




通过 wget 完整复制网站的详细步骤
目录
-
下载并解压
wget
1.1 下载wget
1.2 解压文件
1.3 移动文件夹到固定目录 -
以管理员身份运行 CMD 并切换到
wget目录
2.1 打开管理员权限的 CMD
2.2 切换到wget目录
2.3 验证wget是否可用 -
使用
wget测试复制网站
3.1 运行下载命令
3.2 参数解释
3.3 等待下载完成
3.4 验证结果 -
可能遇到的问题及解决方法
4.1 权限不足
4.2 路径错误
4.3 下载速度过快导致被封禁
4.4 动态内容无法下载
第一步:下载并解压 wget
1.1 下载 wget
打开浏览器,访问 EternallyBored 的 wget 下载页面。
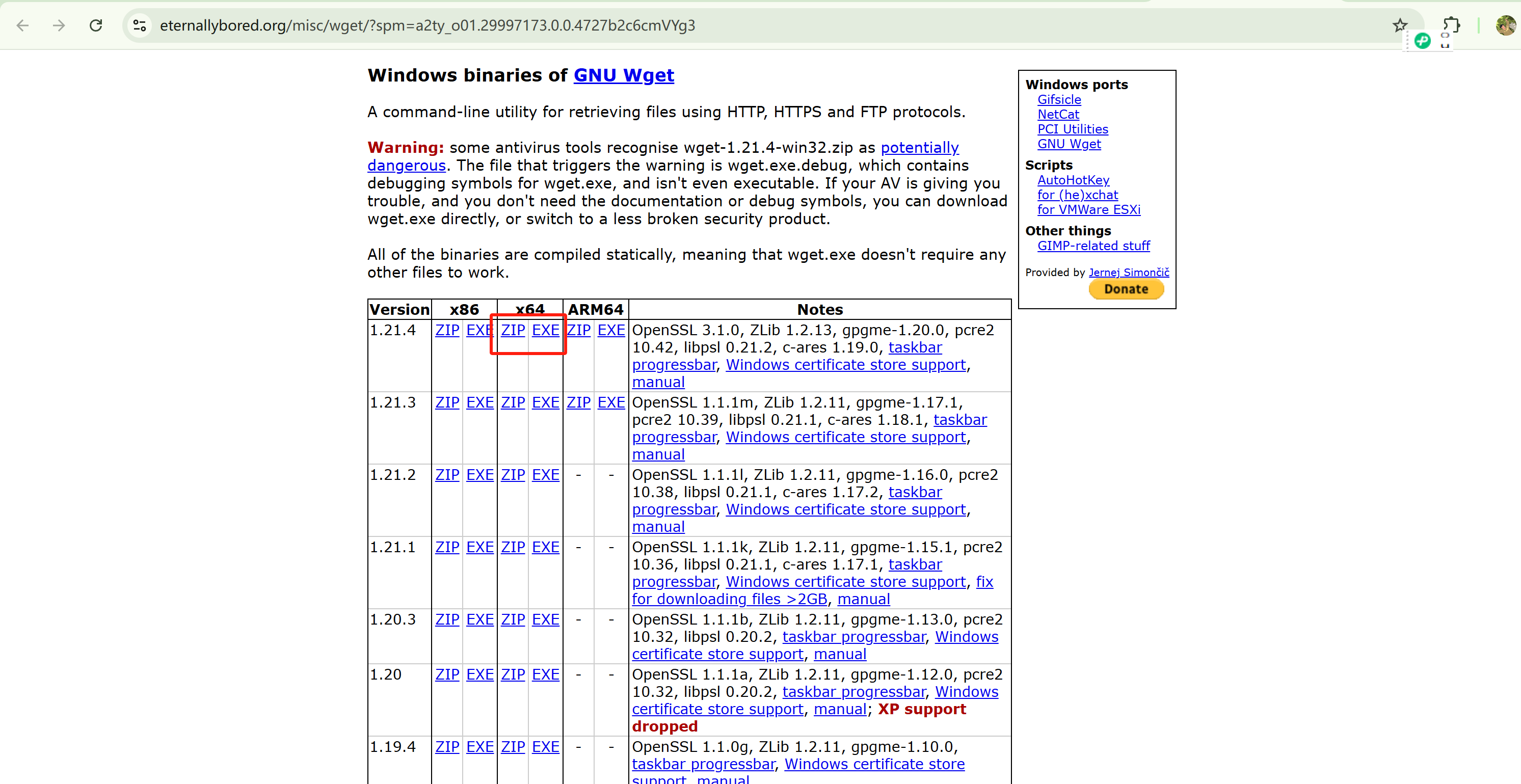
- 根据你的系统架构选择合适的版本:
- 如果是 64 位系统,下载 x64 版本(如
wget-1.21.4-win64.zip)。
- 如果是 64 位系统,下载 x64 版本(如
- 下载完成后,你会得到一个 ZIP 文件(如
wget-1.21.4-win64.zip)。
