






ElasticSearch 7.6.0 学习笔记
一、ElasticSearch中的倒排索引
1、正排索引
与ElasticSearch所使用的倒排索引对应的“正排索引”
正排索引也称为“前向索引”,它是创建倒排索引的基础。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号对应的索引信息,将其直接删除。
他适合根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
比如有几个文档及里面的内容,他正排索引构建的结果如下:
| 文档 | 文档内容 |
|---|---|
| 1 | elasticsearch是最流行的搜索引擎 |
| 2 | 大数据开发语言——Python |
| 3 | VIP创新教育——elasticsearch |
优点:工作原理非常简单。
缺点:检索效率太低,只能在一些简单的场景下使用。
2、倒排索引
本次学习的主角“倒排索引”,根据字面意思可以知道他和正序索引是反的。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如:“的”、”这些“,剩下的都是关键词,每个关键词都有自己的ID)。例如”文档1“经过分词,提取三个关键词,每个关键词都会记录他所在文档中出现的品率及出现的位置。
那么上面文档及内容构建的倒排索引结果会如下表(注:这个图里没有记录该词出现在哪个文档中的具体位置):
| 单词 | 文档ID列表 |
|---|---|
| ElasticSearch | 1,3 |
| 流行 | 1 |
| 搜索引擎 | 1 |
| 大数据 | 2 |
| 开发 | 2 |
| 语言 | 2 |
| Python | 2 |
| VIP | 3 |
| 创新 | 3 |
| 教育 | 3 |
3、倒排索引的查询过程
比如我们要查询elasticsearch这个关键词在哪些文档中出现过。首先我们通过倒排索引可以查询到该关键词出现的文档位置是在1和3中;然后再通过正排索引查询到文档1和3的内容返回结果。
二、倒排索引的组成
倒排索引主要由单词词典Term Dictionary和倒排索引Posting List及倒排文件Inverted File组成。
关系图如下:
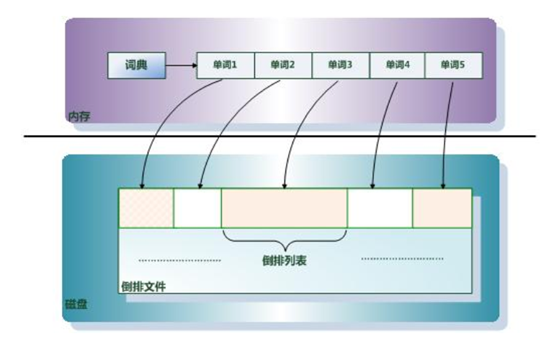
1、单词词典(Term Dictionary)
搜索引擎通常索引单位是单词,单词是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向倒排列表的指针。
2、倒排列表(Posting List)
倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率做关键性算分,每条记录称为一个倒排项Posting。根据倒排列表,即可获知哪些文档包含某个单词。
3、倒排文件(Inverted File)
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
4、以查找搜索引擎为例:
文档
| 文档ID | 文档内容 |
|---|---|
| 1 | elasticsearch是最流行的搜索引擎 |
| 2 | 大数据开发语言——Python |
| 3 | VIP创新教育——elasticsearch |
Posting List(ElasticSearch)
