









 本文深入探讨SQL语句在数据库中的执行流程,包括查询、更新语句的处理过程,以及MySQL的体系结构与模块划分。讲解了客户端与服务端的通信类型、连接方式,SQL语句的解析、预处理、优化,以及存储引擎的对比。
本文深入探讨SQL语句在数据库中的执行流程,包括查询、更新语句的处理过程,以及MySQL的体系结构与模块划分。讲解了客户端与服务端的通信类型、连接方式,SQL语句的解析、预处理、优化,以及存储引擎的对比。
1. 一条查询语句是怎么执行的?
select version(); 查看sql的版本客户端与sql服务端的通信类型:同步,异步
同步:请求发出之后一直等待,在获取结果之前不能做其他操作。使用连接池。
异步:发出请求,会立马返回响应结果,数据会在执行完成后返回。异步会带来数据的混乱,并维护大量连接,所以一般会选择同步。
客户端与sql服务端的连接方式:长连接,短连接
长连接:可以在服务端持续的保持连接,减少创建和释放连接导致的消耗。使用连接池保存长连接。但是大量的长连接也会消耗性能,所以对不活跃的长连接要及时销毁,即设置超时时间。
非交互式的连接(jdbc)超时时间 ,单位是s
show GLOBAL VARIABLES like 'wait_timeout';
交互式链接超时时间
SHOW GLOBAL VARIABLES LIKE 'interactive_timeout'; 当前有多少个关于线程的链接
SHOW STATUS LIKE 'Thread%';
Threads_cached 1 # 打开的线程数
