







Windows部署Llama3.1
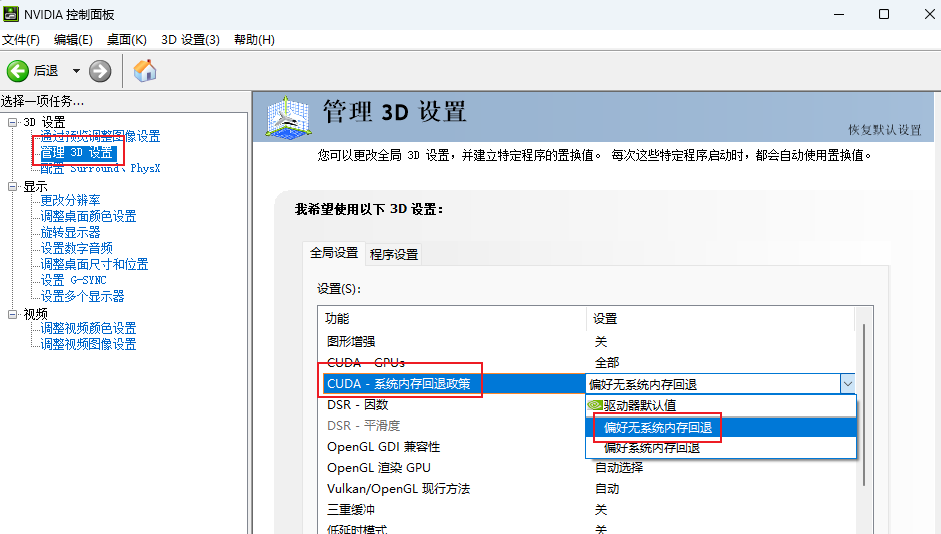
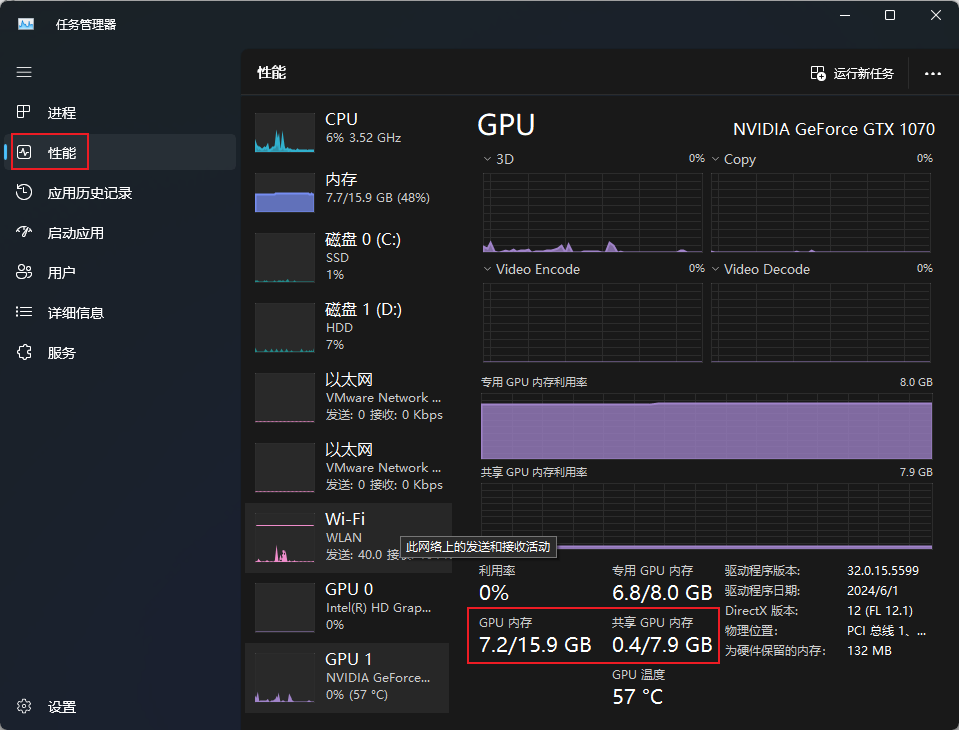
nvdiia关闭GPU共享内存
nVidia控制面板—》 管理3D设置—》CUDA - 系统内存回退政策—》 偏好无系统内存回退。
本地电脑安装的硬件要求
Windows:3060以上显卡+8G以上显存+16G内存,硬盘空间至少20G
Mac:M1或M2芯片 16G内存,20G以上硬盘空间
在开始之前,首先我们需要安装Ollama客户端,来进行本地部署Llama3.1大模型
官方下载:
https://github.com/ollama/ollama
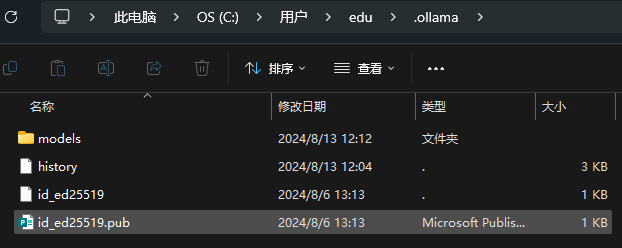
默认配置文件位置
C:\Users\${username}\.ollama
配置变量
https://blog.youkuaiyun.com/scj0725/article/details/138087028
指定OLLAMA_MODELS变量
安装模型默认都是安装在c盘的,如果c盘空间不足可以指定安装模型位置。
默认的models目录在C:\Users\${username}\.ollama\models
在系统变量中添加一个名为:OLLAMA_MODELS的变量名,路径选择一个合适的位置。
# 设置ollma缓存 环境变量
## Machine参数: 表示设置的是系统变量,而不是用户变量
[Environment]::SetEnvironmentVariable("OLLAMA_MODELS", "D:\opt\ollama-windows-amd64\OLLAMA_MODELS", "Machine")