| DocId | TF | Position | Offset |
|---|---|---|---|
| 1 | 1 | 2 | <18, 22> |
| 3 | 1 | 0 | <0, 4> |
查找过程
5、单词词典查询定位问题
对于一些规模很大的文档集合来说,它里面可能包括了上百万关键单词term,能否快速定位到具体单词term,这会直接影响到响应速度。
假设我们有很多个term,比如:
Carla, Sara, Elin, Ada, Patty, Kate, Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term,排序之后就变成了:
Ada, Carla, Klin, Kate, Patty, Sara, Selena
这样我们就可以用二分查找的方式,比全遍历更快的找出目标term,这个就是Term Dictionary。有了Term Dictionary之后,可以用logN次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access大概需要10ms的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里,但是整个Term Dictionary本身又太大了,无法完整地放到内存里。于是就有了Term Index。Term Index有点像一本字典的大的章节表。
目前常用的方式是通过hash加链表结构和树型结构(b树或者b+)
1)hash加链表
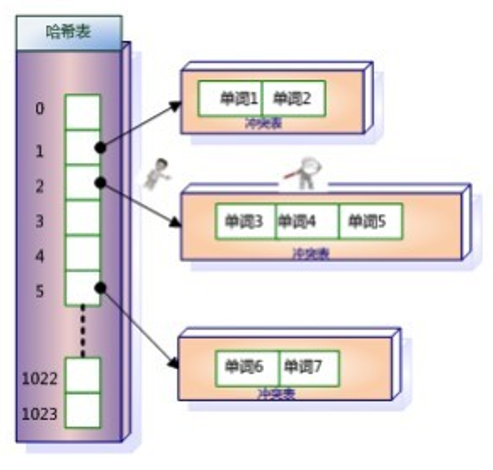
这是很常用的一种数据结构。这种方式就可以快速计算单词的hash值,从而定位到他所在的hash 表中,如果该表又是一个链表结构(两个hash值可能会一样),那么就需要遍历这个链表然后再对比返回结果。这种方式最大的缺点就是如果有范围查询的时候就很难做到。
2)树型结构
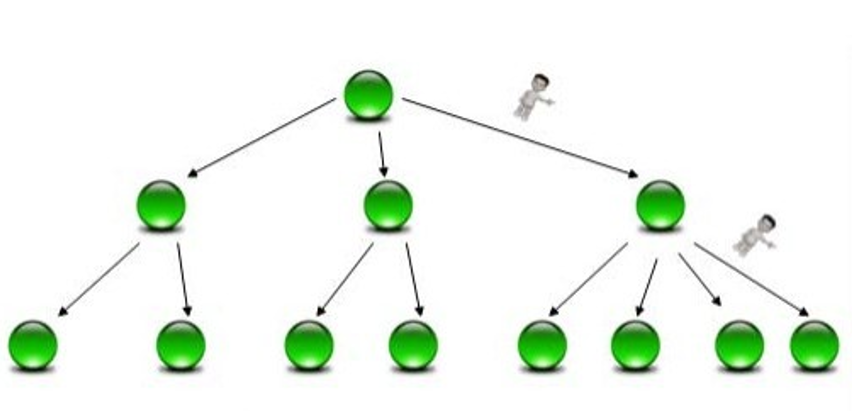
B树(或B+树)是另外一种高效查找结构,这是是一个B树结构示意图。B树与哈希方式查找不同,B树需要字典项能够按照大小排序(数字或字符序),而哈希方式则无需数据满足此项要求。
B树形成了层级查找结构,中间点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。
参考:
https://www.jianshu.com/p/c96576fcbcd9
三、分词器介绍以及中文分词器ik的安装与使用
1、分词的含义
把文本转换成一个个的单词,分词称之为analysis。es默认只对英文语句做分词,中文不支持,每个中文都会被拆分为独立的个体
示例
-
被分词对象:

-
返回结果
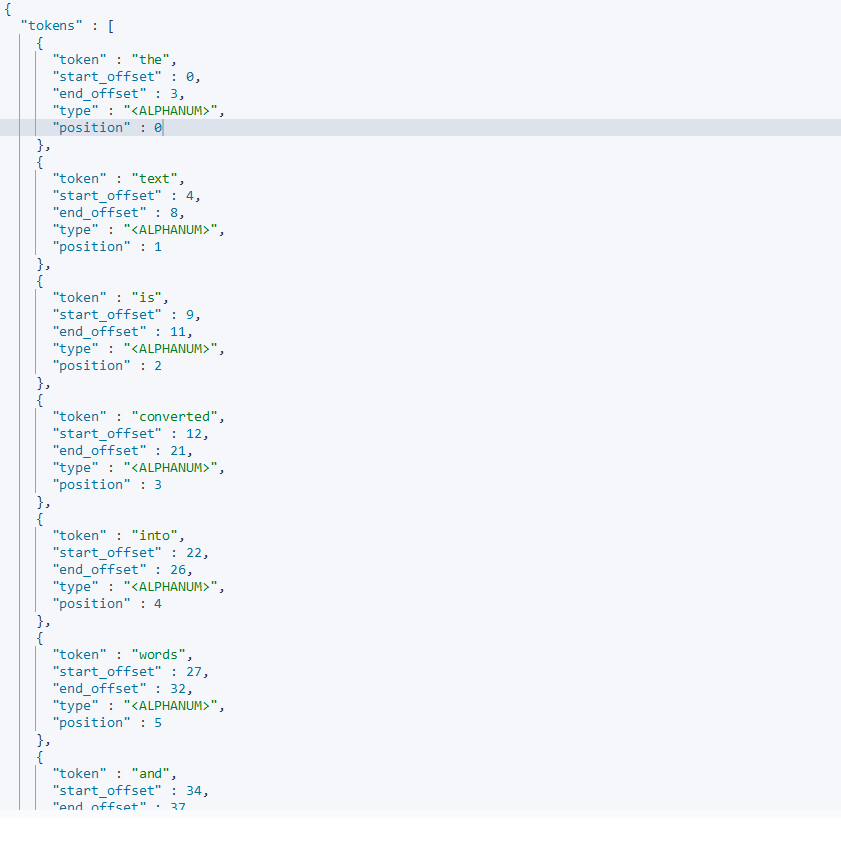
-
2、如果想在某个索引下进行分词
POST /my_doc/_analyze
{
"analyzer": "standard",
"field": "name",
"text": "text文本"
}
3、es内置分词器
standard:默认分词,单词会被拆分,大小写会转换为小写。simple:按照非字母分词,大写转为小写。whitespace:按照空格分词,忽略大小写。stop:去除无意义单词,比如the/a/an/is…keyword:不做分词,把整个文本作为一个单独的关键词
