



使用Xilinx Vivado HLS工具加速MapReduce函数的有效性研究
摘要
编程现场可编程门阵列需要高级硬件设计技能,这限制了其在数据中心的广泛应用。FPGA厂商提供了高层次综合(HLS)工具,用于从高级语言设计中生成寄存器传输级(RTL)规范。我们为普渡大学MapReduce基准测试套件提供了一组基于C和C++的硬件加速器,并使用赛灵思Vivado HLS工具将其性能和资源效率与手工编写的RTL代码进行比较。我们表明,基于高级语言的加速器中的简单设计更改可以改善结果。使用Vivado HLS,五个基准测试的性能达到了手工优化的RTL水平,而排序、自连接、邻接表和词频统计算法的性能则分别大约慢了4.7×、3×、2×和1.3×倍。
关键词
FPGA;硬件加速器;MapReduce;可重构计算;高层次综合;Vivado。
1 引言
随着越来越多的数据在云计算中被存储和处理,数据中心和云服务提供商持续增加其计算能力和存储容量。这导致对计算能力的需求不断增长,从而引发了高昂的能源和冷却成本,促使一些服务提供商探索更高效的能效数据处理解决方案。例如,微软和百度最近已将其FPGA引入数据中心,以加速各自的搜索引擎。这些可编程逻辑器件支持硬件级应用定制,从而实现高水平的性能和能效。然而,编程现场可编程门阵列需要高级硬件设计技能、对寄存器传输级(RTL)的熟练掌握以及领域专业知识。这使得FPGA比通用处理器更难编程,阻碍了其在数据中心的广泛应用。
赛灵思和阿尔特拉等FPGA厂商已通过提供新的设计工具来应对这一挑战,使开发人员能够使用高级编程语言对其器件进行编程。赛灵思的Xilinx Vivado HLS(2015)就是这样一种工具,它允许程序员使用C、C++或SystemC来指定计算任务。程序员使用指令帮助Vivado HLS利用高层次综合(HLS)技术将代码转换为高效的RTL。此外,Vivado HLS工具将高级语言中指定的设计综合成相应的硬件。最后,赛灵思的Vivado使用包括逻辑综合、布局布线在内的FPGA实现工具生成对应的硬件。
在云计算中处理大数据日益受到关注,而定制硬件(如单等人(2010)、陈等人(2015)、尹等人(2012)和何等人(2008)提出的方案)已被证明是提升MapReduce工作负载性能和能效的有效方法。本文研究了Xilinx Vivado HLS工具在生成常见云计算工作负载硬件加速器方面的有效性。为此,我们采用了Ahmad等人(2012)提出的普渡大学MapReduce基准测试套件中的应用程序来研究Vivado HLS生成的加速器的有效性。
我们的工作针对基于Abbani等人(2011)提出的可重构有源固态器件(RASSD)的分布式计算平台。随后,Kaituoa等人(2014)将该工作扩展,将FPGA集成到Apache Hadoop框架中,其中应用程序使用MapReduce范式进行编程。我们的框架研究了如何利用Vivado HLS工具生成高效的MapReduce硬件加速器。
我们的两项主要贡献是:
- 探索使用Xilinx Vivado HLS工具加速MapReduce函数的有效性。
- 提供有关从软件实现生成高效硬件加速器的最佳实践和策略的见解。我们使用普渡大学MapReduce基准测试套件将我们的性能和资源利用率结果与手工编写的RTL进行比较,并描述如何使用Vivado HLS指令为我们的基准测试实现最佳性能。
我们的论文分为六个部分。第2节介绍了相关工作背景,第3节介绍了高层次综合(HLS)、Xilinx Vivado HLS工具并描述了我们的方法论。第4节描述了普渡基准测试套件,并对全部九个硬件加速器进行了分析。第5节比较了Vivado HLS生成的加速器与手工编写的RTL加速器在性能和资源利用率方面的结果。最后,我们在第6节中得出结论并讨论了未来的工作。
2 相关工作
我们在文献中列出了四种评估高层次综合结果的方法。我们还指出了在高层设计中优化数组访问的相关工作,这是数据并行性中的主要瓶颈,旨在提升性能。数组访问优化是本研究中所用设计实现高性能的关键。
第一种评估高层次综合有效性的方法是将其性能与CPU的性能进行比较。Vahid等人(2008)提出的Warp处理是一种面向FPGA电路的二进制动态翻译工具。与CPU运行时间相比,它实现了2×到100×倍的加速。
第二种方法将高层次综合(HLS)结果与赛灵思(Xilinx)提供的参考RTL基准测试进行比较,赛灵思是所用FPGA开发板的制造商。例如,郭等人(2005)提出的ROCCC是一种C编译器,可为FPGA生成RTL,其生成的电路可运行在相同的时钟频率下,但占用的FPGA面积是赛灵思IP核发布的参考设计的两到三倍。
第三种方法则将HLS结果与其他HLS工具的结果进行比较。例如,Canis等人(2011)开发的LegUp是一款开源HLS工具,能够从C代码生成与商业HLS工具质量相当的硬件。通过LegUp对C代码进行综合,并将其结果与Y Explorations公司的商业工具eXCite生成的结果进行比较。该工作中使用的CHStone基准程序套件最初由原等人(2009)提出,旨在帮助HLS开发者评估其新技术,而非供设计人员用于评估HLS工具。
