




 本文深入探讨CNN的学习机制,包括卷积与池化层如何提取特征,全连接层的作用,以及输出层如何工作。并通过实例展示CNN在AlphaGo、语言识别和文字处理等领域的应用。
本文深入探讨CNN的学习机制,包括卷积与池化层如何提取特征,全连接层的作用,以及输出层如何工作。并通过实例展示CNN在AlphaGo、语言识别和文字处理等领域的应用。
文章目录
前言
上篇分析了CNN的构架,究其原因就是CNN比起DNN大大的减少了参数。李宏毅学习笔记10.CNN(上)
公式输入请参考:在线Latex公式
DNN由于很复杂,所以可解释性不强,对于我们来说DNN就像是黑盒子,虽然效果不错,但是我们不知道它具体是如何实现的,所以在一些行业应用上DNN不怎么使用,例如用DNN来判别信用卡申请(本例子由支书提供)。本节开篇老师带我们大概分析一下CNN是如何进行学习的,这里老师用了一个非常奇妙的思路!在CNN应用中还分析了AlphaGo的CNN构架与常规CNN有什么不一样。
CNN的学习机制初探
convolution+Max Pooling部分
先上个上篇中讲的CNN构架
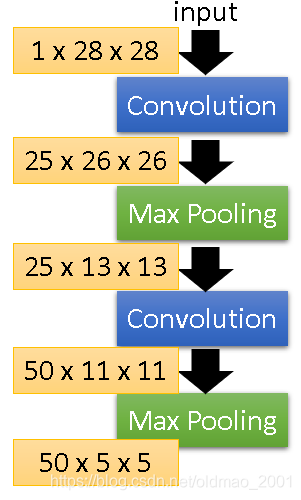
第一个convolution+Max Pooling操作比较好理解,根据上篇笔记的内容可知,这里是用25个33的FIlter对输入的pixel进行特征的提取,得到Feature Map,而且这里如果把Filter的weight拿出来,是可以看出来要提取的特征是什么。
第二个convolution+Max Pooling操作的时候,输入的不再是pixel了,而是上一次操作得到结果,虽然Filter的大小还是33,但是它对于原输入的图像来说,覆盖的范围要大(第一步操作相当于把图片缩小了),那么这个时候的Filter要提取的特征是什么呢?
从上图可知,第二个convolution操作的输出是11*11的matrix,我们把50个Filter中的第k个Filter拿出来,如下图所示,里面的每个元素我们用
a
i
j
k
a_{ij}^k
aijk,其中
k
k
k代表第几个Filter,
i
i
i代表第行,
j
j
j代表第几列。
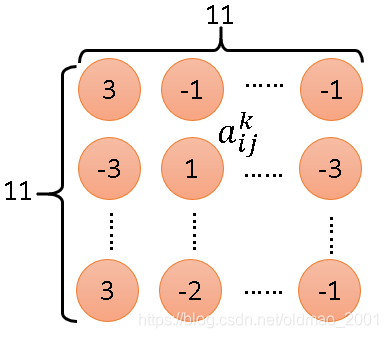
然后定义一个Degree of the activation of the k-th filter,其含义就是第k个FIlter有多被激活、启动(activate);或者说输入的数据与第k个Filter有多相近(match),公式如下:
a
k
=
∑
i
=
1
11
∑
j
=
1
11
a
i
j
k
a^k=\sum_{i=1}^{11}\sum_{j=1}^{11}a_{ij}^k
ak=i=1∑11j=1∑11aijk
假设现在有一个输入,对应上上个图中的input,记为
x
x
x,则现在要找到一个
x
∗
x^*
x∗,使得第
k
k
k个Filter被激活的程度最大,即:
x
∗
=
a
r
g
m
a
x
x
a
i
j
k
x^*=arg\underset{x}{max}\quad a_{ij}^k
x∗=argxmaxaijk,由于是求最大所以可以用gradient ascent方法。
重点思路之前做机器学习或者DNN,CNN的时候,输入是固定的,然后通过gradient decent找到参数的值,现在反过来,参数是固定的,要找到合适的输入值,用的是gradient ascent。
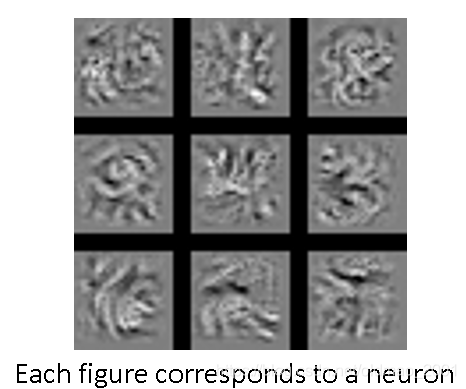
上面的操作找到了x,从里面拿出12个(总共有50个)来感受一下:

这些输入的image可以让Filter的激活程度最大,实际上也就是第二个操作中的convolution要找(提取)的特征!例如第三排第一张图片,代表这个Filter找的就是竖条纹,意味着如果原输入图片
x
x
x中有竖条纹,那么这个FIlter就会被激活,通过这个Filter的输出会比较大。
总之每个Filter是检测某种pattern,这里是不同角度的线条。
Flatten+Fully Connected NN部分
同样先上构架图:
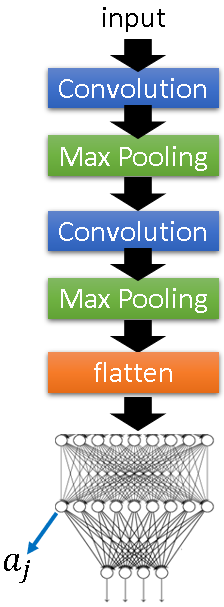
和刚才一样,给定神经元
a
j
a_j
aj,去找到输入
x
∗
x^*
x∗,使得
a
j
a_j
aj的输出最大,也就是最能被激活。
x
∗
=
a
r
g
m
a
x
x
a
j
x^*=arg\underset{x}{max}\quad a^j
x∗=argxmaxaj
同样可以找到相应的输入图像:
注意的是,这里的每一个神经元对应的输入不再是图片的某一个小区域,而是整张图片。
输出部分
先上图:

如果是做数字识别,这里的output应该是10个,
y
i
y^i
yi分别对应数字0-9,然后用刚才的思路去反推输入图像,是不是可以得到相应数字(是不是电脑自动画画用的这个算法?弹幕里面说如果是普通DNN会出现数字,不知道是否真的,欢迎评论。。。),其实不是,结果如下:

这些雪花图片,老师还特意做了实验,把它们作为输入放入CNN中,得到结果就是对应的数字!说明程序是没有问题的。机器学习学到的东西和人类是不一样的。
如何稍微还原一下这些雪花?
上图中的白色部分代表的是图片中有墨迹的部分,对于一个数字而言,墨迹不可能涂满整个图片,对于下面的式子
x
∗
=
a
r
g
m
a
x
x
y
i
x^*=arg\underset{x}{max}\space y^i
x∗=argxmax yi
做一些限制:
x
∗
=
a
r
g
m
a
x
x
(
y
i
−
∑
i
,
j
∣
x
i
j
∣
)
x^*=arg\underset{x}{max}\space\left (y^i-\sum_{i,j}\left|x_{ij}\right|\right)
x∗=argxmax (yi−i,j∑∣xij∣)
这里每个输入的图像大小是28*28,所以
i
i
i和
j
j
j的值都是1-28,计算
∑
i
,
j
∣
x
i
j
∣
\sum_{i,j}\left|x_{ij}\right|
∑i,j∣xij∣实际上是计算L1弄。整个公式的含义是找到的输入图像
x
x
x要满足两个条件:
1、使得输出
y
i
y^i
yi最大;
2、
x
x
x的L1弄最小,就是没有墨迹的地方越多越好。
加上这个条件后,结果如下:

比较明显的就是6和1,当然老师提示如果加上更加复杂的限制,例如:相邻的pixel应该是同一种颜色,可以得到更好的结果。
小结&Deep Dream
经过上面的讲解,实际上就是给定参数反推输入的这个思路,可以使得电脑输出图像,就是作画:
Deep Dream网站要注册,就没有试。。。

老师真人爆照。。。帅。。。
如果把照片丢到CNN训练后,把里面某一隐藏层或fully connected NN的某一层拿出来,然后把大数字变大,小的数字变小(怎么看得很眼熟,好像Softmax),就是让CNN把它看到东西夸大化:

就变成下面的样子:

Deep dream进阶:Deep style输入:

输出:

