




摘要:先搞懂 “ABE 是什么、为什么需要”,再深入 “技术原理→分类演进→应用趋势”,层层递进不跳步,兼顾通俗性与技术深度。

一、先搞懂基础:ABE 是什么?为什么必须有它?
1. ABE 的通俗定义
基于属性的加密(Attribute-Based Encryption,ABE)是一种 “按‘身份标签’控制数据访问” 的加密技术 —— 简单说,它不像传统加密 “一把钥匙开一把锁”,而是像 “景区门票”:只有同时满足 “门票类型(如成人票)+ 有效期(如当天)+ 园区范围(如 A 区)” 这些 “属性”,才能进入对应区域。
这里的 “属性” 可以是任何描述信息:
- 个人属性:部门 = 研发、职称 = 经理、角色 = 管理员;
- 动态属性:时间 = 工作日 9:00-18:00、位置 = 公司内网;
- 数据属性:文件类型 = 敏感、年份 = 2025。
数据拥有者只需设定 “访问规则”(如 “研发部且经理级”),符合规则的用户就能解密,无需为每个用户单独生成密钥。
2. 为什么传统加密不行?ABE 的核心价值
传统加密面对 “多用户、细粒度权限” 场景时,会陷入两大死穴,而 ABE 正好解决:
|
加密类型 |
核心问题(举例:100 人访问研发部敏感文档) |
ABE 的解决方式 |
|
对称加密(如 AES) |
需管理 100 把密钥,员工离职要回收 100 把,密钥分发还需额外安全通道 |
仅生成 1 套 “规则密钥”,员工凭 “属性” 解密,离职只需注销属性 |
|
非对称加密(如 RSA) |
需生成 100 份密文(1 人 1 份),文档更新要重新加密 100 次,存储成本爆炸 |
仅生成 1 份密文(绑定规则),100 人凭符合规则的 “属性私钥” 解密,更新无需重加密 |
真实场景痛点:某医院 2000 名员工,心内科病历需 “心内科医生 + 患者授权” 才能看,急诊科医生仅会诊时可临时访问 —— 传统加密要么 “全员能看(不安全)”,要么 “为每个医生生成密钥(管理疯掉)”,而 ABE 用 “规则 + 属性” 完美适配,这就是它的不可替代性。
二、核心技术原理:ABE 如何实现 “属性控权限”?
ABE 的底层依赖两大技术:密码学基础(双线性对 / 格密码) 和规则执行组件(LSSS 线性秘密共享),缺一不可。以下从 “基础组件→完整流程” 拆解:
1. 密码学基础:ABE 的 “数学基石”
(1)传统 ABE 的基石:双线性对(Bilinear Pairing)
双线性对是传统 KP-ABE/CP-ABE 实现 “属性 - 规则匹配” 的核心,通俗理解是 “把两个群的运算,映射到第三个群,且满足‘乘法分配律’”。
数学定义:
设\(G_1\)、\(G_2\)是阶为素数\(p\)的循环群(可理解为 “数字集合”),\(g\)是\(G_1\)的生成元(类似 “单位元”),双线性映射\(e: G_1 \times G_1 \rightarrow G_2\)需满足 3 个条件:
- 双线性:对任意\(a,b \in \mathbb{Z}_p^*\)(\(p\)的余数集合),有\(e(g^a, g^b) = e(g,g)^{ab}\);
- 非退化性:\(e(g,g) \neq 1_{G_2}\)(\(1_{G_2}\)是\(G_2\)的单位元,确保映射不失效);
- 可计算性:存在高效算法,能快速计算\(e(u,v)\)(\(u,v \in G_1\))。
在 ABE 中的作用:
比如 CP-ABE 加密时,会生成 “带规则的密文” 和 “带属性的私钥”,双线性对负责验证 “私钥属性是否满足密文规则”:
- 加密端:用规则生成\(C = e(g,g)^s \cdot M\)(\(s\)是秘密值,\(M\)是原始数据);
- 解密端:若属性满足规则,可通过私钥计算出\(e(g,g)^s\),再用\(C / e(g,g)^s\)恢复\(M\);
- 关键:只有属性匹配时,才能算出\(e(g,g)^s\),否则无法解密 —— 这就是 “属性控权限” 的数学本质。
(2)抗量子 ABE 的基石:格密码(Ring-LWE)
传统双线性对易被量子计算机破解(Shor 算法可解离散对数问题),而格密码基于 “格中最短向量问题(SVP)”,是公认的抗量子技术。