最后一种方法(也是本文所采用的方法)是将HLS结果与手工编写的RTL基准测试进行比较。如Navarro等人(2013)和Vissers等人(2011)所示,HLS工具在信号处理开发中已取得成功;Martin和Smith(2009)的研究也表明其在数据处理应用中的有效性。此外,Navarro等人(2013)通过展示HLS工具生成的RTL结果相较于手工编写的RTL具有竞争力,论证了HLS工具在控制算法中的适用性。他们提供了功率转换算法的C语言、MATLAB和VHDL实现,以展示HLS的竞争力。文献中还有多项研究采用了这种方法,例如平岩和天野(2013)、Monson等人(2013)、Homisirikamol和Gaj(2014)、Loughlin等人(2014)以及Glenn等人(2013)的工作。
值得注意的是Winterstein等人(2013)关于使用Vivado的聚类算法的研究。他们得出结论:低层次的以数据流为中心的C代码可以达到与RTL相当的性能,而包含递归的数据相关控制流的C语言风格则会导致30×更差的性能。最后,王等人(2013年)的研究致力于为FPGA中的高性能计算提供高速数据流。他们提出了一种基于线性变换的自动内存分区方案,最多可节省21%的块RAM、19%的切片和46%的数字信号处理器。在我们的工作中,如接下来第3.3节所述,我们对所有基准测试均采用Vivado HLS数组分区指令进行内存分区,以实现更高的吞吐量。
3 高层次综合
高层次综合工具通过提高抽象级别来简化硬件设计。设计人员无需担心寄存器边界,可以专注于指定所需功能。这加快了设计和验证时间,并允许在确定最优架构之前评估多种架构。因此,高层次综合工具生成RTL代码,而实现工具构建最终硬件。从而现代工具提高了生产力,但降低了与较低层次抽象相关的复杂性的可见性。
高层次综合工具还采用先进的编译器技术,以高效地将应用程序代码块转换为RTL代码。Vivado HLS工具会自动运行常量传播、死代码消除和范围分析等优化,以优化数据路径位宽。这在赛灵思(2015)的文档中有详细说明。
3.1 赛灵思的Vivado HLS
Vivado HLS 是一种高层次综合工具,可验证输入的 C/C++代码,创建并综合一个解决方案,并验证 RTL。此外,Vivado HLS 可将整个设计或其部分打包为 IP 核。一旦生成了硬件加速器的 RTL 代码,就会对其进行后处理,并打包成与赛灵思实现工具兼容的格式。后处理组件还会生成用 C 语言编写的加速器驱动程序,用于在硬件加速器加载到 FPGA 后调用它们。Vivado HLS 包含一个 Tcl 脚本语言解释器。
3.2 Vivado HLS 设计指令
Vivado HLS 允许通过 pragma 形式的指令来更改设计参数,这些指令可以直接添加到 C/C++代码中的对象或语句中,也可以作为命令添加到单独的 Tcl 文件中。将指令放在 Tcl 文件中的主要优点是,可以为同一实现创建多个解决方案。每个解决方案都有其对应的指令 Tcl 文件,用于同一个 C/C++设计。在探索了各种功能和接口指令后,该工具可以生成一个表格,比较不同解决方案的硬件资源以及时序要求。请注意,这可以针对原始参考 C/C++设计的多个实现进行。
3.3 我们的方法论
我们使用简单的Tcl脚本来指定设计指令。在此工作中,我们采用低级C/C++算法,以充分利用Vivado HLS的优化功能。目标是提升平台级别的计算吞吐量/能效。我们通过插入特殊指令来插桩代码,以指导Vivado HLS工具生成RTL。通过改变这些指令及其对应的设计参数,可以从同一份源代码生成多个具有不同性能和面积特性的RTL实现。一旦找到合适的一组设计参数,便使用标准设计工具将相应的RTL代码转换为FPGA配置比特流。
我们采用了与单等人(2010)提出的方法类似的方式,以支持使用同一MapReduce函数的多个版本。然而,由于Vivado HLS工具对设计输入格式的要求,我们的方法要求设计人员用C/C++语言编写其MapReduce函数。图1描述了我们基于HLS的设计方法论。我们设定目标设备和设计时钟频率,并运行用低级C/C++编写的代码设计,从而生成综合后的RTL。部分设计使用基本的查找表和触发器逻辑,而其他设计则使用DSP模块。当综合逻辑中自动使用DSP模块时,我们通过Vivado HLS工具中的图形界面选项将RTL导出为IP核,从而为该DSP对象生成一个XCI文件,该文件将与综合后的RTL一同导入到Vivado实现工具中。
由于本工作的主要目标是就最大性能对每个MapReduce任务进行单独比较,我们发现以下三个指令最为有用,并且在本文讨论的所有基准测试中始终使用这些指令:
-
set_directive_pipeline
:我们将此指令应用于主函数,例如:Grep 或 Sort。这将对整个设计进行流水线处理并优化:
1. 延迟:生成输出所需的总周期数;
2. 迭代间隔:在可以处理新的一组输入之前所需的周期数。
-
set_directive_unroll
:我们将此指令应用于所有没有循环间数据依赖的循环。即使存在循环间数据依赖,该指令也会被工具忽略。
-
set_directive_array_partition