# 查看变量
ls env:OLLAMA_MODELS

启动服务
# 启动服务端
ollama serve
服务端暴露的端口是127.0.0.1:11434

run模型
上传了自己的docx文件,结果它的回答完全不按文档来,乱答一气,这个跟模型有关,中文的话试一下qwen模型,至少需要8G显存
# 安装运行qwen:7b模型--中文优化
ollama run qwen:7b
安装llama3.1-8b,至少需要8G显存
# 安装llama3.1-8b模型
ollama run llama3.1:8b
安装llama3.1-70b,至少需要大约 70-75 GB 显存,适合企业用户,安装命令就是
# 安装llama3.1:78b模型
ollama run llama3.1:78b
安装llama3.1-405b,这是一个极其庞大的模型,安装和运行它在本地需要非常高的显存和硬件资源,至少需要大约 400-450 GB 显存,适合顶级大企业用户,安装命令就是
# 安装llama3.1:405b模型
ollama run llama3.1:405b
安装图形化界面anythingllm-desktop
上传的文件存储在 C:\Users\${username}\AppData\Roaming\anythingllm-desktop
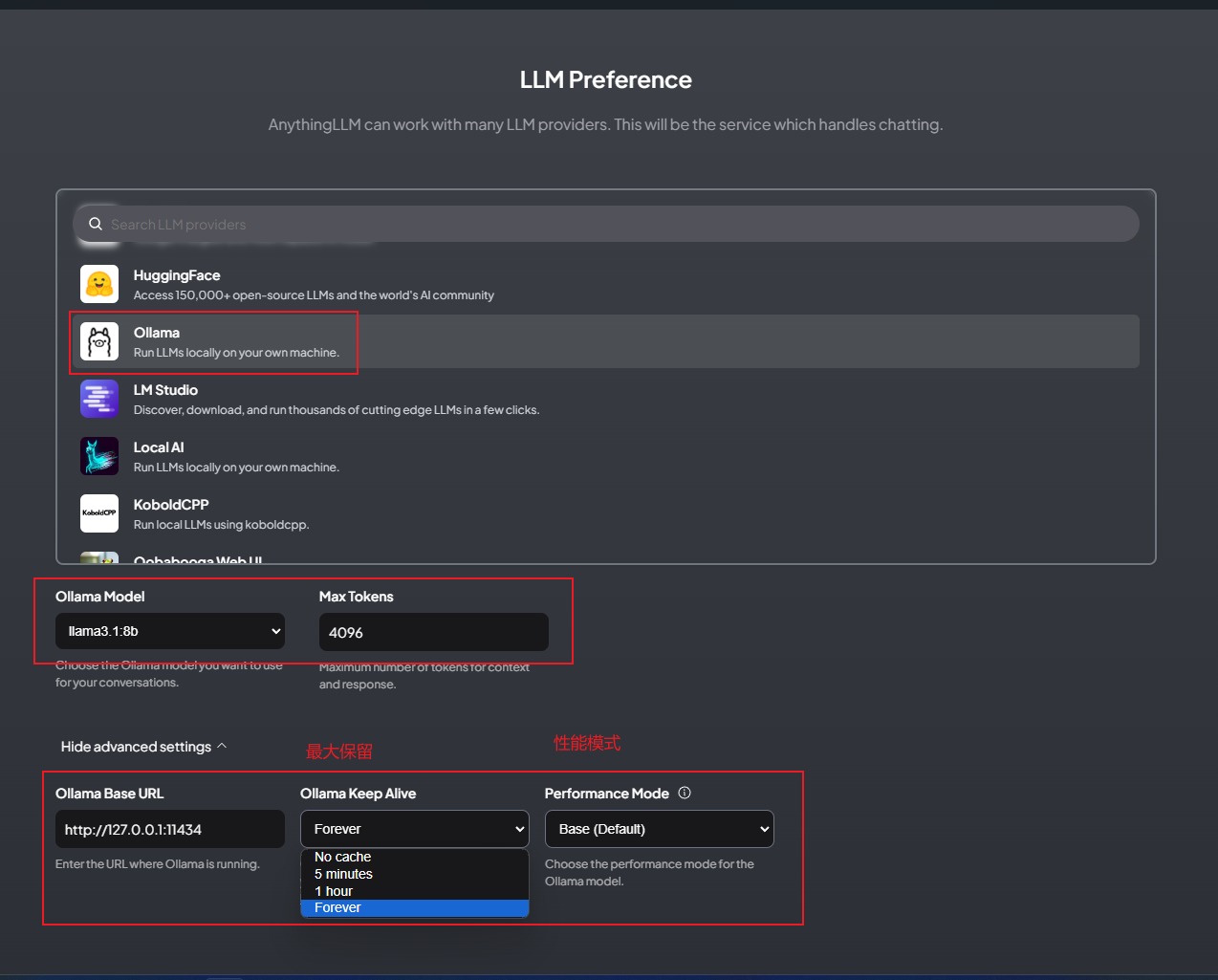
将文档保存嵌入工作区向量数据库
注意上传的文件编码格式要求是utf8,否则是乱码。
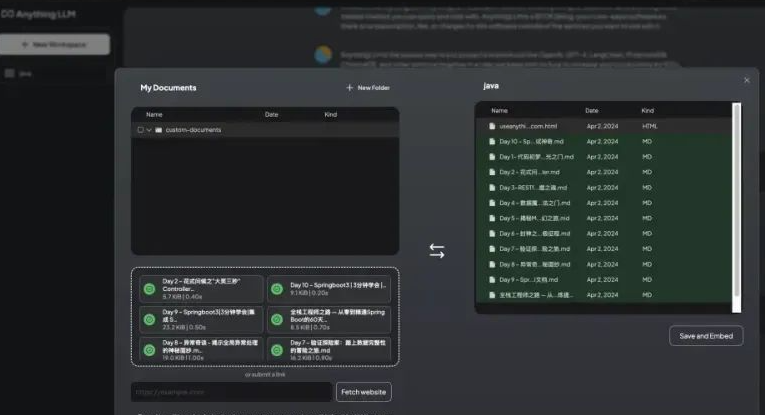
根据知识库中上传的文档,进行知识问答。
注意:如果上传的训练文本格式为txt,编码格式要求为uft8,否则识别乱码。
WindowsServer安装生产anythingllm(非必须)
https://github.com/Mintplex-Labs/anything-llm/blob/master/BARE_METAL.md
安装nodejs
# 安装nodejs-lts
choco install nodejs-lts -y
# 修改成淘宝镜像源
npm config set registry https://registry.npmmirror.com
# 验证国内源
npm config get registry
如果返回https://registry.npmmirror.com,说明镜像配置成功。
安装yarn
# 安装yarn
npm install --global yarn
# 安装依赖
npm install sharp
# 查看yarn版本
yarn --version
克隆代码
# 克隆代码
git clone https://github.com/Mintplex-Labs/anything-llm.git
cd anything-llm
配置yarn加速
https://help.aliyun.com/document_detail/202442.html
在项目根路径中创建.yarnrc
registry "https://registry.npmmirror.com"
