




 openLooKeng v1.4.1 引入了OmniData Connector,旨在减少数据存储层和计算层之间的数据传输,通过算子下推实现近数据计算,提升大数据计算性能。OmniData支持HDFS和S3的存储访问,兼容TXT、ORC、Parquet格式,并且在TaiShan服务器上支持鲲鹏处理器。此外,新版本还优化了ARM架构下对JDK的支持。
openLooKeng v1.4.1 引入了OmniData Connector,旨在减少数据存储层和计算层之间的数据传输,通过算子下推实现近数据计算,提升大数据计算性能。OmniData支持HDFS和S3的存储访问,兼容TXT、ORC、Parquet格式,并且在TaiShan服务器上支持鲲鹏处理器。此外,新版本还优化了ARM架构下对JDK的支持。
前言
前不久,在Hadoop、openLooKeng联合发起的Apache Hadoop Meetup 2021上,社区 PMC 主席 Ken Zhang 分享了主题:openLooKeng and the technical trend of big data(点此回顾),其中OmniRuntime 受到不少朋友的关注。11月12日,openLooKeng v1.4.1正式上线。除了对旧版本进行一些优化外,v1.4.1版本还引入了OmniData Connector。作为OmniRuntime的组件之一,OmniData 有什么作用?小助手将为大家娓娓道来。
关于 OmniData
OmniData 算子下推特性,适用于大数据存算分离场景或大规模融合部署场景。当大量计算节点从存储节点读取数据时,大量原始数据从存储节点通过网络传输到计算节点进行处理,有效数据占比低,极大浪费网络带宽。OmniData旨在减少数据存储层和计算层之间的数据传输。
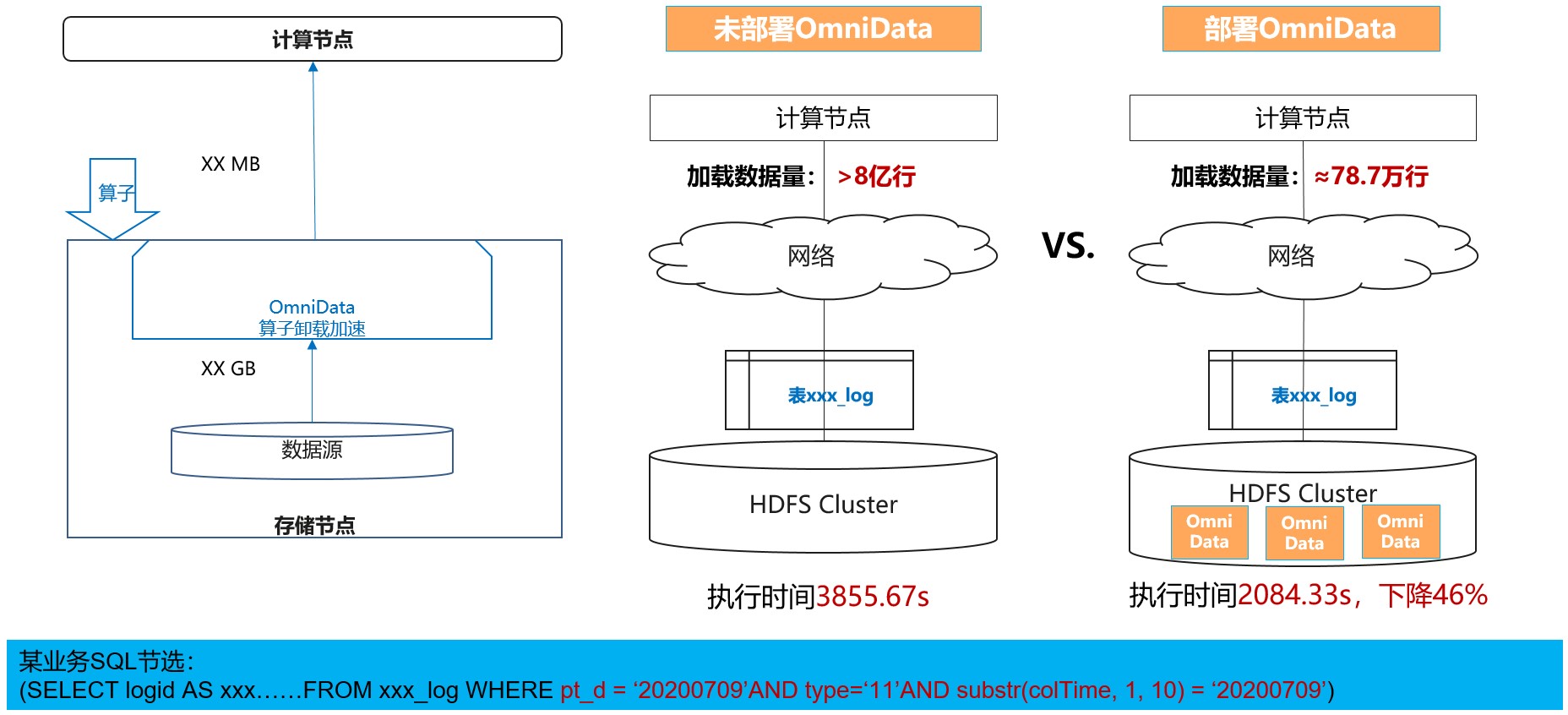
此外,OmniData算子下推特性将计算侧的Filter、Aggregation、Limit算子下推到存储节点执行,实现近数据计算,并利用多样算力缓解计算侧CPU的压力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