:我们将此指令应用于所有一维和二维数组。这是一种内存分区指令,旨在有效提高内存带宽。没有此指令的数组将被视为具有FIFO结构的RAM,每周期最多允许两次读取。使用此指令后,工具将为每周期的数组项生成对不相交存储体的内存访问。根据王等人(2013年)的一项研究,这通常可以节省RAM,具体取决于设计,还可能节省DSPs。在本工作中考察的九个基准测试中,所有数组都进行了完全分区。这意味着为了实现更好的性能(这是我们本工作的主要目标),会消耗更多的资源。
我们各种C实现中的最佳RTL解决方案被导入Vivado v2015.2工具64位安装环境中,再次运行综合,然后进行实现。这为目标设备生成了时序和资源利用率数据。如前所述,Vivado HLS生成了原始C/C++设计最终实现所需的VHDL和IP核。
另一方面,RTL设计方法完全通过Vivado v2015.2工具构建。在此过程中,我们编写RTL代码,进行仿真,编写测试平台以验证输出的正确性,综合,最后实现以获得时序和资源利用率结果。

我们的HLS和RTL设计的目标设备均为Virtex 7型号 xc7v585tffg1157‐3(Virtex7系列,ffg1761封装,速度等级–3,91,050个Slice,364,200个查找表,728,400个触发器,1,260个数字信号处理器,1,590个块状存储器数量)。
在第2节中,我们描述了四类关于评估HLS结果的已发表工作,并确定将与手工编写的RTL进行比较。为了更好地理解Vivado HLS在匹配手工编写的RTL方面的潜力,我们将基准测试分为两组。第一组包含那些在文献中可以找到关于最佳性能和资源需求数据的基准测试。这些基准测试包括以下四个:K均值、分类、排序和Grep。K均值和排序的参考RTL设计使用赛灵思Virtex‐6开发板。参考分类设计使用赛灵思Virtex‐4,而Grep使用Virtex‐II Pro。虽然我们意识到Grep的参考RTL已有数年历史,且可能从近年来FPGA开发板所提供的硬件资源中进一步受益,分类设计也可能如此,但两者均未使用数字信号处理器,而Virtex‐7开发板上的数字信号处理器速度更快,同时它们使用的查找表数量较少,改进空间有限。此外,使用独立来源的RTL所带来的优势弥补了这一不足。
第二组包含我们为其构建了手写RTL的其他五个基准测试:词频统计、倒排索引、直方图电影、自连接和邻接表。
4 普渡大学基准测试 – 案例研究
在这些案例研究中,我们解释了如何为Ahmad等人(2012年)提出的普渡大学MapReduce基准测试设计和测试硬件加速器。请注意,对于那些结构随数据大小动态增长的基准测试,我们设定预定义的大小,并允许可扩展的解决方案以适应不断增长的数据集。根据Magdon‐Ismail等人(2013年)的研究,Hadoop也采用了类似的方法,以克服计算层与数据层之间紧密耦合的问题。这是Vivado HLS的一个限制,它要求所有结构在编译时必须具有已知大小,否则HLS工具无法自动生成时序。因此,我们不使用任何图、哈希表或任何其他形式的动态分配在我们的C/C++加速器实现中均不使用。当某个基准测试需要图时,我们采用具有固定维度的矩阵;对于列表,则根据需要使用固定大小数组和固定字符串长度。
最初的普渡大学基准测试共有13个,分别是:词频统计、倒排索引、词项向量、自连接、邻接表、K均值、分类、直方图电影、评分直方图、序列计数、排序倒排索引、Tera排序和Grep。普渡大学基准测试中描述的分类与K均值非常相似。为了更有力地论证FPGA在数据挖掘和机器学习中的优势,我们提出了一种贝叶斯分类器的硬件加速器,而非建议的实现方式。在分析每个基准测试后,我们去除了功能相似的基准测试,因为它们预计不会为我们的研究带来新的见解。词项向量用于确定文档中出现频率最高的单词并进行排序,这需要词频统计和排序功能,而这两者已在本工作中实现。类似地,评分直方图的功能已包含在直方图电影中。序列计数生成三个连续单词的唯一组合的出现次数,因此与词频统计非常相似。排序倒排索引基准测试根据给定单词在指定文档中的出现次数按降序排列,并去除重复单词,这本质上与基于出现次数作为键的排序非常相似。因此,我们将研究的加速器数量减少至以下九个,并在本节中对它们提供详细的设计与实现讨论。
4.1 来自文献的具有参考RTL的基准测试
4.1.1 K均值
K均值是一种在数据挖掘中广泛使用的数据聚类算法,根据黄等人(2010)、陈等人(2011)、Kambatla等人(2010)和王等人(2014)的研究,它也是MapReduce基准测试中的典型算法。我们采用Ali等人(2013年)提出的经过手工优化的结构化RTL所实现的RTL实现,该实现使用Virtex‐6 FPGA板。该实现包含一个映射任务,用于计算簇中所有点与给定质心之间的欧几里得距离,并对所有簇执行此操作。归约任务则根据计算出的距离选择新的质心。对于C设计,我们采用了Russell提供的实现(http://www.eee.bham.ac.uk/russellm/ee3j2/k-means.c),该实现此前也被沙拉费丁等人(2014)使用过。我们充分利用任务的并行结构,通过使用第3.3节中讨论的指令,将包括嵌套循环在内的所有循环按相应的循环界限展开。我们对乘法操作进行流水线处理,并对三个矩阵(distances、point-coordinates和centroid arrays)进行分区,使得每个周期为距离矩阵计算一个距离项。