思路:
参考文献A Neural Algorithm of Artistic Style15年的文章。
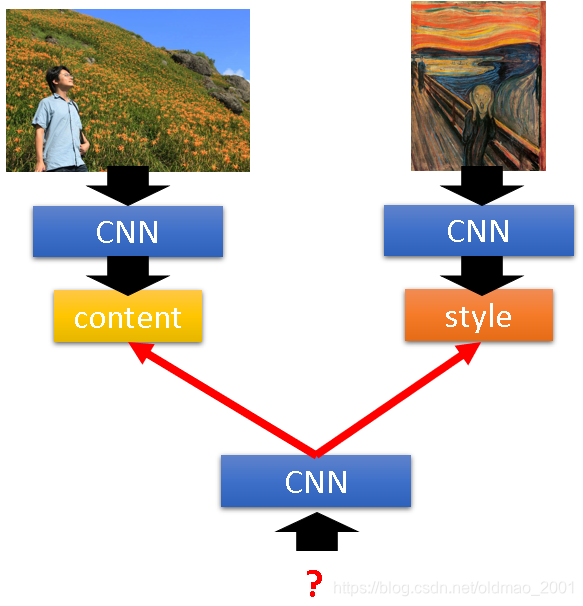
左上角通过CNN训练得到Filter的output,这个FIlter的output就是图像的content,
右上角通过CNN训练得到Filter的output,这个时候考虑的不算output的值,而是在意Filter与Filter之间的输出的correlation,这个correlation就是style。
接下来用一个CNN找一个照片,使得该照片同时maximize左右两边的content和style
更多CNN应用
AlphaGo
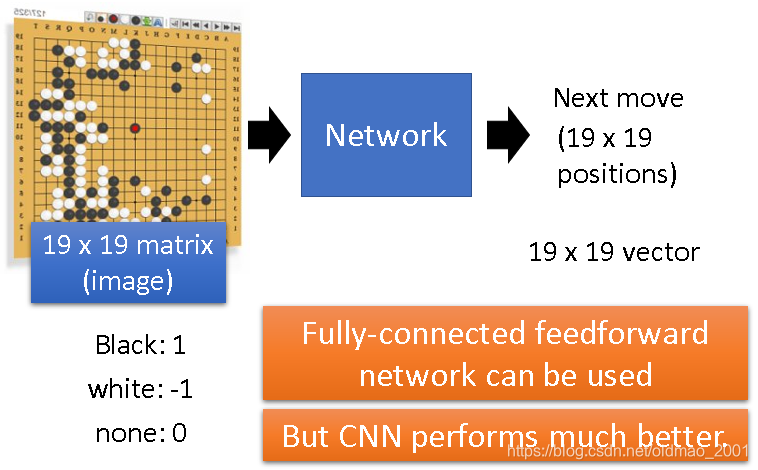
输入是带有棋子的棋盘,输出是下一步怎么走。
warning of 二次元:
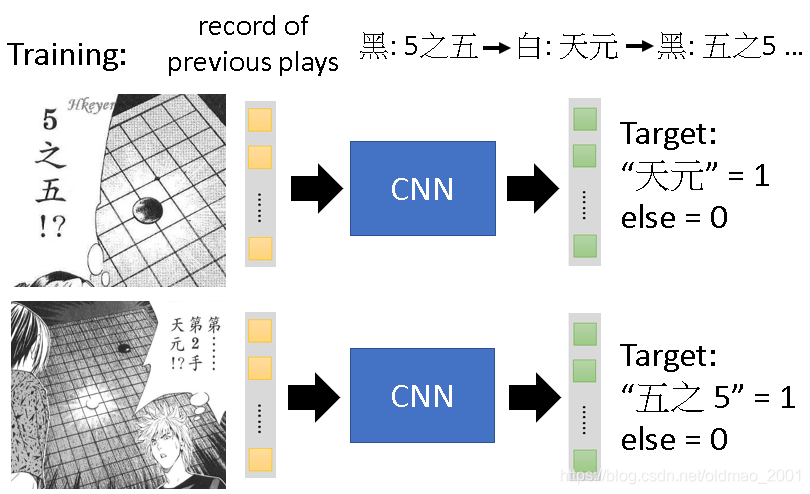
为什么CNN可以用来玩围棋
对应的原因是从上篇中可以找到,上篇中讲了3个原因,围棋里面有些东西和图像识别原理一样。
第一个原因:pattern往往会小于整张图片,因此只用看部分图片(棋盘)。
第二个原因:相同pattern可以出现在棋盘的任意地方。
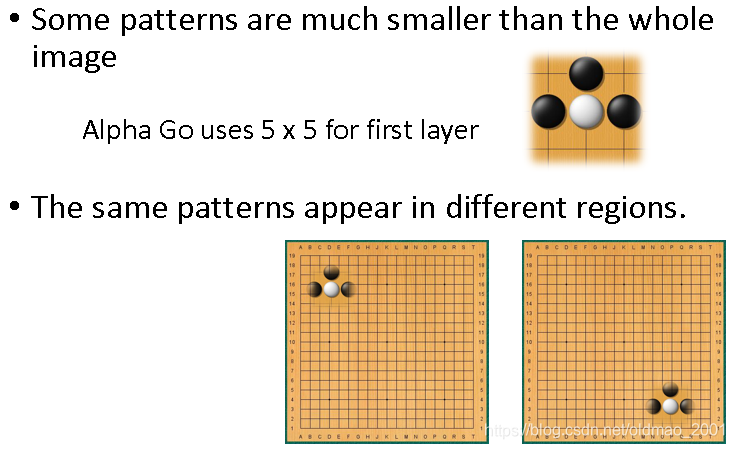
第三个原因:图像处理的时候sbusampling不会改变目标物体,也就是缩放一下,鸟还是鸟。围棋上貌似不能这样玩(缩放了棋盘大小变了。。。)。这个原因对应CNN的构架中的Max Pooling操作。所以在AlphaGo中没有Max Pooling操作,老师给出了AlphaGo的文章,在附录中找到了证据。(老师真的是论文控。。。)
19×19是棋盘的大小,48不仅包含黑子白子的信息,还包含了其他的围棋方面的domain knowledge。
第一个隐藏层做了padding,扩展为23×23,第一次卷积是经过5×5的filter,输入变成了21×21大小,
然后接下来的第2到12次卷积都先padding到21×21大小,再用3×3的filter,stride为1的步长进行卷积。激活函数都是ReLU。整个操作没有提到Max Pooling。