4、建立ik中文分词器
1)下载
Github:https://github.com/medcl/elasticsearch-analysis-ik
这里需要选择和自己使用的es版本一致的ik。
2)解压
将下载后的压缩文件解压到es目录下的plugins/ik中,如果plugins中没有ik目录新建就行。
3)重启es
4)ik_max_word 和 ik_smart 什么区别
ik_max_word:会将文本做最细粒度拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌”,会穷尽各种可能的组合,适合Term Queryik_smart:会做最粗粒度拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、国歌“,适合Phrase
5)测试
-
准备分词
-
返回结果
-
ik_smart
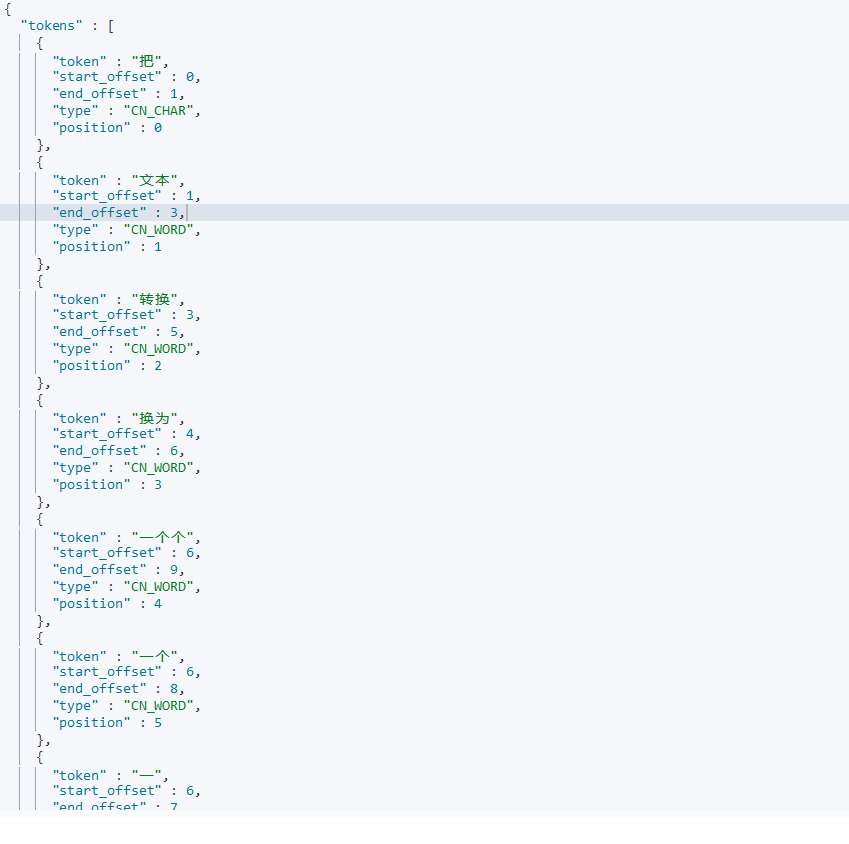
-
ik_max_word

-
6)自定义中文词库
-
进入
IKAnalyzer.cfg.xml配置如下<!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">custom.dic</entry> -
保存后,在同级目录下建立
custom.dic我 喜欢 学习 ElasticSearch -
重启es
-
测试
输入测试文本,观察输出结果是不是按照新建立的字典输出的结果。
四、使用Kibana进行增删改查操作
1、添加索引
-
添加索引
# 直接使用 PUT /hellof/ 可以按照默认配置直接创建 PUT /hellof/ { "settings": { "number_of_shards": 3, "number_of_replicas": 0 } } -
返回结果
-
查看已经创建好的索引的配置
GET /hellof/_settings -
查看所有索引的配置
GET _all/_settings
2、在索引下创建文档
-
创建文档
PUT /hellof/user/1 { "first_name": "f", "last_name": "hell", "age": 23, "about": "在校大学生,目前正在学习ElasticSearch", "interests":["Music", "Movies"] }-
返回结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}). { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 1, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }
-
-
创建文档的适合id可以省略不写,系统会自动添加
3、查询文档
-
根据文档id进行查询
GET /hellof/user/1-
返回结果
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead. { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "first_name" : "f", "last_name" : "hell", "age" : 23, "about" : "在校大学生,目前正在学习ElasticSearch", "interests" : [ "Music", "Movies" ] } }