4.1.2 分类
根据黄等人(2010)、何等人(2010)和王等人(2014)的研究,分类算法也是典型的MapReduce基准测试。如引言中所述,我们将普渡大学基准测试中的分类替换为朴素贝叶斯分类。该方法主要用于文本分类和自动医学诊断。在结果部分,我们使用孟等人(2011)提供的RTL作为参考RTL。
对于高层实现,我们使用来自GoogleCode(code.google.com/p/naive-bayes-classifier/)的C++代码实现朴素贝叶斯分类器。由于参考实现中存在递归和大量使用动态分配的结构,无法对原始的Google代码进行综合。因此,我们保留算法,但将动态类和向量替换为固定大小数组。该分类器根据输入概率数组计算输出概率。计算输出概率的算法主要包括以下步骤:
-
构建分类器:
a. 计算输入的概率:这是一个三重嵌套循环。外层循环遍历所有列,中层循环遍历所有输入,内层循环遍历所有输出。内层循环的主体是单次调用基于键计算概率函数。
b. 基于中间计算数据计算输出概率。 -
计算特定输出的概率。
这一步骤中有五层嵌套循环。第一层循环迭代所有输出。第二层循环迭代所有输入。根据输出编号和输入编号计算一个键。其余三个嵌套循环用于检索在(1)(a)中找到的键。将检索到的键与当前键进行比较,以计算概率。
4.1.3 Tera排序
根据迪恩和赫马瓦特(2004)以及坦蒂西里罗伊等人(2008)的研究,排序通常是常见MapReduce基准测试中的一项子任务。该过程既涉及大量的数据通信,也涉及大量的数据比较,因此每个周期都需要进行读写操作。对于参考RTL实现,我们采用了扎博洛特尼(2011)提出的堆排序算法,该算法使用赛灵思Virtex‐6 FPGA板。
由于使用了可变循环计数,Vivado HLS 无法满足堆排序的时序约束。因此,我们尝试了归并排序算法,这也是一种O(nlog(n)) 基于比较的排序算法。高层次综合生成了一个具有高时钟频率但排序单个条目需要大量周期的次优加速器。值得注意的是,函数内联指令(设置内联指令)会将更多逻辑引入关键路径,从而导致更差的时序结果。我们还尝试了冒泡排序,这是一种O(n²)算法。通过根据数组长度设定固定边界的两个嵌套循环对数组进行排序。我们使用以set_directive_pipeline II = 55表示的深度流水线,该值是排序一个64个条目的字符串数组所需的周期数。Vivado HLS调度生成的加速器运行频率为238兆赫。我们基于前24位进行排序,这与基于18位的参考排序相近。该方法的主要缺点是可扩展性不足。我们能够成功运行的最大数组大小为64,而参考RTL处理的数组可达2,047条记录。
我们最终尝试了一种改进型冒泡排序实现,该实现受到班吉(2014年)发表的赛灵思中值滤波器和排序网络算法研究的启发。我们的设计与他们的主要区别在于,班吉(2014年)在数组上使用FIFO接口,而我们使用默认的MEMORY接口。在我们的排序算法中使用FIFO会得到次优结果。当算法1中的三个数组buffer_in、buffer_out和buffer_temp均被划分为每块16个条目时,获得了最佳结果。算法1能够成功排序2,047条记录,与参考RTL实现的规模相同,但速度慢了4.7×倍。
算法1 改进型冒泡排序
for int i ← 0; i < 2047; i++ do
buffer_temp[i] = buffer_in[i];
end
for int i ← 0; i < 2047; i++ do
min = max_NUM;
for int j ← i + 1; j < 2047; j++ do
a = buffer_temp[i];
if min > a && a != MAX_NUM then
min = a;
index = j;
end
end
buffer_out[k++] = min;
buffer_temp[index] = MAX_NUM;
index = 0;
end
4.1.4 Grep
根据王等人(2014)和坦蒂西里罗伊等人(2008)的研究,Grep 是大数据计算中的一个常见基准测试。该基准测试的参考实现出自罗等人(2006)。该设计需要两个周期来匹配一个由两个字符组成的子串与一个由四个字符组成的字符串。请注意,此实现在设计时钟的上升沿和下降沿都需要对操作进行精确同步。这在 C 语言中显然是不可能实现的。
我们的Grep的C实现(如算法2所示)虽然与RTL设计非常相似,但无法对指令调度进行细粒度控制。我们对所有三个循环使用循环展开指令,并对table、pattern和substr数组进行分区,以使这些结构的各个条目均可被调度器访问。Vivado HLS 对算法2的结果在时钟频率上优于RTL,但由于10×资源需求的增加,不具备可扩展性。
算法2 Grep
exit_condition ← 1 << (m – 1)
for int i < table_length do