Threads_connected 3 # 链接的线程数
Threads_created 4 #创建的线程数
Threads_running 2 #正在执行的线程数
连接和线程的关系:实际上在数据库的服务上,是通过一个一个的线程处理客户端一个一个的连接(会话)。即可通过查看线程数,查看服务端有多少个链接。如果想要关闭一个会话,只要干掉线程即可。
在myslq中查看最大允许的连接数 默认151, 最大100000 ,最小1
SHOW VARIABLES LIKE 'max_connections'; 系统变量:系统状态:
global:全局级别
session:会话级别
修改的时候需要注意:set key(参数名) value (值) ;如果没有任何参数,默认是session级别的,打开一个窗口则设置的内容无效。
如果想要一个设置永久生效,可以在/etc/my.cnf文件中设置。
短连接:一次会话结束,就销毁了连接。
通信协议:
TCP/IP
Unix Socket
当通过mysql -uroot -p123456 这种没有-h参数的时候,使用的文件(mysql.sock)通信。
当通过mysql -h192.168.0.0.1 连接的时候,通过TCP/IP协议连接。
通信方式:mysql中使用的半双工方式
单工 数据单向传回 ,如电视遥控器
半双工 数据双向,但不能同时传输,如对讲机
全双工 数据双向传输,可以同时传输,如打电话
SHOW VARIABLES like 'max_allo%' ; 服务端能接收的数据包的大小 4M