语言识别
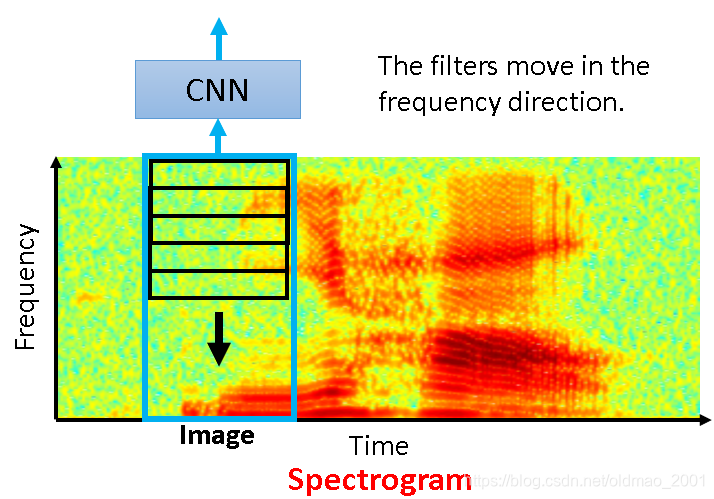
老师介绍自己在MIT访学时,实验室有专门训练人看Spectrogram识字,上图实际上是“你好”,如何构建CNN来识别语音?把Spectrogram看成是图片,Filter的宽和上图中的蓝色框一样,识别的方向是Frequency黑色箭头方向。为啥是这个方向?因为不同人讲同一句话,可能频率不一样,但是pattern是一样的,所以在Frequency上进行识别才有效。
文字处理
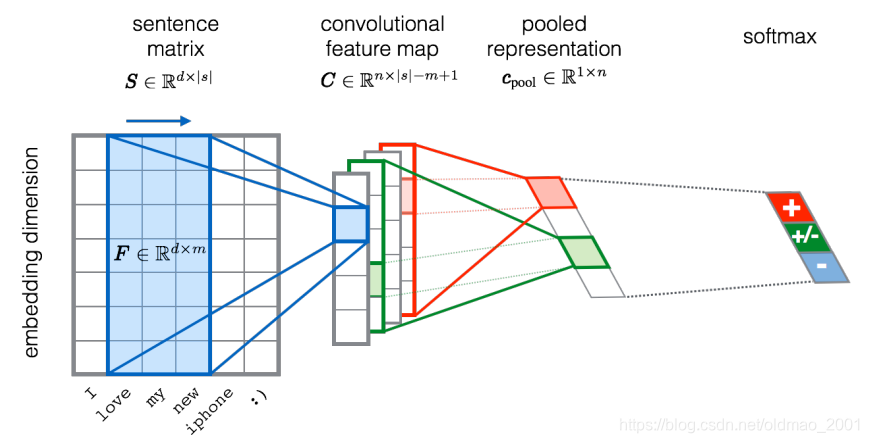
图片来源
输入一个word sequence,判断其情感类别。
每个word都用一个vector来表示,把一个句子的单词排在一起就变成matrix,就是一个image,然后就可以套CNN。Filter沿着句子的顺序来移动。与语音识别不一样,Filter的移动方向是沿着时间的方向的(蓝色箭头)!分析word的方向是没有意义的。
总结
在设计CNN构架的时候要结合应用。例如alphaGo中因为不能改变棋盘形状去掉了max pooling操作。


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