table[i] ← 0
end
for int i < pattern_size do
table[(unsigned short)pattern[i]] ← (0j1 << i)
end
for int i < pattern_size do
oldR ← state
newR ← ((oldR << 1)j1) ^ table[substr[i]]
state ← newR
if (newR ^ exit_condition) 不成立 then = 0
*found ← 1
end
end
4.2 使用内部手工编写的RTL进行基准测试
4.2.1 词频统计
根据陈等人(2011)和迪恩和赫马瓦特(2004)的研究,这是一个常见的MapReduce基准测试。我们首先实现了沙拉费丁等人(2014)提出的经过优化的RTL设计。该设计对输入的单词流进行分词,并将其插入到相应的数组索引中。然而,此设计所需的资源超过我们目标设备可用资源的两倍以上。因此,我们将RTL重写为沙拉费丁等人(2014)同样提出的C设计。该设计使用具有固定字符数的单词固定大小数组。这将增加存储需求,但可以省去分词步骤。此外,这极大地简化了所有字符串操作。我们冗余地持续查找输入单词在数组中的位置。通过这种方式,我们在最差情况下的C性能方面,将加速结果与手工优化的RTL进行了比较。
4.2.2 倒排索引
倒排索引以文档列表作为输入,并生成词到文档索引。根据黄等人(2010)的研究,倒排索引被视为代表性的大数据基准测试。该加速器使用直接映射访问(DMA)接口,处理流入加速器的单词流,并将唯一单词填入相应的子数组中。每个子数组保存以相同字符开头的单词。当单词为唯一单词时,将其连同文档名称一起插入子数组中。后续出现的相同单词仅需相应地追加文档名称。
算法3 倒排索引。DMA解复用风格
if !end_char then
char ch_e0 ← matrix[0][up_counter]
char ch_e1 ← matrix[1][up_counter]
char ch_e2 ← matrix[2][up_counter]
char ch_e3 ← matrix[3][up_counter]
if in_char == ch_e0 then
match_not_found[0][up_counter] ← false
end
if in_char == ch_e1 then
match_not_found[1][up_counter] ← false
end
if in_char == ch_e2 then
match_not_found[2][up_counter] ← false
end
if in_char == ch_e3 then
match_not_found[3][up_counter] ← false
end
else if any match found in matrix[0] then
new_wd_fnd[0] ← false
else if any match found in matrix[1] then
...
end
C实现是在RTL设计之后设计的,如算法3所示。在一次DMA访问中,我们获取子数组的所有元素。这总共是四个条目的八个字符串,相当于每次传输256位。子数组元素在算法3中用matr[0..4]表示。根据输入字母,我们访问子数组并执行比较。只要未遇到单词结束字符end_chr,该算法就会持续匹配特定单词。在结果部分,我们将讨论如何通过显式包含词索引计算(如算法4所示),使基于C的加速器达到手工优化的RTL的性能水平。这种相同的设计风格也已在RTL中的倒排索引中实现。
算法4 倒排索引 explicit. 用于演示显式计算的代码片段
if up_counter == 0 then
if in_char == ch_e0 then
match_not_found_result[0][0] ← false
end
if in_char == ch_e1 then
match_not_found[1][0] ← false
end
if in_char == ch_e2 then
match_not_found_result[2][0] ← false
end
if in_char == ch_e3 then
match_not_found[3][0] ← false
end
else if up_counter == 1 then
同样的操作也适用于match_not_found[0到3][1]
end
4.2.3 直方图电影
直方图电影是对连续变量概率分布的估计,也被Jestes等人(2011)和单等人(2010)用作代表性的MapReduce工作负载。我们采用了沙拉费丁等人(2014)先前引入的相同RTL和C实现。请注意,对于此基准测试,我们通过使用12位定点表示来避免处理浮点运算。映射函数将每部电影的评分相加以计算平均值和余数。归约函数将评分排序到各个桶中。
4.2 使用内部手工编写的RTL进行基准测试(续)
4.2.4 自连接