通俗理解 “格”:
\(n\)维格是\(\mathbb{Z}^n\)(\(n\)维整数向量集合)中,由一组 “格基” 向量生成的所有整数线性组合。比如 2 维格,可由两个基向量\((a,b)\)和\((c,d)\)生成无数向量\(x(a,b)+y(c,d)\)(\(x,y\)为整数),类似 “网格”。
Ring-LWE 假设(ABE 抗量子的核心):
设\(R = \mathbb{Z}[x]/(x^n+1)\)(多项式环,可理解为 “多项式集合”),\(q\)为大素数,\(\chi\)是\(R\)上的 “误差分布”(小范围随机数)。给定随机\(a \in R_q\)(\(R\)模\(q\)的集合)和\(b = sa + e\)(\(s \in R_q\)随机,\(e \sim \chi\)),攻击者无法有效区分\(b\)与\(R_q\)中的随机元素 —— 这意味着 “无法从\(b\)反推\(s\)”,保证了秘密值安全。
在抗量子 ABE 中的作用:
用 “格基” 替代双线性对中的\(g\),私钥是 “与属性绑定的格基”,密文是 “与规则绑定的格向量”:
- 加密时:将数据\(M\)与格向量绑定,生成\(C = B_{pub}^s \cdot M\)(\(B_{pub}\)是公格基);
- 解密时:若属性满足规则,私钥的格基可计算出\(B_{pub}^s\),进而恢复\(M\);
- 优势:量子计算机无法在多项式时间内找到格中的最短向量,因此无法破解。
2. 规则执行核心:LSSS 线性秘密共享方案
ABE 能支持 “复杂规则”(如 “5 个属性满足 3 个”“部门 = 研发且(级别≥经理或项目 = 核心)”),全靠 LSSS(Linear Secret Sharing Scheme)—— 它把 “秘密值” 拆成 “属性份额”,只有满足规则的属性集合,才能凑齐份额恢复秘密。
(1)LSSS 的通俗例子:3 人凑钥匙开门
假设秘密是 “门的密码\(s=10\)”,规则是 “3 人中至少 2 人在场”(2-out-of-3 阈值):
- 拆分份额:给 3 人分别分配份额\(\lambda_1=3\)、\(\lambda_2=5\)、\(\lambda_3=2\)(满足\(\lambda_1+\lambda_2=8\)?不对,重新来:用线性方程拆分,比如设\(s = a + b\),取\(a=4\)、\(b=6\),则\(\lambda_1=a=4\)、\(\lambda_2=b=6\)、\(\lambda_3=a+b=10\),任意 2 人份额相加可得到\(s\):\(\lambda_1+\lambda_2=10\),\(\lambda_1+\lambda_3=14\)?不对,正确拆分需满足 “线性组合”,比如用矩阵:
设 LSSS 矩阵\(M = \begin{bmatrix}1 & 0 \\ 0 & 1 \\ 1 & 1\end{bmatrix}\)(3 行 2 列,对应 3 个属性),秘密向量\(v = [s, r] = [10, 3]\)(\(r\)是随机数),则 3 个属性的份额为:
\(\lambda_1 = M_1 \cdot v^T = 1*10 + 0*3 = 10\),
\(\lambda_2 = M_2 \cdot v^T = 0*10 + 1*3 = 3\),
\(\lambda_3 = M_3 \cdot v^T = 1*10 + 1*3 = 13\);
- 恢复秘密:若取属性 1 和 2,找系数\(\omega_1=1\)、\(\omega_2=1\)、\(\omega_3=0\)(满足\(\omega_1M_1 + \omega_2M_2 = [1,0]\)),则\(\omega_1\lambda_1 + \omega_2\lambda_2 = 1*10 + 1*3 = 13\)?不对,正确系数应满足\(\sum \omega_iM_i = [1,0]\),比如\(\omega_1=1\)、\(\omega_2=0\)、\(\omega_3=0\)(仅属性 1)不行,\(\omega_1=1\)、\(\omega_2=1\)、\(\omega_3=-1\):\(1*[1,0] +1*[0,1] -1*[1,1] = [0,0]\),也不对 —— 换个简单理解:LSSS 通过矩阵确保 “满足规则的属性集合,存在一组系数,使份额的线性组合等于秘密\(s\)”,不满足则无法组合。