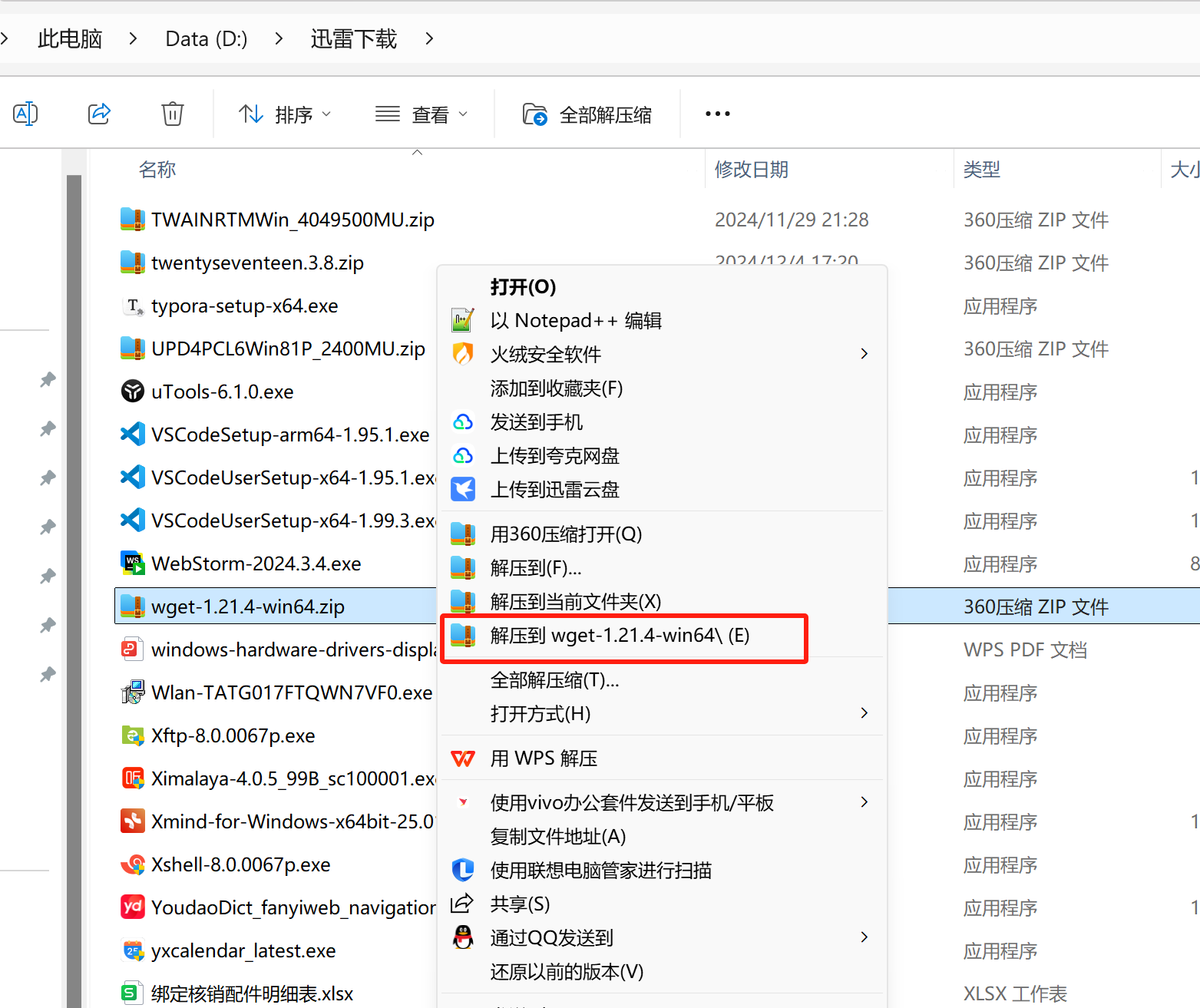
1.2 解压文件
使用解压缩工具(如 WinRAR 或 Windows 自带的解压功能)解压 ZIP 文件。
- 解压后会得到一个名为
wget-1.21.4-win64的文件夹。
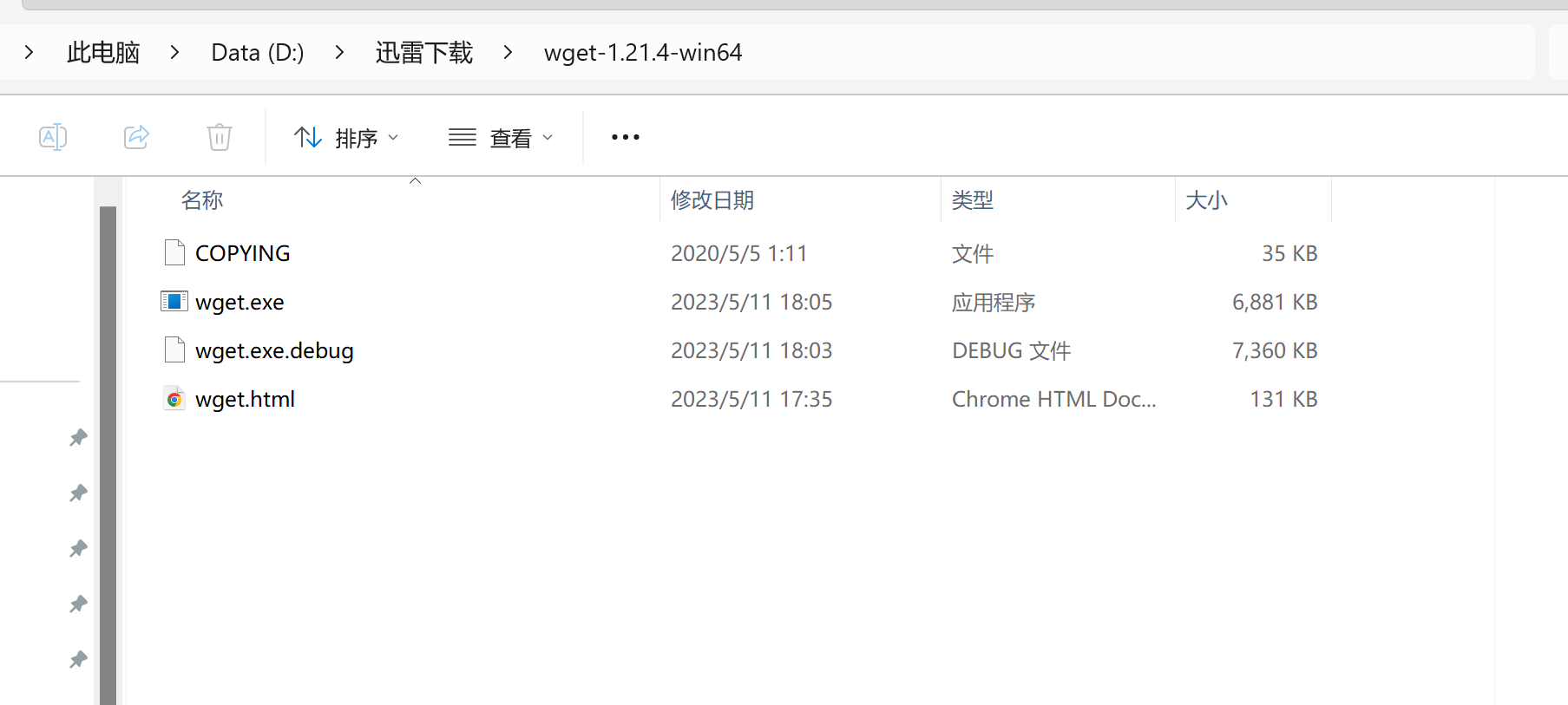
- 文件夹中包含以下文件:
wget.exe(核心程序)- 其他辅助文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