自连接是一种相似性问题,其中一组项目表现出高度相似性。推荐算法利用自连接结果来推荐相关数据。文献中已有若干研究探讨了分布式系统中的自连接。Baraglia等人(2010)的一项研究通过采用一种克服内存瓶颈的分区策略,将自连接的性能提高了4.5×。Vernica等人(2010)的另一项研究则考察了数据分区以在Hadoop中平衡自连接的负载,并使用真实数据集报告了性能特征。
在此实现中,我们专注于为核心加速器创建一个基本内核,以利用可重构硬件并加速计算。因此,该方法与上述引用的工作正交。在图2中,我们将矩阵元素视为事务矩阵。每笔事务表示在该特定事务中选择了哪些项目。每笔事务收集最多八个项目购买的数据。因此,这个二维事务矩阵具有以下数量的条目:
number of transactions × maximum number of items per set
该图显示了MapReduce RTL块图。我们的加速器会报告哪三个项目被一起购买,只要其频率超过预设阈值。
Total number of sets = 8! / (3! × 5!) = 56
因此,将检查56种可能的三元素自连接集合。还要注意,对于每个大小为5 × 3的输入矩阵,我们的加速器都需要查找所有56种可能的组合。这是为了跟踪出现次数。
该用户特定项目组合的结果被保存在一个大小为5 × 56的布尔出现矩阵中。

算法5 自连接2 优化的自连接
MAP
for i = 0; i < transactions; i++ do
if purchased item 1 & 2 & 3 \| 2 & 4 \| 2 & 5 \| 2 & 6 \| 2 & 7 \| 2 & 8 then
occurrence[i][0] ← 1
else
occurrence[i][0] ← 0
end
end
// 检查其他组合 [i][1] 到 [i][55]
REDUCE
sum ← Σ all occurrences of first pattern across transactions
if sum > threshold then
discover self-join
end
// 以相同方式查找56种出现模式
对于C实现,我们从典型用户基于普渡基准的映射值字母数字排序列表计算自连接数据所编写的代码开始。这是一个三重嵌套循环,其中外层循环遍历所有值,中层循环遍历所有项目,最后最内层循环遍历其余项目以查找自连接。最内层操作是一个带有携带依赖的加法操作,Vivado HLS无法简化该操作。occurrence矩阵是一个三维矩阵,初始遵循普渡基准的定义。它仅对五次事务具有有效条目,其余为无效。这导致在4 ns时钟周期下产生557个周期的不可接受延迟。
我们用算法5中所示的低层次设计替代了高级实现,该设计试图复制RTL设计。occurrence矩阵在结构上也与RTL对应部分相同,并被定义为静态数组,以避免违反目标设备的IO填充限制。尽管新设计在处理周期数方面与RTL对应部分相当,但需要三个周期的间隔。这意味着加速器每隔三个周期而不是每个周期才能处理一个新的输入。要解决间隔问题,必须对加速器进行重大重新设计,以流式方式处理出现次数,而不是将出现次数保留在数组结构中。
4.2.5 邻接表
我们在PageRank的上下文中实现邻接。根据黄等人(2010)和单等人(2010),这是另一个典型的MapReduce基准测试。由于Vivado HLS不自动支持动态分配,我们构建了一个由顶点数量参数化的二维方阵邻接矩阵。矩阵中每个元素的值表示相应边的权重。手工优化的RTL框图基于累加器,如图3所示。该矩阵为4 × 64,包含四行和64列。更大的、行数更多的矩阵需要级联此逻辑。每个周期将一列传递给累加器。所使用的浮点加法器是全流水线IP核,需要15个周期生成结果。最后,RESULT_READY表示累加器输出已计算出邻接表。
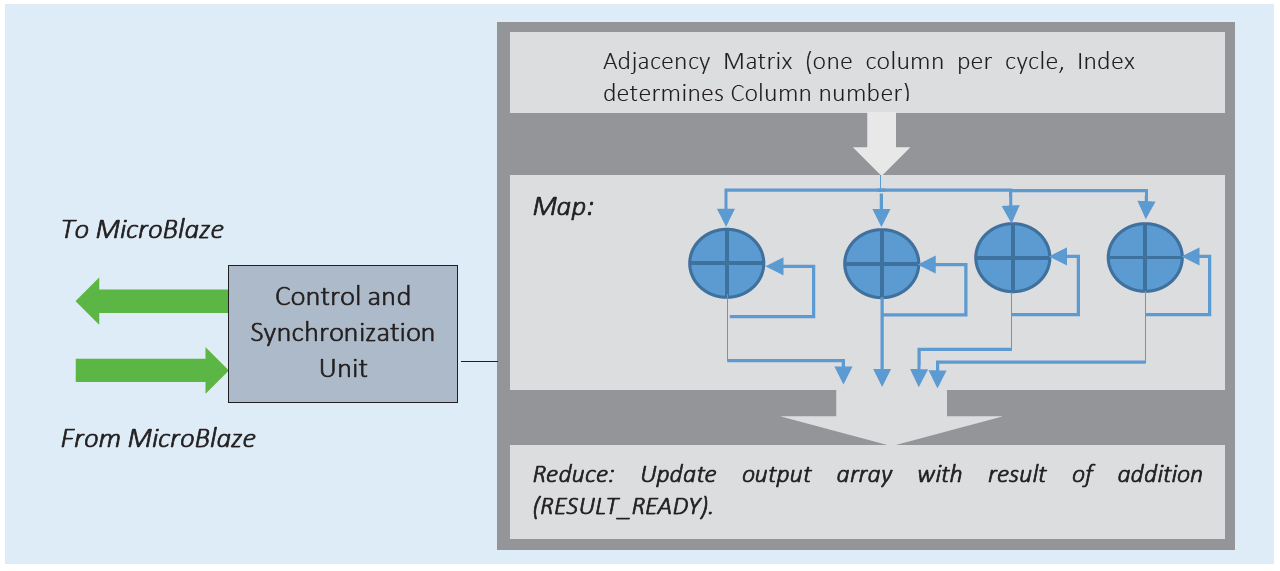
算法6 ADJ2 邻接优化 (顶点 × 边)
static float acc[vertices];
for i ← 0; i < vertices; i++ do
acc[i] ← acc[i] + adj_matrix[i];
adj_out[i] = acc[i];
end
朴素C实现的邻接涉及用于邻接加法器的嵌套循环。请注意,由于在此基准测试的嵌套版本中加法是一个循环依赖操作,Vivado HLS指令无济于事,导致加速器性能较差。算法6中所示的优化邻接打破了循环依赖并采用了RTL风格,但仍未能达到RTL的性能水平。这主要是由于使用了累积的静态变量。该变量需要进行加载、存储和加法操作。使用如算法7所示的底层级联加法代码,虽然可以匹配RTL设计的周期数,但时钟周期仅为一半,使得该设计的时钟周期为原来的一半。
算法7 ADJ3 使用2输入加法器进行邻接优化 (顶点 × 边)
float temp[vertices];
temp2[vertices], ... temp_edge_div_2[vertices];
temp[0] = adj_matrix[0][0] + adj_matrix[0][1];
temp2[0] = adj_matrix[0][2] + adj_matrix[0][3];
...