mysql的缓存:要求较为严格
如 select * from user ;当语句当中多了个一个空格,或user写为Use 都无法命中缓存。mysql8.0版本已经去除了缓存的功能。
解析器:主要对客户端发来的语句进行词法和语法,语义的解析,如果sql写的不合法直接返回。
select name from user_info where id = 1; 服务器会把该sql打成8个单词,并检查每个单词的语法是否合法。
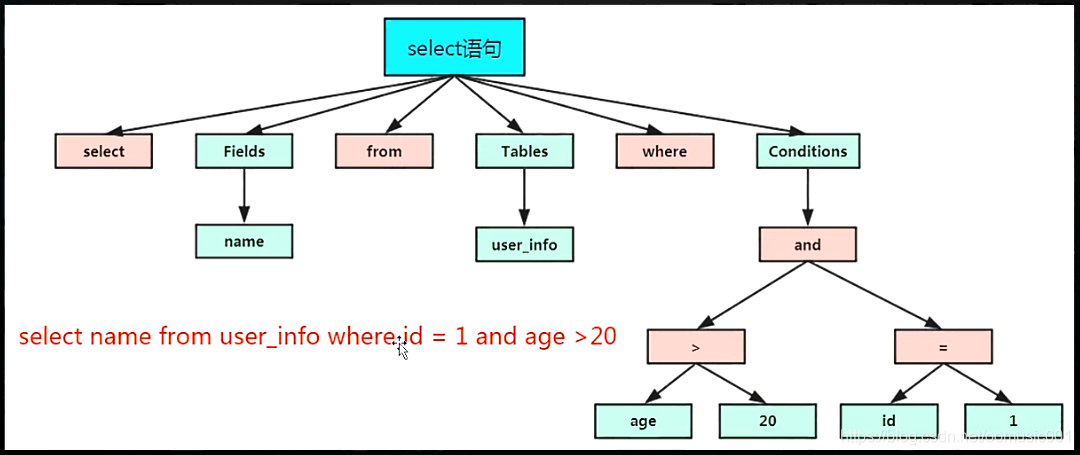
预处理器:语义分析和权限的检查(用户是否有删除,查询的权限等)
优化器:对sql语句进行优化(每一个sql可能有几种执行路径),优化器是一个实时计算的模型,不一定每一次都能最优。
如:a = 6 and b > a 优化为:a = 6 and b >6;
如:where 1 = 1 ,会被优化器直接移除。where 1 = 4,会被优化器直接移除。
SHOW STATUS LIKE 'last_query_cost'; 查看sql 的执行成本:执行计划:优化器会将解析的结果转为执行计划
EXPLAIN SELECT * FROM act_de_databasechangelog; 查看执行计划
SHOW TABLE STATUS FROM activiti ; 查看数据库所有表的信息,如存储引擎,版本,表名称等。
show VARIABLES like 'datadir' 查看数据存放的地址
数据展示:
ALTER TABLE tb_content ENGINE = Memory; 修改表的存储引擎
ALTER TABLE tb_item ENGINE = Archive;
1.上面修改存储引擎的方式会导致表的一些特性消失,不建议使用。
2.可以将表的数据导出,表sql脚本上修改存储引擎,执行脚本。
3.也可以新建表,重新导入数据,和上面方法基本一样。
存储引擎对比:
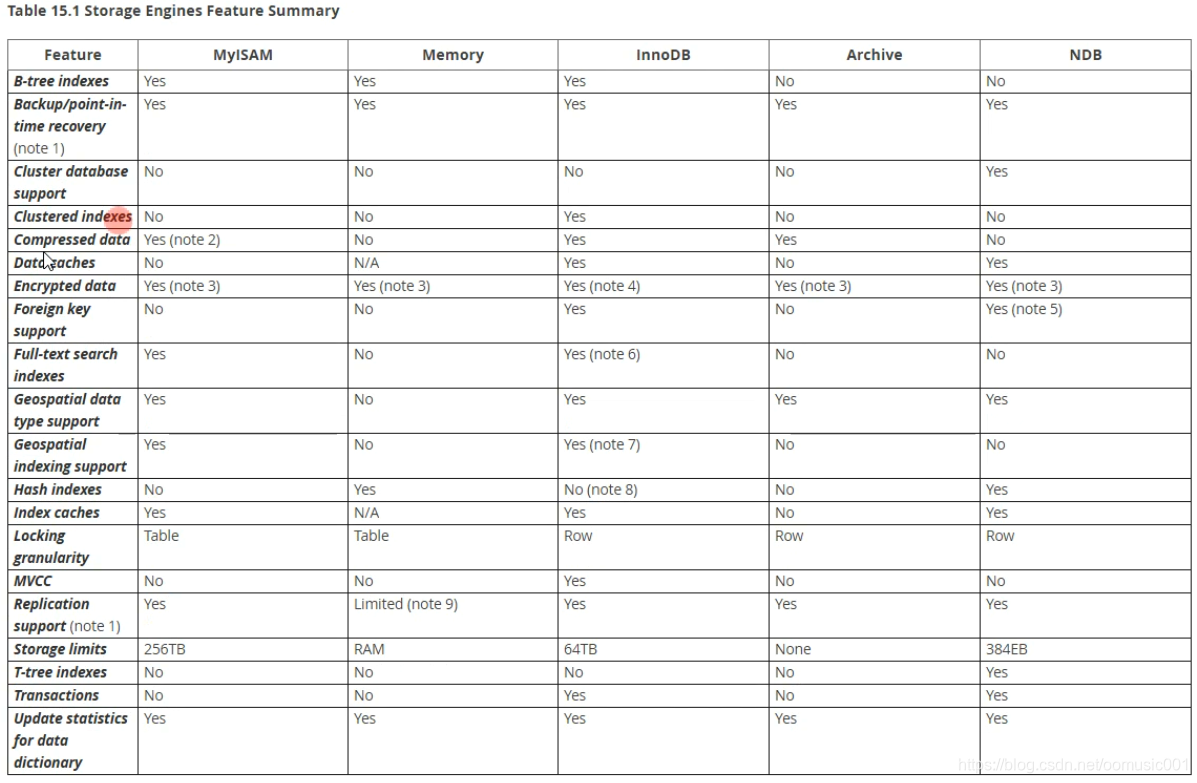
InnoDB:默认的存储引擎,支持事务,具有提交回滚,崩溃恢复功能,提供了行级别的锁。
通过非锁定读提高查询效率,也支持表级别的锁。索引就是数据,数据就是索引。该存储引擎适用于经常更新的表。
MyIsam: 5.5之前默认的存储引擎。只支持表级别锁定功能,不支持事务,通常用于以读为主的表。
查询效率比较高。
Memory:把数据放到内存中的存储引擎,读取效率高,只适用于临时数据的存储。
CSV:纯文本格式的存储引擎。通常用于数据的传输,导出,导入操作。数据格式为:1,agg,fff
Archive: 归档存储引擎,不支持update,delete。如存放历史订单等。不允许修改删除。
NDB:用来做集群的存储引擎。
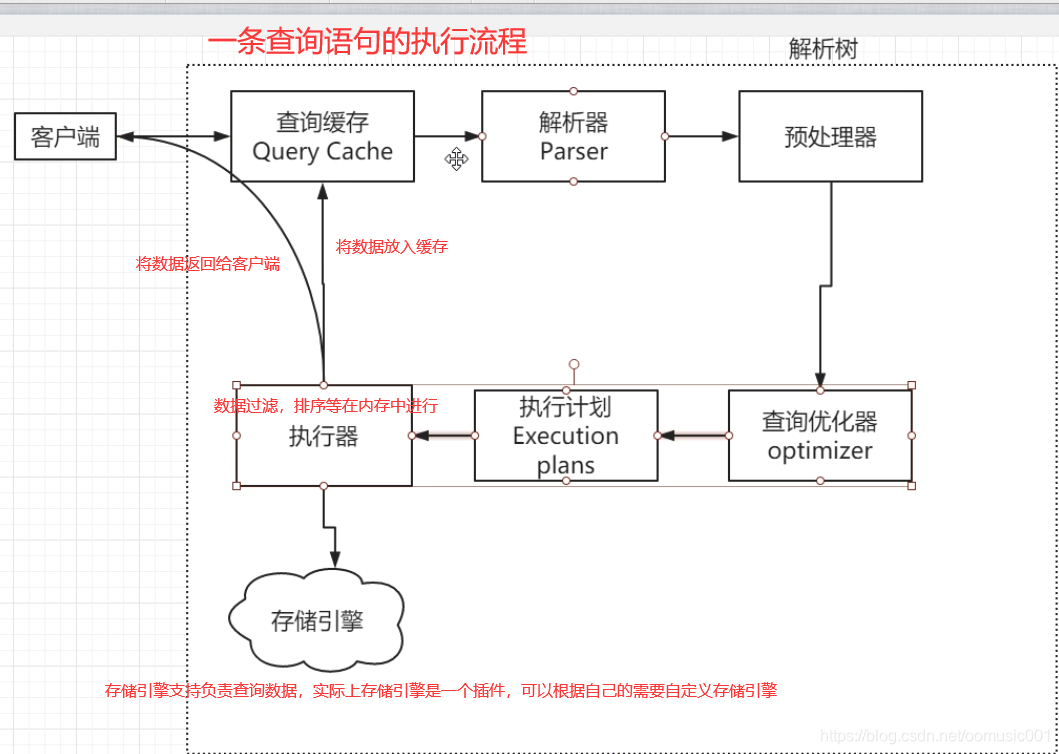
MySQL体系结构与模块划分
模块分析:
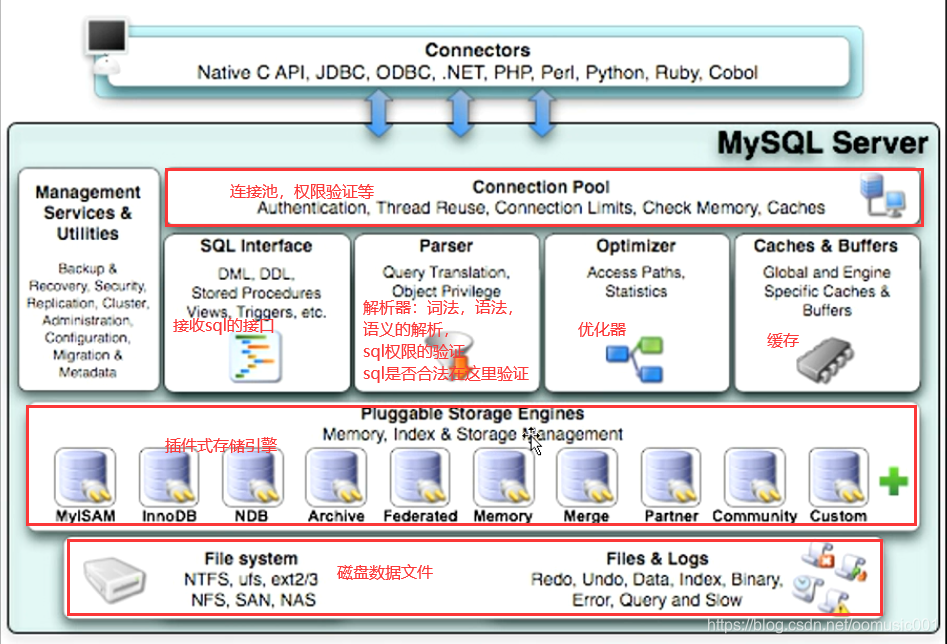
架构分层:
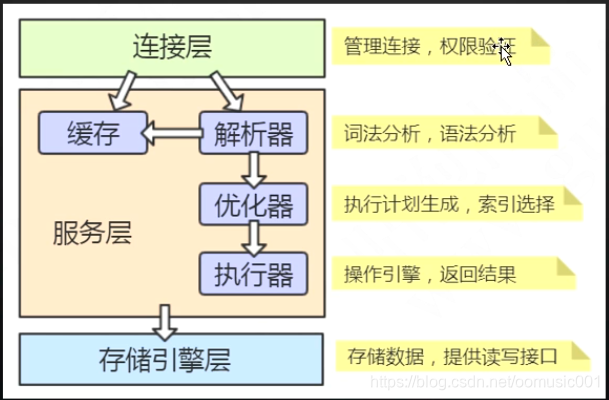
一条更新语句是怎么执行的?
