



今天整体把transformer框架学习了遍,但代码没有细看。
注意力机制有三个核心变量:Query(查询值)、Key(键值)和 Value(真值)。
注意力机制核心公式:attention(Q,K,V)=softmax(QKTdk)V
自注意力
注意力机制的本质是对两段序列的元素依次进行相似度计算,寻找出一个序列的每个元素对另一个序列的每个元素的相关度,然后基于相关度进行加权,即分配注意力。而这两段序列即是我们计算过程中 Q、K、V 的来源。
在经典的 注意力机制中,Q 往往来自于一个序列,K 与 V 来自于另一个序列,都通过参数矩阵计算得到,从而可以拟合这两个序列之间的关系。例如在 Transformer 的 Decoder 结构中,Q 来自于 Decoder 的输入,K 与 V 来自于 Encoder 的输出,从而拟合了编码信息与历史信息之间的关系,便于综合这两种信息实现未来的预测。
但在 Transformer 的 Encoder 结构中,使用的是 注意力机制的变种 —— 自注意力(self-attention,自注意力)机制。所谓自注意力,即是计算本身序列中每个元素对其他元素的注意力分布,即在计算过程中,Q、K、V 都由同一个输入通过不同的参数矩阵计算得到。在 Encoder 中,Q、K、V 分别是输入对参数矩阵 Wq、Wk、Wv 做积得到,从而拟合输入语句中每一个 token 对其他所有 token 的关系。
掩码自注意力
掩码自注意力,即 Mask Self-Attention,是指使用注意力掩码的自注意力机制。掩码的作用是遮蔽一些特定位置的 token,模型在学习的过程中,会忽略掉被遮蔽的 token。
使用注意力掩码的核心动机是让模型只能使用历史信息进行预测而不能看到未来信息。使用注意力机制的 Transformer 模型也是通过类似于 n-gram 的语言模型任务来学习的,也就是对一个文本序列,不断根据之前的 token 来预测下一个 token,直到将整个文本序列补全。
<BOS> 【MASK】【MASK】【MASK】【MASK】
<BOS> I 【MASK】 【MASK】【MASK】
<BOS> I like 【MASK】【MASK】
<BOS> I like you 【MASK】
<BOS> I like you </EOS>
在每一行输入中,模型仍然是只看到前面的 token,预测下一个 token。但是注意,上述输入不再是串行的过程,而可以一起并行地输入到模型中,模型只需要每一个样本根据未被遮蔽的 token 来预测下一个 token 即可,从而实现了并行的语言模型。解决了不能并行的问题。
多头注意力
注意力机制可以实现并行化与长期依赖关系拟合,但一次注意力计算只能拟合一种相关关系,单一的注意力机制很难全面拟合语句序列里的相关关系。因此 Transformer 使用了多头注意力机制(Multi-Head Attention),即同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系,将最后的多次结果拼接起来作为最后的输出,即可更全面深入地拟合语言信息。
所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理;然后再将每一组得到的自注意力结果拼接起来,再通过一个线性层进行处理,得到最终的输出。
Encoder-Decoder
Seq2Seq 模型
Seq2Seq,即序列到序列,是一种经典 NLP 任务。具体而言,是指模型输入的是一个自然语言序列 input=(x1,x2,x3...xn) ,输出的是一个可能不等长的自然语言序列 output=(y1,y2,y3...ym) 。事实上,Seq2Seq 是 NLP 最经典的任务,几乎所有的 NLP 任务都可以视为 Seq2Seq 任务。例如文本分类任务,可以视为输出长度为 1 的目标序列(如在上式中 m = 1);词性标注任务,可以视为输出与输入序列等长的目标序列(如在上式中 m = n )。
机器翻译任务即是一个经典的 Seq2Seq 任务,例如,我们的输入可能是“今天天气真好”,输出是“Today is a good day.”。Transformer 是一个经典的 Seq2Seq 模型,即模型的输入为文本序列,输出为另一个文本序列。事实上,Transformer 一开始正是应用在机器翻译任务上的。
