







基于 CUDA:12.4.1 、Ubuntu 22.04 搭建一个 VLLM的可用环境,用于推理加速。
直接安装
## 清空
pip uninstall vllm
pip uninstall transformers
#安装
pip install 'vllm==0.6.4' --extra-index-url https://download.pytorch.org/whl/cu124
参考文件:https://www.cnblogs.com/fasterai/p/18551208
docker 安装
安装nvidia-container-toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
## 重启docker
sudo systemctl enable docker
sudo systemctl restart docker
验证
参考文件:https://blog.youkuaiyun.com/mzl_18353516147/article/details/142653400
# 方法1
nvidia-container-runtime --version
# 方法2
cat /etc/docker/daemon.json
#确保存在
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
拉取镜像
此材料里的组件信息
vLLM:0.6.4
Python:3.10
PyTorch:2.4.0
CUDA:12.4.1
基础镜像:Ubuntu 22.04
基于阿里云这个镜像制作新版的vllm镜像。
运行镜像
## 运行
docker run -d -t --net=host --gpus '"device=2,3"' \
--ipc=host \
--name vllm-12.4 \
-v /home/root/.cache/modelscope:/root/.cache/modelscope \
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.5.4-pytorch2.4.0-cuda12.4.1-ubuntu22.04
验证
本测试以Llama-2-7b模型为例,展示使用vLLM的推理效果。
- 执行以下命令,下载modelscope格式的Llama-2-7b模型。
sudo su
cd /root
git-lfs clone https://www.modelscope.cn/shakechen/Llama-2-7b-hf.git
- 执行以下命令,进入vLLM容器。
docker exec -it vllm bash
- 执行以下命令,测试vLLM的推理效果。
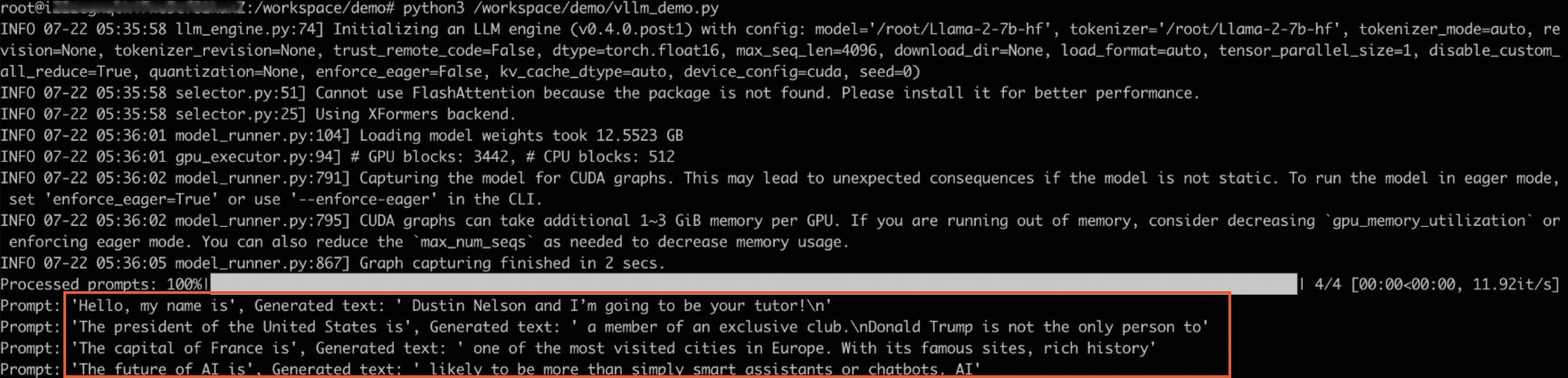
python3 /workspace/demo/vllm_demo.py
例如可以快速地处理对话问答任务,推理示例如下:
启动openai格式服务器
启动
简单启动
vllm serve /root/.cache/modelscope/hub/qwen/Qwen2-VL-7B-Instruct-GPTQ-Int8 --device cuda --dtype auto
生产启动(需要关注张量并行)
vllm serve /root/.cache/modelscope/hub/qwen/Qwen2___5-72B-Instruct-AWQ --device cuda --dtype auto --tensor_parallel_size 2 --distributed-executor-backend mp
测试命令
curl -X POST http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer not_empty" -d '{
"model": "/root/.cache/modelscope/hub/qwen/Qwen2___5-72B-Instruct-AWQ",
"messages": [
{
"content": "你好",
"role": "user"
}
]
}'

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









