







 文章对比了顺序表和链表在插入、删除操作上的差异,顺序表操作可能涉及大量元素移动,而链表只需修改指针。顺序表支持随机存取,但空间利用率可能较低,而链表虽然不支持随机存取,但在插入删除上更高效。此外,文章讨论了存储空间的分配问题,顺序表需一次性分配,而链表则不需要。
文章对比了顺序表和链表在插入、删除操作上的差异,顺序表操作可能涉及大量元素移动,而链表只需修改指针。顺序表支持随机存取,但空间利用率可能较低,而链表虽然不支持随机存取,但在插入删除上更高效。此外,文章讨论了存储空间的分配问题,顺序表需一次性分配,而链表则不需要。
1. 插入删除操作对比
1. 顺序表插入删除元素
插入策略:
在某个位置插入元素时, 把从该位置开始的所有元素都往后挪一个位置, 规定顺序表最后一个元素后面的位置也是一个可插入位置. 后面的元素先往后挪动位置.
删除策略:
在某位置删除元素, 把从该位置之后的所有元素都往前挪一个位置, 把要删除的元素覆盖掉即可. 前面的元素先往前挪动位置.
#include <iostream>
const int MAX_SIZE = 10;
//在C++中,整型数组是值类型。这意味着当你创建一个整型数组时,实际上会在内存中分配一块连续的内存来存储数组的元素。
//当你将整型数组分配给另一个变量或传递给函数时,会发生数组的拷贝,新数组的修改不会影响原始数组。
//在 C++ 中,不能直接返回整型数组。这是因为数组是一个连续的内存块,无法直接通过返回值的方式来传递。
/// <summary>
/// 初始化数组
/// </summary>
void initArr(int *arr, int length) {
if (length > MAX_SIZE) {
printf("数组长度超过最大长度!");
return;
}
for (int i = 0; i < length; i++)
{
arr[i] = i;
}
}
/// <summary>
/// 打印数组元素
/// </summary>
/// <param name="arr"></param>
void printArr(int *arr, int length) {
//在 C++ 中,指针变量的初始值为 nullptr,而不是 NULL。
//因此,应该将判断条件修改为 arr == nullptr,以检查数组是否为空。
//if (arr[0] == NULL)
if (arr == nullptr) {
printf("数组为空!\n");
return;
}
//另外,计算数组长度的方式也是错误的。在 C++ 中,数组作为函数参数传递时会被转换为指针,
//因此无法通过 sizeof 运算符来获取数组的长度。你可以通过传递数组的长度作为额外的参数来解决这个问题。
//int length = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < length; i++)
{
printf("数组元素: %d\n", arr[i]);
}
}
/// <summary>
/// 数组插入元素
/// </summary>
/// <param name="arr">要插入的数组</param>
/// <param name="length">数组插入元素前的长度</param>
/// <param name="index">要插入的位置</param>
/// <param name="data">要插入的值</param>
void insertElement(int arr[], int &length, int index, int data) {
if (index < 0 || index > length) {
printf("索引越界!\n");
return;
}
if (length >= MAX_SIZE) {
printf("数组元素已满!\n");
return;
}
for (int i = length + 1; i > index; i--)
{
arr[i] = arr[i - 1];
}
arr[index] = data;
length++;
}
/// <summary>
/// 数组删除元素
/// </summary>
/// <param name="arr">要删除的数组</param>
/// <param name="length">数组删除元素前的长度</param>
/// <param name="index">要删除的元素的索引</param>
/// <returns></returns>
int deleteElement(int arr[], int &length, int index) {
if (index < 0 || index >= length) {
printf("索引越界!\n");
return -1;
}
if (length <= 0) {
printf("数组长度为空\n");
return-1;
}
int temp = arr[index];
for (int i = index; i < length; i++)
{
arr[i] = arr[i + 1];
}
length--;
return temp;
}
int main()
{
int arr[MAX_SIZE]; //为数组开辟的存储空间的大小为MAX_SIZE
int length = 6;
initArr(arr, length);
printArr(arr, length);