对于 Seq2Seq 任务,一般的思路是对自然语言序列进行编码再解码。所谓编码,就是将输入的自然语言序列通过隐藏层编码成能够表征语义的向量(或矩阵),可以简单理解为更复杂的词向量表示。而解码,就是对输入的自然语言序列编码得到的向量或矩阵通过隐藏层输出,再解码成对应的自然语言目标序列。通过编码再解码,就可以实现 Seq2Seq 任务。
前馈神经网络
前馈神经网络(Feed Forward Neural Network,下简称 FFN),也就是我们在上一节提过的每一层的神经元都和上下两层的每一个神经元完全连接的网络结构。每一个 Encoder Layer 都包含一个上文讲的注意力机制和一个前馈神经网络。
Transformer 的前馈神经网络是由两个线性层中间加一个 RELU 激活函数组成的,以及前馈神经网络还加入了一个 Dropout 层来防止过拟合。
层归一化
层归一化,也就是 Layer Norm,是深度学习中经典的归一化操作。神经网络主流的归一化一般有两种,批归一化(Batch Norm)和层归一化(Layer Norm)。
归一化核心是为了让不同层输入的取值范围或者分布能够比较一致。由于深度神经网络中每一层的输入都是上一层的输出,因此多层传递下,对网络中较高的层,之前的所有神经层的参数变化会导致其输入的分布发生较大的改变。也就是说,随着神经网络参数的更新,各层的输出分布是不相同的,且差异会随着网络深度的增大而增大。但是,需要预测的条件分布始终是相同的,从而也就造成了预测的误差。
残差连接
由于 Transformer 模型结构较复杂、层数较深,为了避免模型退化,Transformer 采用了残差连接的思想来连接每一个子层。残差连接,即下一层的输入不仅是上一层的输出,还包括上一层的输入。残差连接允许最底层信息直接传到最高层,让高层专注于残差的学习。
例如,在 Encoder 中,在第一个子层,输入进入多头自注意力层的同时会直接传递到该层的输出,然后该层的输出会与原输入相加,再进行标准化。在第二个子层也是一样。
Encoder
在实现上述组件之后,我们可以搭建起 Transformer 的 Encoder。Encoder 由 N 个 Encoder Layer 组成,每一个 Encoder Layer 包括一个注意力层和一个前馈神经网络。
Decoder
类似的,我们也可以先搭建 Decoder Layer,再将 N 个 Decoder Layer 组装为 Decoder。但是和 Encoder 不同的是,Decoder 由两个注意力层和一个前馈神经网络组成。第一个注意力层是一个掩码自注意力层,即使用 Mask 的注意力计算,保证每一个 token 只能使用该 token 之前的注意力分数;第二个注意力层是一个多头注意力层,该层将使用第一个注意力层的输出作为 query,使用 Encoder 的输出作为 key 和 value,来计算注意力分数。最后,再经过前馈神经网络
Embedding 层
正如我们在第一章所讲过的,在 NLP 任务中,我们往往需要将自然语言的输入转化为机器可以处理的向量。在深度学习中,承担这个任务的组件就是 Embedding 层。Embedding 层其实是一个存储固定大小的词典的嵌入向量查找表。我们往往会先让自然语言输入通过分词器 tokenizer,分词器的作用是把自然语言输入切分成 token 并转化成一个固定的 index。
位置编码
注意力机制可以实现良好的并行计算,但同时,其注意力计算的方式也导致序列中相对位置的丢失。在 RNN、LSTM 中,输入序列会沿着语句本身的顺序被依次递归处理,因此输入序列的顺序提供了极其重要的信息,这也和自然语言的本身特性非常吻合。
但从上文对注意力机制的分析我们可以发现,在注意力机制的计算过程中,对于序列中的每一个 token,其他各个位置对其来说都是平等的,即“我喜欢你”和“你喜欢我”在注意力机制看来是完全相同的,但无疑这是注意力机制存在的一个巨大问题。因此,为使用序列顺序信息,保留序列中的相对位置信息,Transformer 采用了位置编码机制,该机制也在之后被多种模型沿用。
位置编码,即根据序列中 token 的相对位置对其进行编码,再将位置编码加入词向量编码中。位置编码的方式有很多,Transformer 使用了正余弦函数来进行位置编码(绝对位置编码Sinusoidal),
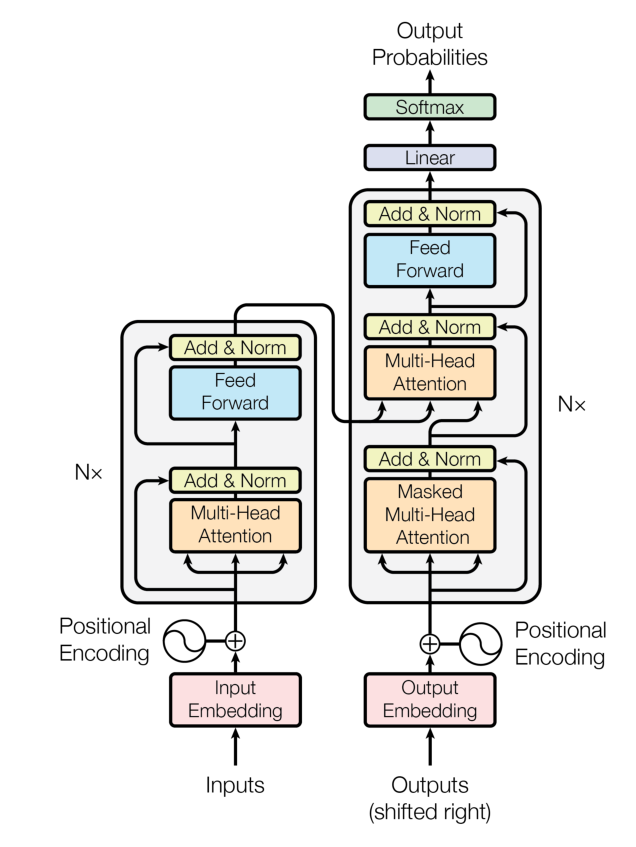
上述即一个完整的transformer框架。代码细节还没仔细了解,这周先整体过一遍


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