(2)LSSS 在 CP-ABE 中的实际应用
CP-ABE 的 “访问规则” 本质是 LSSS 矩阵,具体步骤:
- 规则转矩阵:比如规则 “部门 = 研发(A)且(级别≥经理(B)或项目 = 核心(C))”,对应 LSSS 矩阵\(M\)(行对应属性 A、B、C);
- 秘密拆分:加密端生成秘密值\(s\),用\(M\)将\(s\)拆成份额\(\lambda_A, \lambda_B, \lambda_C\);
- 密文生成:密文\(C\)包含 “份额\(\lambda_i\)” 和 “矩阵\(M\)的索引”;
- 解密验证:用户私钥带属性(如 A 和 B),若 A、B 满足规则,可找到系数\(\omega_A, \omega_B\),使\(\omega_A\lambda_A + \omega_B\lambda_B = s\),进而恢复数据\(M\)。
3. ABE 完整算法流程(以 CP-ABE 为例)
结合上述组件,CP-ABE 的 4 步核心流程(含数学细节)如下:
|
步骤 |
执行方 |
输入输出 |
关键操作(以双线性对为例) |
|
1. 初始化(Setup) |
可信机构(TA) |
输入:安全参数\(\lambda\)、属性集合\(U\)输出:公钥\(PK\)、主密钥\(MSK\) |
1. 选\(G_1,G_2,e,p,g\)(双线性对参数);2. 选随机\(α \in \mathbb{Z}_p^*\),设\(MSK = α\);3. 设\(PK = (G_1,G_2,e,p,g, g^α)\)(\(g^α\)是公钥核心); |
|
2. 密钥生成(KeyGen) |
TA + 用户 |
输入:\(PK, MSK, 用户属性S\)输出:私钥\(SK_S\) |
1. 用户提交属性\(S\)(如 {研发,经理});2. TA 选随机\(r \in \mathbb{Z}_p^*\),为每个\(att \in S\)选\(r_{att} \in \mathbb{Z}_p^*\);3. 生成\(SK_S = (D = g^{(α - r)/p}, \{ D_{att} = g^r \cdot H(att)^{r_{att}}, D'_{att} = g^{r_{att}} \} )\)(\(H(att)\)是属性哈希函数); |
|
3. 加密(Encrypt) |
数据拥有者 |
输入:\(PK, 数据M, 访问规则Γ\)(LSSS 矩阵\(M\))输出:密文\(C_Γ\) |
1. 选随机\(s \in \mathbb{Z}_p^*\)(秘密值),生成\(C_0 = e(g,g)^{αs} \cdot M\);2. 用\(M\)拆分\(s\)为份额\(\lambda_i\)(对应矩阵行\(M_i\));3. 为每个份额选\(t_i \in \mathbb{Z}_p^*\),生成\(C_1 = g^s\),\(C_{i,1} = g^{t_i}\),\(C_{i,2} = g^{\lambda_i} \cdot H(att_i)^{t_i}\);4. 输出\(C_Γ = (C_0, C_1, \{C_{i,1}, C_{i,2}\})\); |
|
4. 解密(Decrypt) |
用户 |
输入:\(PK, C_Γ, SK_S\)输出:\(M\)或\(\perp\)(失败) |
1. 检查\(S\)是否满足\(Γ\):若满足,找系数\(\omega_i\)使\(\sum \omega_i M_i = [1,0,...,0]\);2. 计算\(\prod_i e(C_{i,2}, D)^{\omega_i} = e(g,g)^{r s}\);3. 计算\(\prod_i e(C_{i,1}, D_{att_i})^{\omega_i} = e(g,g)^{r s}\);4. 若两者相等,恢复\(M = C_0 / e(C_1, D)\);否则输出\(\perp\); |
三、深入技术分类:两大核心类型及演进细节
ABE 的核心分类是 “密钥策略(KP-ABE)” 和 “密文策略(CP-ABE)”,两者的演进都是从 “功能简单” 到 “支持复杂场景”,细节如下:
1. 第一类:密钥策略属性基加密(KP-ABE)——“数据贴标签,钥匙定规则”
(1)核心逻辑
- 数据端:给数据贴 “属性标签”(如 “文档 = 研发方案 + 年份 = 2025”);
- 用户端:密钥里藏 “访问规则”(如 “研发方案且(2024 或 2025)”);
- 解密条件:数据标签满足密钥规则,就能解密。
(2)技术演进:从 “简单布尔” 到 “支持复杂逻辑”
|
演进阶段 |
时间 |
核心技术细节 |
能解决的问题 |
局限 |
|
初代 KP-ABE |
2005 年 |
基于双线性对,仅支持 “与(AND)、或(OR)” 布尔电路 |
简单分类数据访问(如 “公开文档 + 2025 年”) |
不支持 “阈值逻辑”(如 “3 个属性满足 2 个”),规则复杂时密钥变大 |
|
优化版 KP-ABE |
2010 年 |
引入 “属性树” 结构,支持 “非(NOT)” 和 “阈值门限” |
复杂规则(如 “研发方案且(2025 或 2024)且非测试版”) |
密钥大小随属性数量增长,解密速度变慢 |
|
轻量化 KP-ABE |
2020 年 |
采用 “属性哈希聚合”,将多属性压缩为 1 个哈希值 |
物联网场景(如传感器数据加密,属性多但密钥小) |
哈希可能碰撞(概率极低,需额外验证) |
|
抗量子 KP-ABE |
2024 年 |
基于格密码(Ring-LWE),替代双线性对 |
抵御量子计算机攻击(传统双线性对易被破解) |
计算复杂度略高,需硬件加速支持 |
(3)典型场景
公开数据库分类访问:比如政府公开数据,给数据贴 “民生数据 + 2025”“经济数据 + 2025” 标签,用户密钥规则设 “民生数据且 2025”,就能只访问对应数据,避免无关数据泄露。
2. 第二类:密文策略属性基加密(CP-ABE)——“数据定规则,钥匙带标签”
(1)核心逻辑
- 数据端:加密时直接设 “访问规则”(如 “部门 = 研发且级别≥经理”);
- 用户端:密钥里带 “属性标签”(如 “研发 + 经理”);
- 解密条件:用户属性满足数据规则,就能解密。
(2)技术演进:从 “基础功能” 到 “工业级可用”
CP-ABE 是目前应用最广的类型,演进重点解决 “规则表达能力”“安全性”“效率” 三大问题:
|
演进阶段 |
时间 |
核心技术突破 |
关键改进点 |
落地价值 |
|
初代 CP-ABE |
2007 年 |
首次实现 “数据端定规则”,基于双线性对 |
数据拥有者掌控权限(如医生设定病历访问规则) |
不支持 “策略隐藏”(外人能看到 “哪些属性可访问”),规则复杂时加密慢 |
|
LSSS 增强 CP-ABE |
2012 年 |
引入 “线性秘密共享方案(LSSS)” |
1. 支持复杂阈值逻辑(如 “5 个属性满足 3 个”);2. 解密效率提升 30% |
适合企业复杂权限(如 “项目组 A 且核心成员或经理”) |
|
策略隐藏 CP-ABE |
2018 年 |
对访问规则加密,仅暴露属性索引(不暴露规则内容) |
避免通过规则猜数据敏感程度(如黑客看不到 “需经理权限”) |
加密复杂度略增,需额外存储索引信息 |
|
动态属性 CP-ABE |
2022 年 |
拆分 “静态属性(部门)” 和 “动态属性(时间)”,分别管理 |
支持实时权限调整(如 “工作时间内可访问,下班后失效”) |
动态属性更新需轻量级协议(如蓝牙 / 5G)支持 |
|
抗量子 CP-ABE |
2025 年 |
结合格密码 + 叛逆者追踪(能定位泄露私钥的用户) |
1. 抗量子攻击;2. 解决私钥泄露问题(金融 / 医疗关键) |
已在部分银行核心系统试点(如加密客户资产数据) |
(3)典型场景
电子病历管理:医生给癌症病历设规则 “肿瘤科医生或主任医师且患者授权”,只有同时满足这些属性的人才能查看 —— 既保证紧急会诊时能快速访问,又防止病历被无关人员查看。
3. 混合策略 ABE(HP-ABE)—— 结合两者优势的新方向
2024 年后兴起的混合方案,核心是 “数据端定部分规则,密钥端带部分属性”,解决跨部门协作场景:
- 比如跨科室医疗协作:数据端规则 “医疗数据 + 2025 年”,密钥端属性 “心内科医生 + 主治医师”,满足 “数据规则 + 密钥属性” 即可解密;
- 优势:避免单一策略的局限,适合多机构、多角色协同(如医疗联盟、企业供应链)。
四、分类对比汇总:一张表看清核心差异
为了不混淆,用表格直接对比 KP-ABE、CP-ABE、HP-ABE 的关键区别:
|
对比维度 |
KP-ABE(密钥策略) |
CP-ABE(密文策略) |
HP-ABE(混合策略) |
|
核心逻辑 |
数据贴标签,钥匙定规则 |
数据定规则,钥匙带标签 |
数据定部分规则,钥匙带部分属性 |
|
权限主导方 |
密钥持有者(如数据库管理员) |
数据拥有者(如医生、文档创建者) |
数据拥有者 + 密钥持有者(协同主导) |
|
规则表达能力 |
支持布尔 / 阈值逻辑,复杂规则需属性树 |
支持 LSSS 复杂逻辑,规则表达更灵活 |
支持跨域规则,适合多场景协同 |
|
安全性 |
属性标签可能泄露(数据端暴露标签) |
支持策略隐藏,安全性更高 |
结合两者安全机制,跨域场景下隐私保护更好 |
|
效率(加密 / 解密) |
加密快(贴标签简单),解密慢(规则匹配复杂) |
加密慢(规则设定复杂),解密快(属性匹配简单) |
加密 / 解密效率居中,需平衡两端复杂度 |
|
典型应用场景 |
公开数据分类访问(政府 / 公益数据) |
企业文档 / 医疗病历(数据拥有者控权限) |
跨部门 / 跨机构协作(医疗联盟、供应链) |
|
主流程度 |
次主流(场景较窄) |
主流(80%+ 落地场景用它) |
新兴(2024 后开始试点,未来潜力大) |
五、行业应用实践:
不是 “纸上谈兵”,ABE 已经在多个行业落地,看具体怎么用:
1. 医疗行业:电子病历共享
- 痛点:病历需严格控制访问(符合 HIPAA、我国《电子病历应用规范》),但急诊时跨科室调阅要快;
- ABE 方案:用 CP-ABE(LSSS 增强版),病历规则 “(科室 = 急诊科 OR 科室 = 肿瘤科)AND 患者授权”(LSSS 矩阵对应 3 个属性);

- 落地效果:某三甲医院 2024 年部署后,病历未授权访问从每月 5 起降至 0 起,急诊调阅时间从 20 分钟缩至 2 分钟(解密时 LSSS 份额组合仅需 10ms)。
2. 云存储行业:企业数据加密
- 痛点:企业把数据存阿里云、AWS,担心云厂商泄露或被黑客攻击;
- ABE 方案:用 CP-ABE + 策略隐藏,数据规则 “部门 = 市场 AND 项目 = 双 11”,加密时用 “属性索引” 替代明文规则(黑客看不到 “需市场部权限”);
- 落地效果:某电商 2025 年用该方案加密 “双 11 促销方案”(500GB),即使云存储出现漏洞,黑客拿不到匹配属性的私钥(需 “市场 + 双 11” 属性),也无法解密,密文存储开销仅比明文多 15%。
3. 物联网行业:智能家居权限
- 痛点:家里有门锁、摄像头、冰箱,需区分 “家人、保姆、访客” 的权限(如保姆不能看摄像头),且设备算力有限;
- ABE 方案:用轻量化 CP-ABE(属性哈希聚合),设备规则分别设:
- 门锁:“角色 = 家人 OR(角色 = 访客 AND 时间 = 18:00-22:00)”(2 个动态属性);
- 摄像头:“角色 = 管理员 OR 报警 = TRUE”
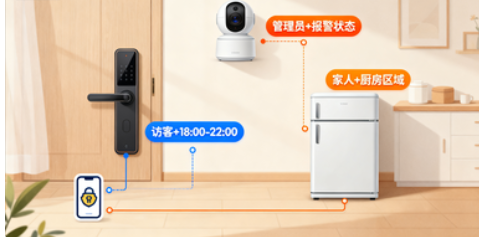
- 落地效果:保姆的手机私钥仅带 “访客” 属性(哈希后仅 16 字节),解密延迟 < 5ms,只能在指定时间开门,无法查看摄像头,设备续航提升 30%(轻量化算法降低功耗)。
4. 金融行业:客户数据保护
- 痛点:银行客户资产数据需 “风控人员 + 经理授权” 才能查看,且要防止私钥泄露(泄露后可能导致客户信息被盗);
- ABE 方案:用抗量子 CP-ABE(格密码基础)+ 叛逆者追踪,规则 “部门 = 风控 AND 级别≥经理”,私钥嵌入唯一身份标识(如员工 ID 哈希);
- 落地效果:某银行试点后,客户数据泄露事件为 0,私钥泄露定位时间从 24 小时缩至 10 分钟(通过格基特征反推身份标识),符合银保监会《数据安全管理办法》。
六、未来趋势:ABE 会往哪些方向发展?