1. 从磁盘/内存读取到数据,返回给server
2.执行器进行修改,
3.将修改结果记录到Undo log
4.记录到Redo log
5.在InnoDB的buffer pool里面修改数据
6.事务
当执行 update user set name = ‘123’ where id = 9;的时候,会加载磁盘上的数据到内存,加载的数据不仅仅是要修改的一条数据,而是最少读取一页(逻辑单位[一打,一套,一栏,])的数据到内存。innodb存储引擎一页默认16kb。这样可以减少内存的浪费。在innodb中使用了缓冲池的技术,客户端和文件之间开辟一块内存区域,下次修改的数据刚好在缓存池中,就不用在读取磁盘了。内存里面的数据修改后,没有同步到磁盘上,称为"脏页" ,后台会有线程将内存中数据刷到磁盘上,称为 "刷脏" . 如果还没有进行刷脏操作,数据库宕机了,数据怎么办呢?通过日志文件实现崩溃恢复。
Redo log:重做日志。如果内存中的日志没有刷到磁盘,会记录在这个日志中。先写日志再写磁盘。
Undo log: 回滚日志。
Binlog:记录事件的,DDL,DML的操作会记录在binlog中。记录的是表结构修改,增删改语句。默认关闭。会带来额外开销。记录的语句。所以做数据恢复需要全量备份数据。
binlog功能:1.数据恢复(需要备份) 2.主从同步(有一个线程从master拿到)
Redo log和Undo log是存储引擎级别的,只有InnoDB有。
binlog是服务级别的,是存储引擎共享的。
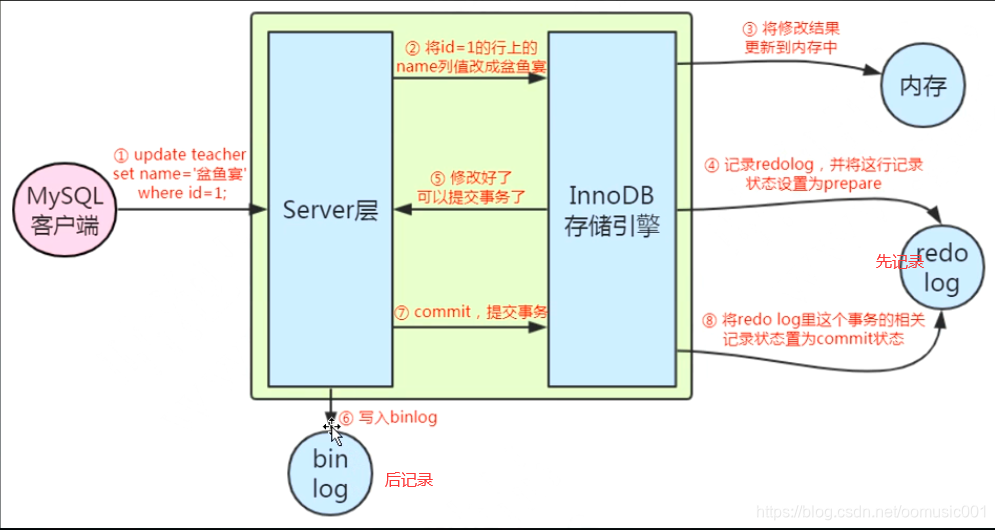
写日志文件的优势:
随机I/O:修改后的数据保存到磁盘,是随机写入的,磁盘的转动寻址会比较慢。
顺序I/O:日志的写入是顺序有序的,不用寻址,速度比较快。
Redo log是InnoDB自己的实现,其他存储引擎没有这个实现,所以其他引擎不支持崩溃恢复。该日志记录的是物理日志,记录了数据做了什么改动,redo log大小是固定的,向redo log记录的时候,会将数据同步到磁盘。
为了提升Redo log的写入效率,在缓冲池和日志直接加入了日志缓存池。
Undo log 和Redo log统称为事务日志。通过Undo log可以实现回滚操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