sass_binary_site "https://npmmirror.com/mirrors/node-sass/"
phantomjs_cdnurl "https://cdn.npmmirror.com/binaries/phantomjs"
electron_mirror "https://cdn.npmmirror.com/binaries/electron/"
sqlite3_binary_host_mirror "https://foxgis.oss-cn-shanghai.aliyuncs.com/"
chromedriver_cdnurl "https://cdn.npmmirror.com/binaries/chromedriver"
安装依赖
# 安装所有依赖项
yarn setup
# 创建基本 ENV 文件,用于在服务启动时读取实例设置
cp server/.env.example server/.env
确保文件至少server/.env包含这些启动项。这些值将保留,并且该文件将在您首次成功启动后自动写入和管理。
STORAGE_DIR="/your/absolute/path/to/server/storage"
编辑frontend/.env文件,将VITE_BASE_API设置为/api, .env 中记录了您应该使用哪一个。
# VITE_API_BASE='http://localhost:3001/api' # Use this URL when developing locally
# VITE_API_BASE="https://$CODESPACE_NAME-3001.$GITHUB_CODESPACES_PORT_FORWARDING_DOMAIN/api" # for Github Codespaces
VITE_API_BASE='/api' # Use this URL deploying on non-localhost address OR in docker.
卸载删除
直接在你的安装目录下,删除ollama文件夹即可!所有下载的数据和大模型文件都在里面,默认的安装目录是:C:\Users\你自己的用户名\.ollama
如果你没有可运行的显卡,那么可以在Huggingface平台上使用,因为huggingFace 上已经托管了Llama3.1大模型https://www.freedidi.com/13105.html#,现在完全免费使用!
ollama常用命令
# 启动ollama
ollama serve
# 从模型文件创建模型
ollama create
# 显示模型信息
ollama show
# 运行模型
ollama run
# 从注册表中拉取模型
ollama pull
# 将模型推送到注册表
ollama push
# 列出模型
ollama list
# 复制模型
ollama cp
# 删除模型
ollama rm
# 获取有关任何命令的帮助信息
ollama help
常见问题



















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











