




 本文探讨了Linux环境下,从原始阶段到应用接管设备驱动的三个阶段的IO性能优化过程,详细解析了zero-copy技术在不同阶段的应用及其实现原理,对比了各阶段的优缺点。
本文探讨了Linux环境下,从原始阶段到应用接管设备驱动的三个阶段的IO性能优化过程,详细解析了zero-copy技术在不同阶段的应用及其实现原理,对比了各阶段的优缺点。
背景
企业对生产环境的服务器产出要求越来越高,压榨IO是常有的事情,但是,当万兆网卡、SSD等设备用上了,性能却不一定随着硬件性能线性增长而增长。linux诞生之初是朝着一个稳定的操作系统演进的,这个初衷导致很多硬件上的特性无法完全释放出来。
下面分几个阶段,聊一下其演进和对比一下优缺点。
原始阶段
以一个web服务器发送文件为例子,看一下数据流动:
- 内核读取磁盘的文件到磁盘缓冲区
- APP从把内核态的磁盘缓存读取到用户态的缓存
- APP把用户态的缓存写到内核态的网卡缓存
- 内核把网卡缓存写入网卡
大部分web应用的工作方式基本停留在这个阶段。
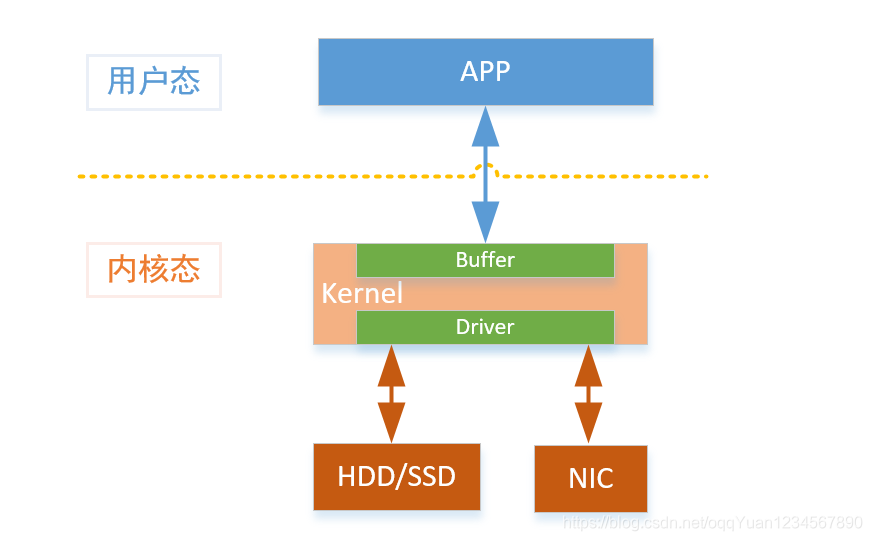
第二阶段,依赖内核机制的zero-copy
以Nginx和Kafka为代表的充分利用内核zero-copy数据的方案
同样以一个web服务器发送文件为例子,看一下数据流动:
- 内核读取磁盘的文件到磁盘缓冲区
- APP调用sendfile/splice函数,让内核从把磁盘缓存写到网卡缓存
- 内核把网卡缓存写入网卡
这里把阶段一的第2/3步压缩成一步,减少了一次复制,达到提升效率的目的。
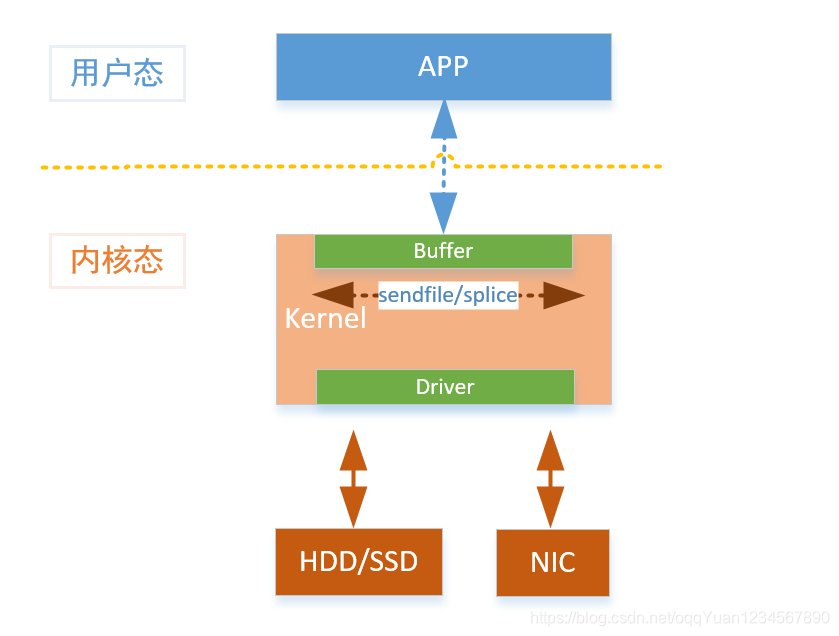
第三阶段,应用接管设备驱动实现的zero-copy
这里还是借用zero-copy的概念,但是已经不是传统意义上的zero-copy了。
以aerospike、DPDK、f-stack项目为代表的绕开内核限制,直接接管驱动的暴力手段,全面压榨设备的IO。
同样以一个web服务器发送文件为例子,以dpdk的角度,看一下数据流动:
- APP读取磁盘的文件到APP的缓冲区
- AP把缓存区的内容写到网卡
很暴力,这还是一个简单的发送功能!!DPDK模式下,CPU跑满轮询网卡,一旦有数据来就应用就可以马上收到,构建超低延时的应用就此诞生。
几个阶段的特性对比
| 优点 | 缺点 | 代表项目 | |
|---|---|---|---|
| 第一阶段 | 开发简单 | 性能无法完全释放 | |
| 第二阶段 | 性能能释放一部分,开发比较简单 | kafka、nginx | |
| 第三阶段 | 性能完全释放 | 开发困难,原有的性能监控工具、调试工具可能无法使用 | DPDK、f-stack |
一般的公司/团队,应该都是停留在第一第二阶段,第三阶段,估计就只有大厂有能力去维护了。

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









