过key中某个线程标识UUID:ThreadId对应的加锁次数来表示的。
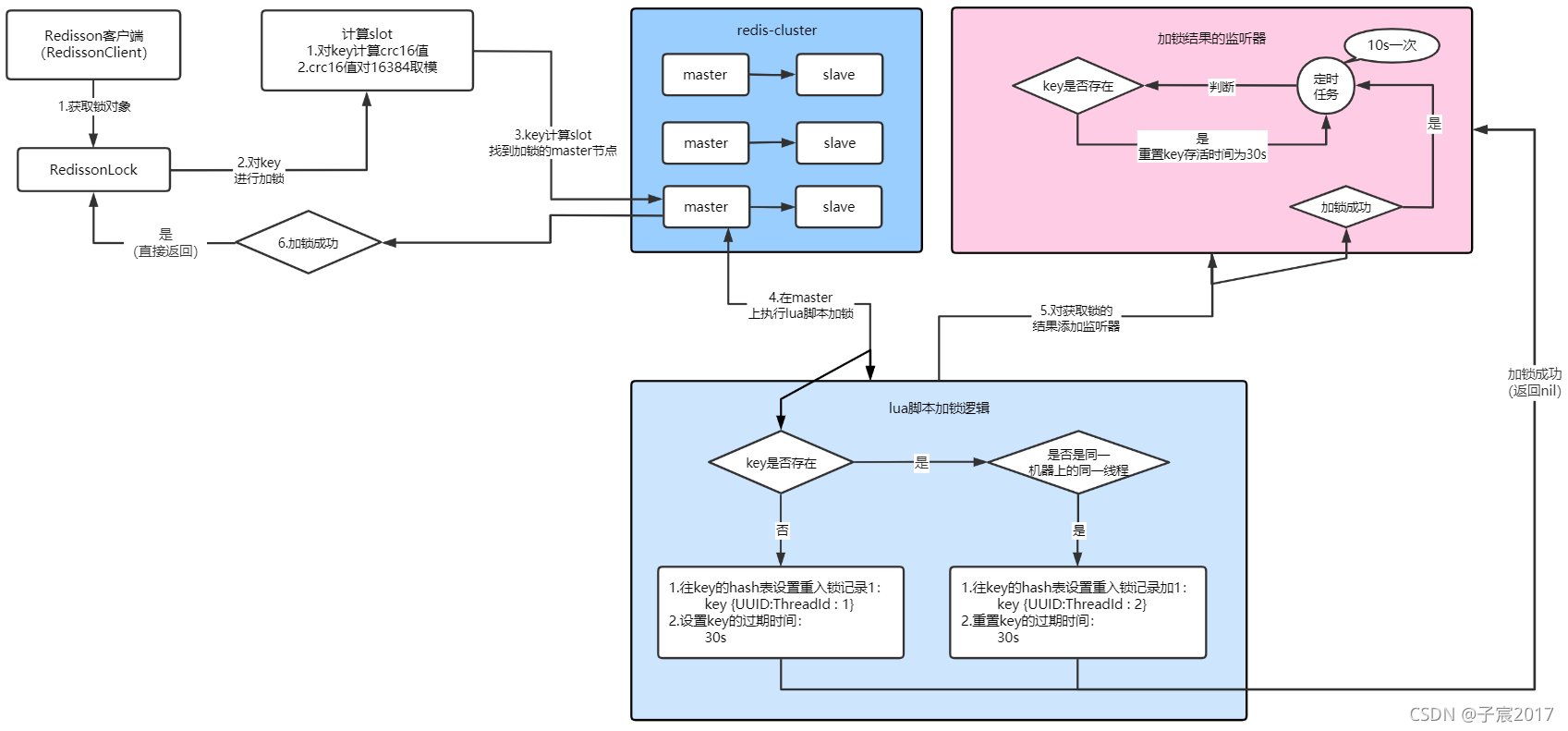
此时整体流程进度如下图所示:
(2)其他线程重复加锁阻塞
其他线程过来加锁时,当然也是要执行这个加锁的脚本,如下图:
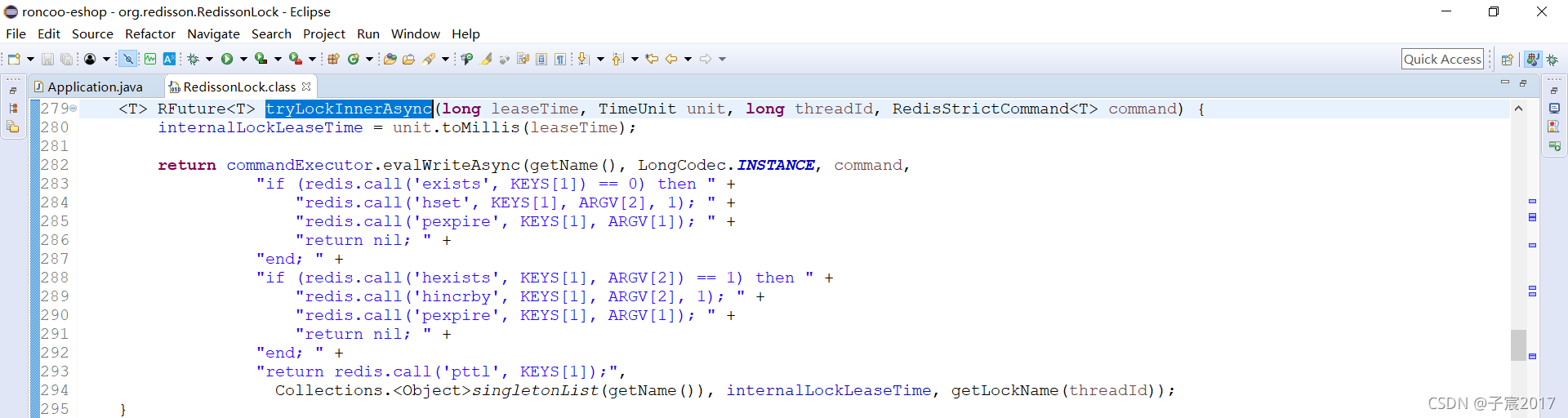
只不过其他线程过来对同一key重复加锁时&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5808
5808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









