 RAG检索器实现与查询重写
RAG检索器实现与查询重写





1.简介
读的环节,利用它获取最符合,最准的答案
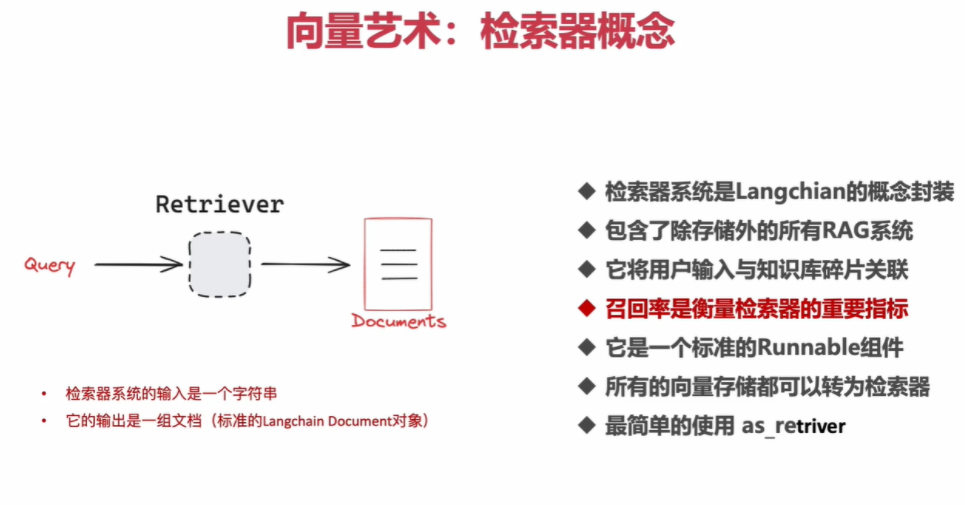
2.使用样例
2.1 简单检索器实现
from langchain_community.document_loaders import TextLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
loader = TextLoader("test.txt",encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings_model = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key='sk-zenbqykvzngjvzeoikvxdplnxbvrjsyntpiejwdefmigzjgb',
base_url="https://api.siliconflow.cn/v1",
)
vectorstore = InMemoryVectorStore.from_documents(texts, embeddings_model)
retriever = vectorstore.as_retriever()
docs = retriever.invoke("deepseek是什么?")
docs
输出:

1.这里首先load test.txt这个文件,文件中含有大量的deepseek的信息
2.切分 和 实例化 嵌入模型后
3 用向量数据库 InMemoryVectorStore 存入资料
4 实例化检索器并匹配相关问题
2.2 查询重写
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load blog post
loader = WebBaseLoader("https://python.langchain.com/docs/how_to/MultiQueryRetriever/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
vectordb = FAISS.from_documents(documents=splits, embedding=embeddings_model)
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_deepseek import ChatDeepSeek
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
api_key=os.getenv('DEEPSEEK_API_KEY'),
api_base=os.getenv('DEEPSEEK_API_BASE')
)
question = "如何让用户查询更准确?"
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
unique_docs = retriever_from_llm.invoke(question)
print(unique_docs)
len(unique_docs)
输出:

此处用了 FAISS向量数据库 来实现查询重写
可以从输出结果看到 用户的问题重写成 这3个问题
- 有哪些方法可以提高用户查询的精准度? '
- 在搜索系统中,优化用户查询准确性的策略有哪些?
- 如何通过技术手段改进用户搜索的精确性?
并找到了 10个相关的文档碎片


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











