




首先介绍1x1卷积核的作用,其次分别引出Inception及Xception的思想
1x1卷积核的作用
1.实现跨通道信息的整合或拆分
首先看一下2x2的卷积核
输入:4x4x3 卷积核:2x2x3x1 输出:3x3x1
2X2的卷积核将图中的12个输入节点组合映射到1个输出节点上。
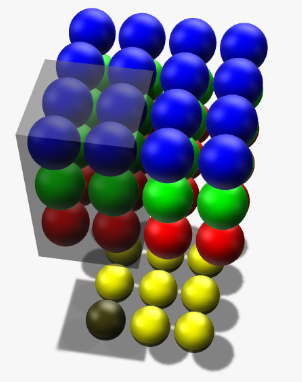
接着看1x1的卷积核
输入:4x4x3 卷积核:1x1x3x2 输出:4x4x2
1x1的卷积核将下面左图中的3个输入节点组合映射到2个输出节点上。

输入:4x4x3 卷积核:1x1x3x4 输出:4x4x4
1x1的卷积核将上面右图中的3个输入节点组合映射到4个输出节点上。
因此,1*1的卷积就是对每个像素点,将多个channels的feature maps线性组合(实现跨通道信息的整合或拆分),当输出channels小于输入channels,即实现了降维(信息整合)。反之则是升维(信息拆分)。
2.大大减少参数数量

上图为Inception模型中,采用1x1卷积核前后的网络结构。
假设输入的feature map是28×28×192,1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32。
对左图,卷积核参数个数为:
1×1×192×64+3×3×192×128+5×5×192×32
而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数个数就变成了:
1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)
参数大约减少到原来的三分之一。
同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的(192),再加卷积层得到的feature map(64+128+32),会使输出的feature map扩大到192+64+128+32=416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了64+128+32+32=256。
再来看一个ResNet中利用1x1卷积核减少参数数量的例子

在训练浅层网络时,我们选用前面这种结构,而如果网络较深(大于50层)时,会考虑使用后面这种(bottleneck),原因主要在减少网络参数。
对于ImageNet而言,进入到第一个residual block的input为 (56,56,64)
采用左侧的两个 3x3的卷积层:
参数量为 :3x3x64x64 + 3x3x64x64 = 73728
采用右侧的bottleneck:
参数量为: 1x1x64x64 + 3x3x64x64 +1x1x256x64 = 57344
Inception
对每个像素点,提取多个 channels的信息并将其压缩到更低的维度。不考虑像素与像素之间的信息整合。
Xception
Xception认为:跨通道的相关性和空间相关性是完全可分离的,最好不要联合映射它们。
它首先对多个feature maps在各自的通道上进行空间上的信息整合,然后采用1x1的卷积核对每个像素点进行跨通道的信息整合。

借此分离了跨通道的相关性和空间相关性。
在 ImageNet 数据集上,Xception 的表现稍稍优于 Inception v3,而且在一个有 17000 类的更大规模的图像分类数据集上的表现更是好得多。最重要的是,它的模型参数的数量和 Inception 一样多,说明它的计算效率也更高。
参考网址:
https://zhuanlan.zhihu.com/p/27642620
http://www.caffecn.cn/?/question/136


















 6974
6974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









