




 本文介绍了Spatial Pyramid Pooling (SPP) 的创新,如何解决传统网络对输入尺寸限制的问题,以及它在多尺度训练、全图像表示、多视图测试和目标检测中的应用。SPP通过固定输出维度提升模型对形变的鲁棒性,并通过实例和实验展示了其在视觉任务中的优越性能。
本文介绍了Spatial Pyramid Pooling (SPP) 的创新,如何解决传统网络对输入尺寸限制的问题,以及它在多尺度训练、全图像表示、多视图测试和目标检测中的应用。SPP通过固定输出维度提升模型对形变的鲁棒性,并通过实例和实验展示了其在视觉任务中的优越性能。
paper: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
code: https://github.com/yueruchen/sppnet-pytorch
本文的创新点:
- Spatial Pyramid Pooling(SPP)
- Multi-Size Training
- Full Image Representation
- Multi-View Testing
- SPP in Object Detection
空间金字塔池化
常见的分类网络都是卷积层+全连接层的结构,而全连接层需要固定输入的维度,因此一般网络的输入也都是固定的,比如常见的224x224。通常对原始图片采用cropping或warping(resize)的方式来获得固定的大小,crop会导致输入没有完全包含目标对象,resize会导致几何失真,如下图所示

因此作者提出了spatial pyramid pooling,在最后一层卷积和全连接层之间加入SPP,既保证了全连接的输入维度是固定的,又不需要固定模型的输入大小。具体做法是:和传统的池化固定窗口大小然后滑动窗口的实现方式不同,SPP是将feature map均分成多个格子(spatial bin),然后在每个格子里进行池化(文中使用的是max pooling),这里格子的数量是固定的,当输入大小变化时每个格子的大小也按比例变化,但格子数量不变,从而保证了全连接层的输入维度是固定的。如下图所示,当最后一层卷积的输出通道数为256,采用4x4、2x2、1x1的SPP时,SPP的输出向量维度(4x4+2x2+1x1)x256=5376是固定的。
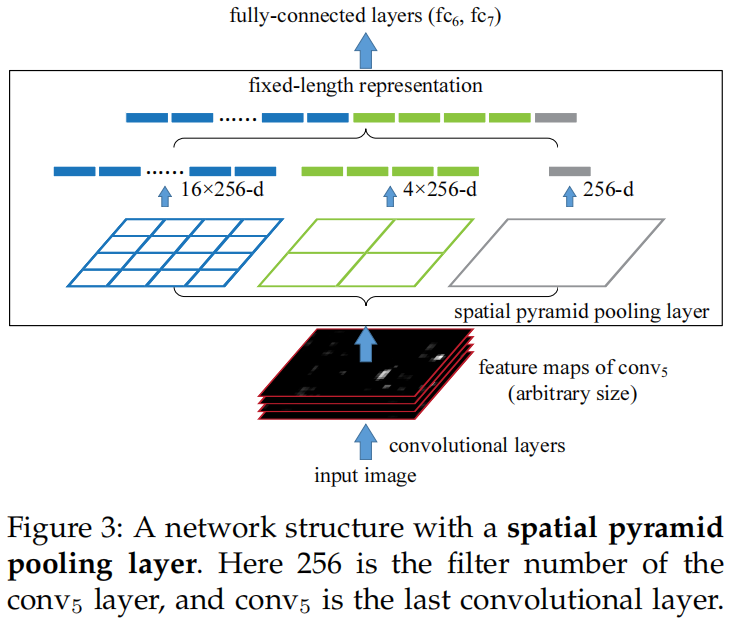
SPP有以下三个优点:
- 不管输入大小,SPP都能生产一个固定长度的输出
- 滑动窗口池化只使用一个大小的窗口,SPP使用多层级不同大小的窗口,后者对目标形变鲁棒性更强
- 由于对输入大小没有限制,SPP可以在可变的不同尺度上提取特征
代码
import math
import torch
import torch.nn as nn
def spatial_pyramid_pool(previous_conv, num_sample, previous_conv_size, out_pool_size):
"""
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
"""
for i in range(len(out_pool_size)):
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid * out_pool_size[i] - previous_conv_size[0] + 1) / 2
w_pad = (w_wid * out_pool_size[i] - previous_conv_size[1] + 1) / 2
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if i == 0:
spp = x.view(num_sample, -1)
else:
spp = torch.cat((spp, x.view(num_sample, -1)), 1)
return sppMulti-Size Training
因为SPP对输入大小没有限制,可以通过多尺度训练来模拟不同的输入大小,文中采用224x224和180x180两种输入大小,每种大小的输入训练完一个完整的epoch再切换另一种大小的输入,交替进行。实验表明,多尺度训练和单尺度训练的收敛速度差不多,精度要比前者高。
Full Image Representation
对于输入保持长宽比的前提下resize使得min(w, h) = 256,一种是从中间crop出224x224区域作为模型输入,另一种是整张图作为输入,文中作者经过实验发现后者的效果更好,表明了保留图片的完整内容的重要性。
Multi-View Testing
在测试阶段,保持长宽比的前提下resize输入使得min(w, h) = 256,然后送入模型inference,得到SPP前的最后一层卷积层的输出feature map,然后在原始输入中crop不同的区域并映射到该特征图上,得到该特征图上多个不同的crop区域,然后分别经过SPP和全连接层得到模型输出,最后对多个结果进行平均得到最终的预测。文中从resize后图片的中间、四个角、四条边的中间分别crop出224x224的区域,对flip后的图片按同样的方法crop出9个区域,因此最终得到18个结果取平均后作为预测输出。
SPP in Object Detection
在RCNN中,通过selective search得到2k个proposal,然后将这2k个proposal对应的原图区域分别送入卷积网络提取特征。本文的改进在于原始图片直接送入卷积网络只进行一次forward处理得到特征图输出,然后将原图proposal对应的区域映射到该输出特征图上,然后SPP分别对特征图上proposal对应的区域进行处理,这里和上面的multi-view testing比较类似。


















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











