




为了解决多事务并发问题(脏写、脏读、不可重复读、幻读),数据库设计了锁机制、事务隔离机制、多版本并发控制机制(MVCC),用一整套机制来解决多事务并发问题。锁机制在前面的文章已经记录过,本文主要记录 事务隔离机制 和 MVCC 机制。
一、事务
1. 事务的四大特性(ACID)
事务是由一组 SQL 语句组成的逻辑处理单元,事务具有以下 ACID 4个属性:
- 原子性(Atomicity) :一个事务就是一个原子操作单元,事务内部对数据的修改,要么全部执行,要么全部不执行。
- 一致性(Consistent) :事务执行前后数据从一个有效状态转变到另一个有效状态(业务规则有效、数据约束有效、数据完整有效)
- 隔离性(Isolation) :事务在执行时,仿佛 “独立” 存在一样,不会受到其他并发事务的影响。
- 持久性(Durable) :事务完成之后,数据的修改是永久性的。
2. 并发事务引发的问题
当有并发事务发生时,会引发 脏读、脏写、不可重复读、幻读这些问题。
1. 脏读(Dirty Reads)
事务 A 读取到了 事务 B 已经修改但尚未提交的数据。如果此时 事务 A 在这个数据基础上做了操作,同时 事务B 进行了回滚,那么 事务 A 对数据的操作结果就有问题。
2. 更新丢失(Lost Update)或 脏写(Dirty Write)
当多个事务并发对同一行数据进行更新时,由于不知道其他事务的存在,所以都是基于最初值更新,这样后提交的更新就会覆盖先提交的更新。
3. 不可重读(Non-Repeatable Reads)
事务 A 内部的相同查询语句,在不同时刻读出的结果不一致。
4. 幻读(Phantom Reads)
事务 A 读取到了 事务 B 提交的新增数据。
3. 事务隔离解决并发事务问题
MySQL 中事务有 4 种隔离级别可以选择,分别用来解决不同的事务并发问题。
不同隔离级别的表现
- 读未提交(READ UNCOMMITTED):在事务内查询时可以查到其他事务已经修改但未提交的数据。
- 读已提交(READ COMMITTED): 在事务内查询时可以查到其他事务已经修改且已提交的数据。
- 可重复读(REPEATABLE READ):在事务内第一次查询时会生成快照,之后每次查询都从快照中读取,每次的查询结果不会受到其他事务影响。修改操作时当前事务内的修改会在最新已提交的数据(包括其他事务的提交)上进行,并更新快照。
- 可串行化(SERIALIZABLE):事务内的每条 SQL 都会被加上行锁,查询操作加共享锁,修改操作加排他锁,以保证各个事务对同一条数据的操作串行执行。
4 种隔离级别对事务并发问题的解决:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | 未解决 | 未解决 | 未解决 |
| 读已提交(READ COMMITTED) | 解决 | 未解决 | 未解决 |
| 可重复读(REPEATABLE READ) | 解决 | 解决 | 未解决 |
| 可串行化(SERIALIZABLE) | 解决 | 解决 | 解决 |
上面隔离级别依次严格,越严格的隔离级别并发性能则越低,但是能更好的保证一致性。MySQL 默认的隔离级别是可重复读。
MySQL 中查询当前事务隔离级别:SELECT @@[session|global].transaction_isolation;
MySQL 中设置事务隔离级别:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE];
二、多版本并发控制(MVCC)
1. 简单理解 MVCC 机制
在 MySQL 的可串行化隔离级别中,针对同一条数据,是通过加锁互斥来保证隔离性的。在可重复读隔离级别中,针对同一条数据,每次查询的结果都相同,是通过 多版本并发控制机制 MVCC 来实现的,MVCC 机制不会为查询 SQL 添加共享锁,所以多个事务对同一条数据的读写可以同时进行,并发性能更高。
在简单理解 MVCC 机制时,通常会用两个概念 快照读 和 当前读:
- 快照读:第一次查询后会生成一个快照,之后每次查询都会读取这个快照中的内容,所以每次查询的数据都相同。
- 当前读:当修改数据时,修改的是当前数据库表中最新的数据(包括其他事务提交),之后还会更新快照中的内容
2. 深度理解 MVCC 机制
在深度理解 MVCC 机制时,就必须明白 MVCC 底层原理。(读已提交和可重复读两个级别都是用 MVCC 实现的,但是实现原理有一点点不同,本文主要记录 可重复读级别 下的实现原理)。
首先 MVCC 机制会依赖 undo 日志,对一条数据的每一次更新都会在 undo 日志中生成一条记录。记录中包括:更新的数据行、事务ID(trx_id)、回滚指针 (roll_pointer)、是否提交(is_commited)
当对同一条数据多次修改后,通过 回滚指针,可以形成一个版本链,称作 undo 日志版本链,类似下图:
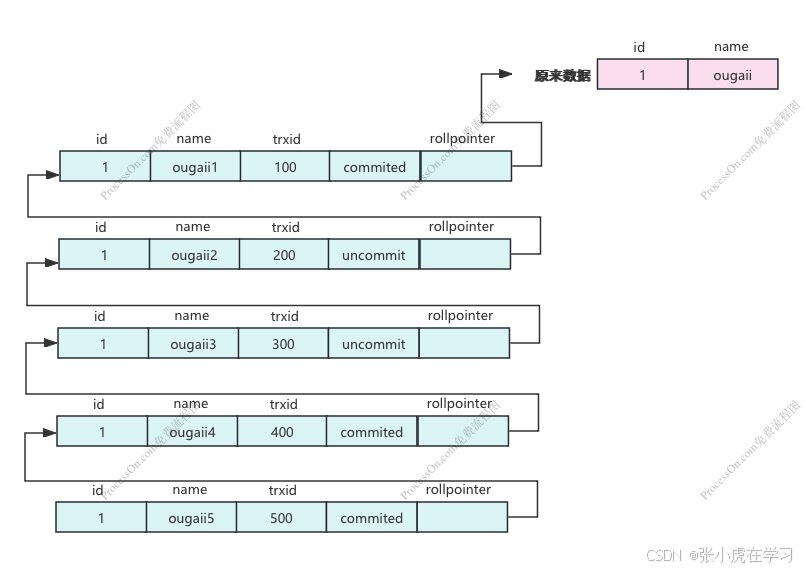
然后在开启事务并首次查询时,MySQL 会根据 undo 日志版本链生成一个 read-view,read-view 的内容为当前 所有未提交的 事务id 数组 和 已经生成的最大的 事务id。以图中的版本链为例,read-view 为 ([200,300], 500)
最后,在之后的每次查询时,MySQL 会通过可见性分析算法,用版本链中的事务ID(从最新到最早)依次和 read-view 的内容进行比较,来断定要显示的记录。可见性分析算法规则如下:
- 当版本链中的事务ID,小于 read-view 中 数组里的最小值时,代表是生成 read-view 之前就已经提交的记录,所以可见。
- 当版本链中的事务ID,大于 read-view 中 不是数组的那个 事务 ID 时,代表是生成 read-view 之后新的事务,所以不可见
- 当版本链中的事务ID,在 read-view 的数组中时,代表生成 read-view 时这些记录还未提交,所以不可见。
- 当版本链中的事务ID,等于 read-view 中 不是数组的那个 事务 ID 时,代表生成 read-view 时已提交,所以可见。


















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