temp_edge_div_2[vertices – 1] = adj_matrix[vertices – 1][edge – 2] + adj_matrix[vertices – 1][edge – 1];
adj_out[0] = temp[0] + temp[1];
...
adj_out[edge – 1] = temp_edge_div_2[vertices – 2] + temp_edge_div_2[vertices – 1];
通过此修改,RTL和HLS设计在性能上达到一致。
5 性能评估
我们总结了结果,并以资源利用率、时钟频率以及预定义数据大小的任务延迟来报告性能。
5.1 来自文献中参考RTL的基准测试结果
请注意,对于这组基准测试,我们在高级语言设计中没有可遵循的RTL代码。因此,两种方法实现的时钟频率最终有所不同。该方法的主要见解是,尽管Vivado HLS的性能结果可能非常具有竞争力(如Grep和贝叶斯分类器的情况所示),但这以更高的面积占用为代价,这是硬件设计中的常见权衡。表1显示了此类基准测试的资源利用率,图4显示了实现的时钟频率。尽管某些参考RTL在较新的FPGA开发板上可能表现更好,但我们认为使用它们会使Vivado HLS结果更具说服力,因为RTL和HLS两条路径是独立开发的。表2比较了参考设计和HLS设计中处理参考任务所需的时间。
- K均值 :由于该算法具有高度并行性,C实现的性能与RTL相当,同时使用的资源也相近。参考任务包含一千万个双向点,分为两个簇,总大小为320 MB。
- 贝叶斯分类 :与表1中用‘/’分隔的两种实现相比,C实现达到了更高的时钟频率,但代价是更高的资源利用率。这两种RTL实现分别对应于Appiah等人(2009)和孟等人(2011)参考文献中报道的两种实现。请注意,第二种RTL实现执行的是专门化且简化的朴素贝叶斯分类。尽管本文比较的HLS设计与RTL设计在规模和最终目标上有显著差异,但它们在计算复杂度上本质上是相似的。Vivado HLS实现了更高的时钟频率,达到287 MHz,而Appiah等人(2009)的为40 MHz。HLS设计比参考RTL加速器多使用了10×个查找表、13×个触发器和14×个数字信号处理器。最后,我们的HLS设计使用了可用触发器的1%、可用查找表的2%以及可用数字信号处理器的3%,仍远低于我们的目标器件资源预算。因此我们认为贝叶斯分类器的HLS结果具有竞争力。参考任务是对25,000个大小为784位的模式进行分类。注意,HLS实现的延迟要高得多,这一性能提升我们并未声称,因为我们未构建视频接口架构,导致参考RTL的时钟周期为25纳秒。
- Tera排序 :对记录的排序速度比相应的参考RTL慢4.7×倍。尽管Vivado HLS实现的资源利用率和频率表现高效,但排序所需的周期数更多。参考任务对每条24位的5000万条记录进行排序。
- Grep :在性能上具有较强的竞争力,但与参考RTL相比,其所需的资源超过一个数量级。尽管资源需求较高,但总体资源利用率开销微不足道(不到1%)。参考任务是对8位输入在1 MB数据流中执行Grep操作。
表1 文献中的参考RTL与HLS生成的加速器所使用的资源
| 基准测试 | LUTs | FFs | DSP48/内存 | |||
|---|---|---|---|---|---|---|
| RTL | HLS | RTL | HLS | RTL | HLS | |
| K均值 | 2,760 | 5,109 | 4,130 | 6,730 | 100 | 24 |
| 贝叶斯分类器 | 18,387/8,663 | 4,095/10,373 | 34/3 | 813 | 730 | 随机存取存储器 随机存取存储器 43 |
| Tera排序 | 1,860 | 283 | -323 | 38 | RAM RAM | 4 |
| Grep | 16 | 184 | 9 | 266 | – |
表2 文献中参考RTL任务与我们HLS生成的加速器的延迟
| 基准测试 | 数据大小 | 执行时间 RTL | 执行时间 HLS |
|---|---|---|---|
| K均值 | 320 MB | 17秒 | 17秒 |
| 贝叶斯分类器 | 2.3 MB | 1 sec | 0.14 sec |
| Tera排序 | 143 MB | 1 秒 | 4.7 秒 |
| Grep | 1 MB | 42 纳秒 | 43 纳秒 |
5.2 使用内部手工编写的RTL进行基准测试的结果
表3显示了此类基准测试的资源利用率,图5显示了实现的时钟频率,而表4显示了使用1兆字节数据集的相应任务的延迟。
表3 手工编写RTL和HLS生成加速器所使用的资源
| 基准测试 | LUTs | FFs | DSP48s | |||
|---|---|---|---|---|---|---|
| RTL | HLS | RTL | HLS | RTL | HLS | |
