




 本文详细解析了HashMap的内部实现机制,包括其基于数组和链表的底层数据结构,初始化过程,以及如何通过hash算法确定元素存储位置。探讨了HashMap在进行put操作时的扩容策略和元素冲突解决方式。
本文详细解析了HashMap的内部实现机制,包括其基于数组和链表的底层数据结构,初始化过程,以及如何通过hash算法确定元素存储位置。探讨了HashMap在进行put操作时的扩容策略和元素冲突解决方式。
一 、HashMap实现原理
1. HashMap概述
HashMap是基于Hash表的Map接口的非同步实现,它允许存入null值和null建,但是它不保证存入的顺序与操作顺序一致,主要是它不保证元素的顺序永恒不变。
HashMap底层的数据接口是一个链表散列 的数据结构,既数组和链表的结合体。
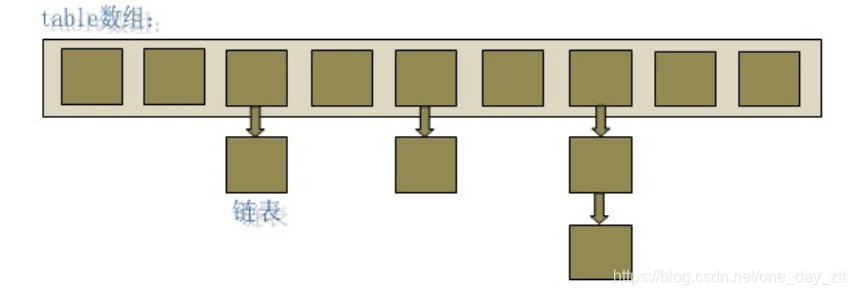
从简单的示意图中可以看出,HashMap底层就是一个数组,数组的每个位置上又是一个链表。
2. 底层代码分析
HashMap<String,Object> hashMap = new HashMap<String,Object>();//当我们创建一个HashMap的时候,会产生哪些操作?
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
/**
* 初始化容量-16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 一个空的Entry数组
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* 存储元素的数组,自动扩容
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* 键值对
*/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* 初始化方法
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
/** * 1.初始化方法 */
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/** * 2.初始化方法 */
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
}
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
private static final long serialVersionUID = 3801124242820219131L;
/**
* 双重链表的一个第一个元素
*/
private transient Entry<K,V> header;
/** * 3.初始化方法 */
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
/**
* LinkedHashMap 中的entry继承了hashMap中的entry
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
/** * 4.初始化方法 */
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
}
通过HashMap类中的成员变量Entry<k,v>[] table,可以看出Entry就是数组中的元素,每个Entry就是一个key-value键值对,它持有一个指向下一个元素的引用,这就构成了链表的数据结构。
关于数组的初始化的时机不是我们在new的时候,是在我们第一次执行put操作的时候:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
/**如果这是一个空的table,就进行初始化*/
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
/**通过hash算法获取hash值*/
int hash = hash(key);
/**根据hash值获取在数组中的位置*/
int i = indexFor(hash, table.length);
/**获取数组在 i 位置上的链表,并进行循环*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
/**如果hash值相等,并且value值相等,value值会进行覆盖,返回之前的value*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果在i位置的entry为null,或者value的值不相同,执行addEctity()方法
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前数组已经饱和,并且当前位置的entry不是null,数组进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容操作,原数组需要重新计算在新数组中的位置,并放进去,这里会产生性能损耗
// 如果我们能已知元素个数,就可以在创建的时候进行生命即可。
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建新的Entry
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
根据hash算法得出元素在数组中的存放位置,如果改位置上已经存在元素,那么这个位置上的元素将以链表的形式存放,新加入的放在头部,后加入的在尾部。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
根据key的hash值来决定元素在数组中的位置,如何计算这个位置就是hash算法。通过hash算法尽量使得数组的每个位置上都只有一个元素,当我们再次get()的时候,直接去数组中取就可以,不用再遍历链表。
hash(int h)根据key的hashcode重新计算一次散列,此算法加入了高位计算,防止低位不变,高位变化时,造成hash的冲突。

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