insertElement(arr, length, 1, 9999);
printf("--------------插入元素后--------------\n");
printArr(arr, length);
int element = deleteElement(arr, length, 5);
if (element != -1) {
printf("--------------删除元素后--------------\n");
printf("删除的元素: %d\n", element);
printArr(arr, length);
}
}代码1: 顺序表(数组)的插入删除操作
2. 单链表插入删除操作
插入策略:
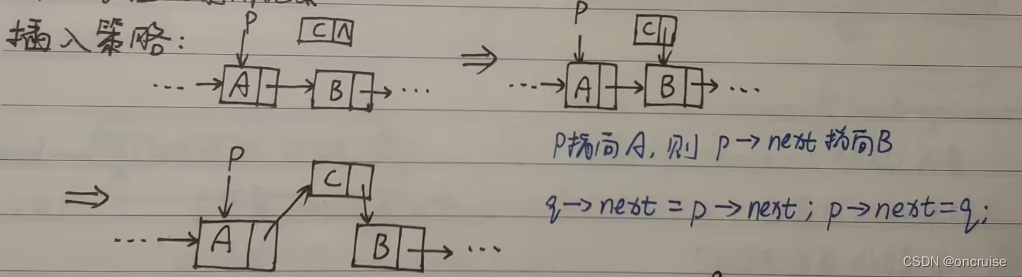
单链表的插入操作
删除策略:
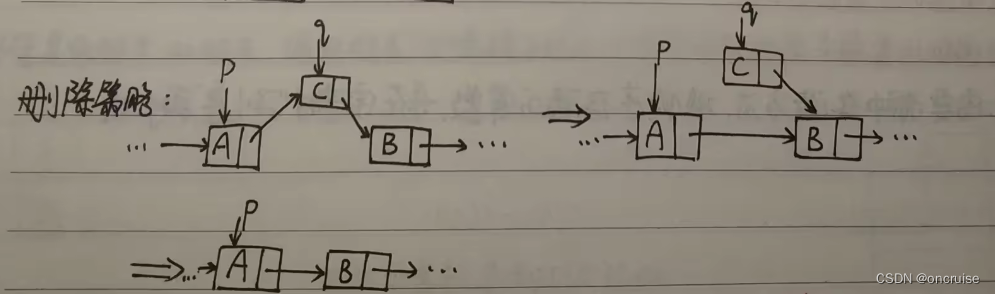
单链表的删除操作
#include <iostream>
typedef struct LNode {
int data;
struct LNode* next;
}LNode;
/// <summary>
/// 判断链表是否非空
/// </summary>
/// <param name="p"></param>
bool linkedListIsNotNull(LNode* p) {
if (p == NULL) {
return false;
}
return true;
}
/// <summary>
/// 遍历输出链表各个结点的值
/// </summary>
/// <param name="firstNode"></param>
void traverseLinkedList(LNode* p) {
while (p != NULL) {
// 对当前节点进行操作,打印节点的数据
printf("%d\n", p->data);
// 移动到下一个节点
p = p->next;
}
}
/// <summary>
/// 插入元素
/// </summary>
/// <param name="p">插入位置前面的元素</param>
/// <param name="q">要插入的元素</param>
void insertElement(LNode *p, LNode *q) {
q->next = p->next;
p->next = q;
}
/// <summary>
/// 删除元素
/// </summary>
/// <param name="p">要删除的元素的前一个元素</param>
/// <returns></returns>
LNode* deleteElement(LNode* p) {
LNode* q = p->next;
p->next = q->next;
q->next = NULL;
return q;
}
int main()
{
LNode* A;
A = new LNode;
LNode* B;
B = new LNode;
LNode* C;
C = new LNode;
A->data = 10;
B->data = 20;
C->data = 30;
A->next = B;
B->next = NULL;
C->next = NULL;
LNode* p = A;
LNode* q = C;
bool isNotNull = linkedListIsNotNull(p);
if (isNotNull) {
insertElement(p, q);
traverseLinkedList(p);
printf("---------------------------\n");
LNode* q =deleteElement(p);
free(q);
traverseLinkedList(p);
}
else {
printf("链表为空!");
}
}
代码2: 单链表的插入删除操作
对比:
在顺序表中 和删除元素可能(不是一定)会移动大量元素的连带操作(插入或删除操作发生在表尾位置例外), 而链表不会, 链表只需修改指针, 元素无需移动.
2. 元素的定位问题
顺序表元素定位只要知道某个元素的下标, 就定位到了该元素; 链表元素定位需要一个搜索的过程.
在单链表中找到任意一个结点的位置不像顺序表那么简单, 因为顺序表支持随机存取(任意存取), 而单链表不支持.
为了尽可能弥补单链表不能随机存取的不足, 开发了双链表, 循环单链表和循环双链表等存储结构, 这些存储结构可以在仅知道链表中任一个结点地址的情况下推知其余所有结点的地址, 但仍然不支持随机存取.
有时还会给链表定义一个额外的指针, 最常见的是表尾指针, 它指向链表中最后一个结点. 可以借助它来提高某些常用操作的执行效率. (尾指针始终指向尾结点)
3. 存储空间相关问题
如果为顺序表分配存储空间, 必须一次性把存储空间划分完, 不能分批次划分.
从整体来看, 顺序表在很多情况下都会比链表的空间利用率低一些, 因为顺序表划分的存储空间可能没有完全利用.
而对于存储单元, 顺序表的存储空间利用率大于链表的存储空间利用率, 因为链表中有指针, 它我们要存储的数据信息.
线性表采用顺序存储结构, 必须占用一片连续的存储单元, 而采用链式存储结构则不需要这样.
从表整体来看, 一般顺序表存储空间利用率低于链表; 而从单个存储单元来看, 顺序表存储空间利用率要高于链表.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