| 词频统计 | 3,735 | 2,477 | 4,254 | 4,924 | – | |
| 倒排索引 | 2,760 | 1,380 | 4,130 | 2,369 | 100 | 80 |
| 自连接 | 456 | 2,157 | 283 | 2,175 | – | |
| 邻接表 | 2,016 | 2,016 | 2,419 | 2,633 | 27 | 18 |
| Hist. 电影 | 143 | 281 | 390 | 281 | – |
表4 我们的RTL加速器和HLS生成的加速器的延迟
| 基准测试 | 执行时间 RTL | 执行时间 HLS |
|---|---|---|
| 词频统计 | 13.2 秒 | 16.5 秒 |
| 倒排索引 | 209 μsec | 178 μsec |
| 自连接 | 280 纳秒 | 881 纳秒 |
| 邻接表 | 213 μsec | 427 μsec |
| 直方图电影 | 1708 μsec | 766 μsec |
5.2.1 词频统计
词频统计需要大量数据访问与严格的控制逻辑同步。这导致其性能比RTL结果下降了25%,同时消耗了相当的资源。所示延迟为统计相当于100万个字符串(略超过1兆字节)所需的时间。
5.2.2 倒排索引
Vivado HLS 在此基准测试中表现出较强的竞争力,只需对我们的 C 代码进行两项简单调整:首先是将处理方式改为 DMA 风格,其次为消除索引计算。值得注意的是,在C实现中,子数组的解复用风格字符访问索引up_counter会导致Vivado HLS生成的加速器性能4×下降。我们将此称为算法3中的DMA解复用风格。当计算字索引时,处理一个新字符需要四个周期,而移除该步骤后仅需1个周期。如算法4所示,通过显式执行此操作,基于C的加速器性能略优于手工优化的RTL。同样的索引计算优化也在RTL中得以实现。请注意,Vivado HLS会自动通过多路复用器结构优化表达式比较,从而获得更短的时钟周期,进而改善整体延迟。
5.2.3 直方图电影
直方图电影使用简单的组合逻辑表达式和12位定点表示法,在将评分分类到区间时简化除法运算。请注意,该结果与词频统计结果略有不同,主要是因为在将数据分类到区间时仅涉及控制逻辑,而不包含数据访问的复杂性。
5.2.4 自连接
该设计运行频率为238兆赫,在映射步骤中需要五个周期来检查每个输入事务中的项目(总共五次事务),在归约步骤中需要56个周期来确定自连接出现矩阵内容是否超过阈值(总共56种可能的出现需要检查)。Vivado HLS在自连接基准测试中的性能比相应的RTL差三倍,原因是将数据保留在加速器本地的数组结构中。如前所述,采用类似于我们在倒排索引中所遵循的流式自连接实现方法可以解决此问题,并使结果与RTL相匹配。在资源利用率方面,如第3.3节所述对数组结构进行分区,会导致HLS结果使用更多的触发器和查找表,但总体利用率仍仅为目标设备的不到1%。
5.2.5 邻接表
是一个简单的设计,表明在使用浮点数据类型时,对于直接的高级语言实现,Vivado HLS 在性能上无法与 RTL 匹配。我们必须用显式的加法级联替换代码,并使用原始的二维矩阵,才能达到一半的 RTL 性能。如果不进行此更改,由于涉及多个静态加载/存储/加法操作,无法实现流水线,设计性能会差 10× 。从表3可以看出,高级语言实现所需的资源与 RTL 相当。延迟显示了计算大小为1MB的矩阵的邻接所需的时间。
该基准测试的主要结论是,尽管Vivado HLS能够自动综合浮点运算,但只有在使用定点表示时,其性能才能达到RTL手工优化设计的水平。
6 结论与未来工作
在本研究中,我们针对九个普渡大学MapReduce基准测试评估了Vivado HLS。我们提供了参考HLS Vivado工具所支持的各种C语言风格,并报告了硬件开发者对每种风格所能预期的效果。我们得出结论:Vivado HLS能够很好地处理控制流或数据流设计,但在设计中同时使用这两种风格的组合时表现不佳。事实上,当设计中结合使用这两种风格时,浮点逻辑可能会加剧Vivado HLS结果的性能下降。此外,Vivado HLS在实现与RTL相当的性能时往往消耗更多资源。在九个普渡基准测试中,有五个的Vivado HLS性能结果与手工优化的RTL相匹配,而排序、自连接、邻接表和词频统计算法则分别落后约4.7×, 3×, 2×和1.3× 。通过将浮点运算替换为定点表示,邻接表基准测试的结果可以达到与RTL相当的水平。自连接的性能可通过数据流式传输而非维护加速器数组结构来改善。
这项工作的第二步是提供一个Hadoop环境,该环境可以高效地在各个RASSD节点之间分配任务,并允许硬件开发者针对他们的大数据应用逐步更新服务器的基于C的加速器。

















 7365
7365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