-
-
查看文档的部分信息
GET /hellof/user/1?_source=age,about-
返回结果
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead. { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "about" : "在校大学生,目前正在学习ElasticSearch", "age" : 23 } }
-
4、修改文档
-
修改文档,使用一个新的文档覆盖之前的文档,会覆盖文档所有字段的值
PUT /hellof/user/1 { "first_name": "f", "last_name": "hello", "age": 23, "about": "在校大学生,目前正在学习ElasticSearch,并且我非常喜欢它", "interests":["Music", "Movies"] }-
返回结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}). { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 1, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }
-
-
修改文档中指定字段的值
POST /hellof/user/1/_update { "doc":{ "age": 25 } }-
返回结果
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead. { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 3, "result" : "updated", "_shards" : { "total" : 1, "successful" : 1, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 }
-
5、删除文档
-
删除文档
DELETE /hellof/user/1-
返回结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the /{index}/_doc/{id} endpoint instead. { "_index" : "hellof", "_type" : "user", "_id" : "1", "_version" : 4, "result" : "deleted", "_shards" : { "total" : 1, "successful" : 1, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 }
-
-
删除索引
DELETE hellof-
返回结果
{ "acknowledged" : true }
-
参考
https://www.codercto.com/a/65692.html

















 5316
5316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









