






查询缓存
- 针对查询语句,mysql先回去查询缓存(query cache)里面去找缓存,看看之前是否执行过查询命令,查询缓存是以key-value形式保存在内存中,key为sql的查询语句,value为查询的结果。
- 如果查询的语句命中了查询缓存,则直接返回给客户端value的数据,如果没有命中,则继续执行sql查询语句,执行完成后,将结果缓存到查询缓存中。
- 针对更新频繁的表,查询缓存的命中率极低,只要有表的更新操作,则查询缓存就会被清空。
- 在mysql8.0中,直接将这个模块去掉了,没有查询缓存这个阶段了。
解析器
解析器会做两件事情:
-
词法分析
mysql会根据输入的字符串识别出关键字,构建出sql语法树,根据后面的模块获取sql类型,表名,字段名,where条件等 -
语法分析
根据词法的分析结果,语法解析器会根据语法规则,判断输入的slq是否满足mysql的语法
执行sql
每个sql语句的流程分为以下三个阶段:
- prepare阶段,预处理
- optimize阶段,优化阶段
- execute阶段,执行阶段
执行计划由优化器来完成
优化器主要负责将sql的查询语句的执行方案确定下来,比如说表里有多个索引的时候,优化器会基于查询成本的考虑,觉得使用哪个索引。
比如执行
select * from product where id =1可以通过在查询语句前增加explain命令,就是输出这个sql语句的执行计划。
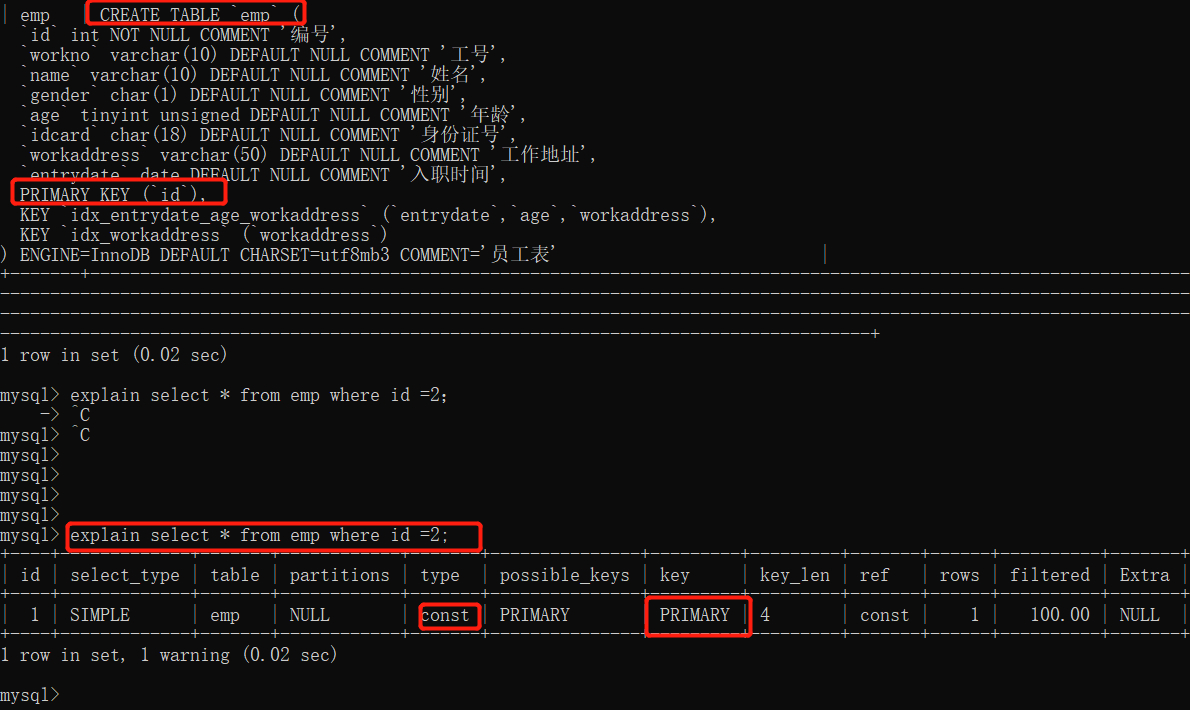
执行佳话站出来type为const, key 为primary 表示通过了主键索引

如果type为All 和key 为null, 这种查询扫描的方式效率是最低的
索引覆盖

当多个索引的时候,优化器会更具查询成本来决定使用哪个索引来执行查询操作。
比如上面的这个entrydate和id,执行计划的中extra显示using index表示为索引覆盖,只是用entrydate一个索引就可以返回结果
原因:
直接在二级索引上能查到结果,二级索引的B+树的叶子节点的数据存储的是主键值,没有必要在主键索引上继续查找了,因为查询主键索引B+树的成本会比查询二级索引的B+树的成本大,优化器基于查询成本的考虑,会选择代价更小的二级索引。

















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