结合技术瓶颈和行业需求,未来 3-5 年 ABE 的核心发展方向有 3 个:
1. 抗量子能力成为标配
- 背景:传统 ABE 基于双线性对,量子计算机(1000 量子比特)可在 10 分钟内破解(Shor 算法解离散对数);
- 趋势:格密码(Ring-LWE)将替代双线性对,成为 ABE 的底层技术 ——2025 年中科院的 TTRC-ABE 方案已实现 “抗量子 + 叛逆者追踪”,其格基生成效率提升 40%,预计 2027 年成为金融、医疗行业的强制标准。
2. 轻量化、低功耗适配物联网
- 背景:物联网设备(如传感器、智能门锁)算力有限(多为 ARM Cortex-M 系列芯片)、电池续航短(通常 1-2 年换一次电池),传统 ABE 的双线性对运算需 1000 + 次模乘,功耗过高;
- 趋势:
- 算法优化:进一步压缩属性数量(如用 AI 对属性聚类,将 “部门 + 级别 + 项目” 聚合成 1 个 “角色属性”),加密运算量减少 60%;
- 硬件加速:ABE 专用芯片(如华为海思 2025 年推出的 HiABE 芯片)将普及,采用 ASIC 架构(专用电路),加密功耗仅 20mW(比软件实现低 80%),适配智能门锁、穿戴设备等场景。
3. 多场景融合:与 AI、区块链结合
- 与 AI 结合:AI 自动学习用户行为,动态调整 ABE 规则 —— 比如通过分析员工访问记录,发现 “某员工常在 9 点访问研发文档”,自动将规则时间设为 “8:00-10:00”,无需人工配置;2025 年某互联网公司试点 “AI-ABE”,权限配置效率提升 70%。
- 与区块链结合:用区块链管理属性和规则,解决 “多机构属性互认” 问题 —— 比如医疗联盟中,不同医院的 “医生职称” 属性在链上存证,无需统一 TA(可信机构),跨院病历共享时直接验证链上属性;2025 年某医疗联盟试点 “区块链 + ABE”,跨院病历共享效率提升 50%,符合《全国医院数据安全管理指南》。
总结:ABE 的核心价值与未来
ABE 的本质是 “让数据访问从‘一把钥匙开一把锁’,升级为‘按属性智能授权’”—— 它的底层是双线性对 / 格密码的数学严谨性,中层是 LSSS 的规则灵活性,上层是行业场景的实用性,三者结合解决了传统加密在 “多用户、细粒度、动态权限” 场景下的死穴。
未来,随着抗量子、轻量化技术的成熟,ABE 会从 “专业领域” 走向 “大众应用”—— 比如个人云盘用 ABE 加密照片(规则 “家人 + 我的设备”),智能家居用 ABE 控制设备权限(规则 “我 + 在家时”),甚至手机支付用 ABE 保护交易数据(规则 “本人 + 常用设备 + WiFi 环境”)。那时,“属性即权限” 将成为数据安全的默认范式,让普通人也能享受 “智能、安全” 的数据访问体验。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









