







文章目录
前言
1. 知道token和tokenization
2.知道N-gram的概念和作用
3.知道文本向量化表示的方法
本文内容是视频学习内容,不喜勿喷
一、文本的tokenization
1.1 概念和工具的介绍
tokenization是通常所说的分词,分出的每一个词语被称为token。
常见的分词工具有很多,如:
- jieba分词
- 清华大学的分词工具THULAC
1.2 中英文分词的方法
- 把句子转化为词语
- 如:“我爱深度学习”可以分为[我,爱,深度学习] - 把句子转化为单个字
- 如:“我爱深度学习”的token是[我,爱,深,度,学,习]
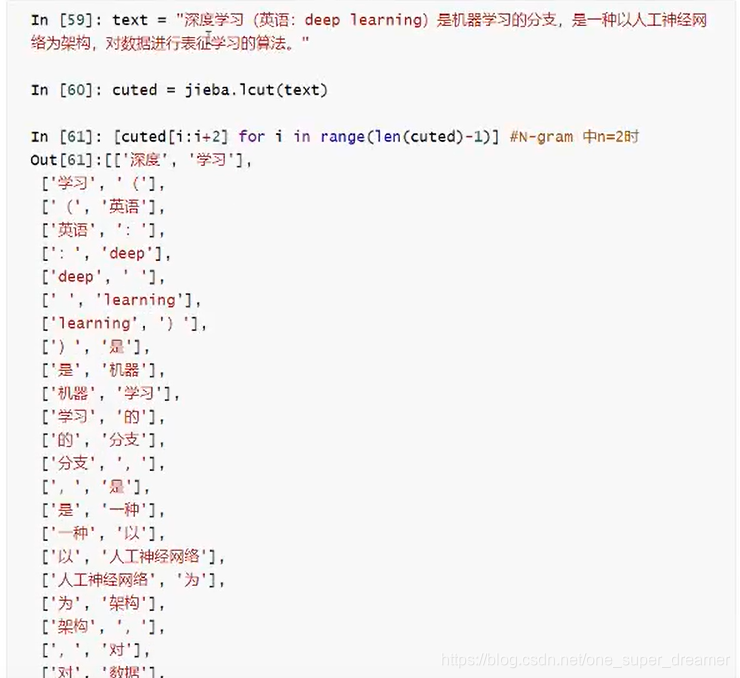
二、N-gram表示方法
句子中用单个字、词来表示,有时也可用2个、3个或多个词来表示。
三、向量化
因为文本不能够直接被模型计算,所以需要将其转化为向量,转化方法有两种:
- 转化为one-hot编码
- 转化为word embedding
1.one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示词典的大小。即:把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,如:

2.word embedding
word embedding是深度学习中表示文本常用的一种方法,和one-hot编码不同,word embedding使用了浮点型的稠密矩阵来表示token,根据词典的大小,我们的向量通常使用不同的维度,如100、256、300等。其中向量中的每一个值都是一个超参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
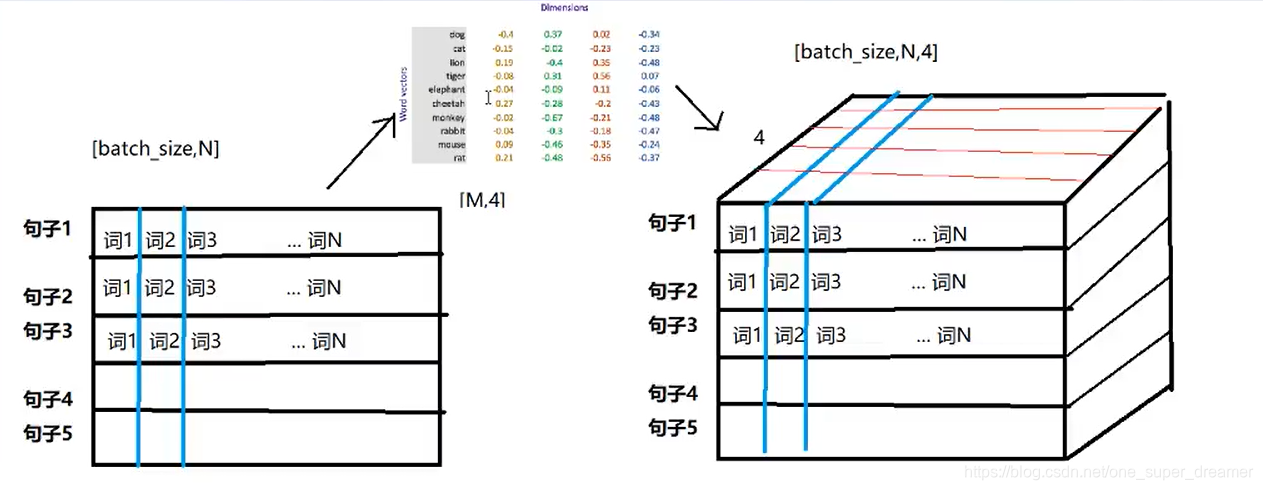
如果我们的文本中有20000个词语,如果使用one-hot编码,我们会有2000020000的矩阵,如果使用word embedding来表示的话,只需要20000维度。形象表示为:

我们会把所有的文本转化为向量,把句子用向量表示,但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。
即:token–>num–>vector
会先将token转化为num,然后从word embedding中查询每个词汇对应的向量。
3. word embedding API
torch.nn.Embedding(num_embeddings,embedding_dim)
参数介绍:
num_embeddings:词典的大小embedding_dim:embedding的维度
使用方法:
embedding = nn.Embedding(vocab_size,300)# 实例化
input_embeded = embedding(input) # 进行embedding的操作
3.数据的形状变化
[batch_size,seq_len]–>[batch_size,seq_len,embedding_dim]

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









