




 本文介绍了GNN(图神经网络)与Transformer在处理图结构任务中的结合,通过实例展示了如何在图中应用单头或多头Attention,并结合消息传递进行编码和解码。讲解了计算注意力分数、softmax归一化和最终输出的过程,并涉及了实际代码实现。
本文介绍了GNN(图神经网络)与Transformer在处理图结构任务中的结合,通过实例展示了如何在图中应用单头或多头Attention,并结合消息传递进行编码和解码。讲解了计算注意力分数、softmax归一化和最终输出的过程,并涉及了实际代码实现。
本文内容整理自深度之眼《GNN核心能力培养计划》
公式输入请参考: 在线Latex公式
接直播理论部分内容,这两节讲代码实现
理论回顾
https://docs.dgl.ai/tutorials/models/4_old_wines/7_transformer.html
下面是单头Attention的描述:
注意力计算先要算qkv和score。这里的i,j是两个单词,x是单词的特征:
q
j
=
W
q
⋅
x
j
k
i
=
W
k
⋅
x
i
v
i
=
W
v
⋅
x
i
s
c
o
r
e
=
q
j
T
k
i
q_j=W_q\cdot x_j\\ k_i =W_k\cdot x_i\\ v_i = W_v\cdot x_i\\ score = q_j^Tk_i
qj=Wq⋅xjki=Wk⋅xivi=Wv⋅xiscore=qjTki
这里的score实际上计算的是query和key之间的相似度,相似度越高注意力就越大,当然还有别的方式来计算相似度,这里用的最简单的点乘。
然后将score进行softmax:
w
j
i
=
exp
{
s
c
o
r
e
j
i
}
∑
(
k
,
i
)
∈
E
exp
{
s
c
o
r
e
k
i
}
w_{ji}=\cfrac{\exp\{score_{ji}\}}{\sum_{(k,i)\in E}\exp\{score_{ki}\}}
wji=∑(k,i)∈Eexp{scoreki}exp{scoreji}
然后计算单词i的加权求和权重:
w
v
i
=
∑
(
k
,
i
)
∈
E
w
k
i
v
k
wv_i = \sum_{(k,i)\in E}w_{ki}v_k
wvi=(k,i)∈E∑wkivk
然后做最后的输出:
o
=
W
o
⋅
w
v
o=W_o\cdot wv
o=Wo⋅wv
推广到多头Attention:
o
=
W
o
⋅
c
o
n
c
t
(
[
w
v
(
0
)
,
w
v
(
2
)
,
⋯
,
w
v
(
h
)
]
)
o=W_o\cdot conct([wv^{(0)},wv^{(2)},\cdots,wv^{(h)}])
o=Wo⋅conct([wv(0),wv(2),⋯,wv(h)])
对应的代码:
class MultiHeadAttention(nn.Module):
"Multi-Head Attention"
def __init__(self, h, dim_model):
"h: number of heads; dim_model: hidden dimension"
super(MultiHeadAttention, self).__init__()
self.d_k = dim_model // h
self.h = h
# W_q, W_k, W_v, W_o
self.linears = clones(nn.Linear(dim_model, dim_model), 4)
def get(self, x, fields='qkv'):
"Return a dict of queries / keys / values."
batch_size = x.shape[0]
ret = {}
if 'q' in fields:
ret['q'] = self.linears[0](x).view(batch_size, self.h, self.d_k)
if 'k' in fields:
ret['k'] = self.linears[1](x).view(batch_size, self.h, self.d_k)
if 'v' in fields:
ret['v'] = self.linears[2](x).view(batch_size, self.h, self.d_k)
return ret
def get_o(self, x):
"get output of the multi-head attention"
batch_size = x.shape[0]
return self.linears[3](x.view(batch_size, -1))
GNN+Transformer
在图结构中,Transformer的注意力要和消息传递相结合。如果用图来理解注意力机制是怎么弄呢?下面看例子
图结构
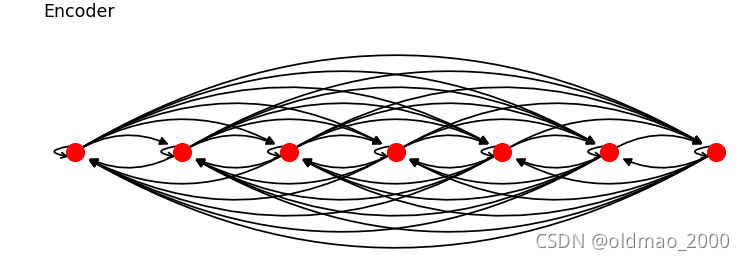
把句子中的每一个单词看做一个节点,那么原来的句子可以由三个子图构成。
第一个子图是Source language graph. 可以看到是一个完全图,每个节点
s
i
s_i
si与其他节点
s
j
s_j
sj都有边连接,这里还包含有
s
i
s_i
si的自连接。
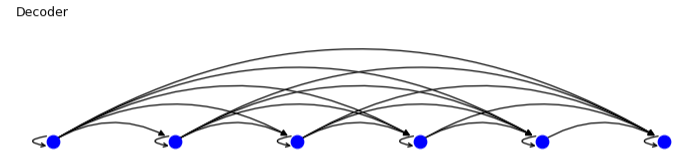
第二个图是Target language graph.可以看到这个图是上面图的一半,因为节点
t
i
t_i
ti只连接
t
j
,
i
<
j
t_j,i<j
tj,i<j,这里的意思是在输出的时候,当前节点的输入只和前面的单词节点有关,后面的单词节点还没生成,后面的单词输出与当前单词输出无关。
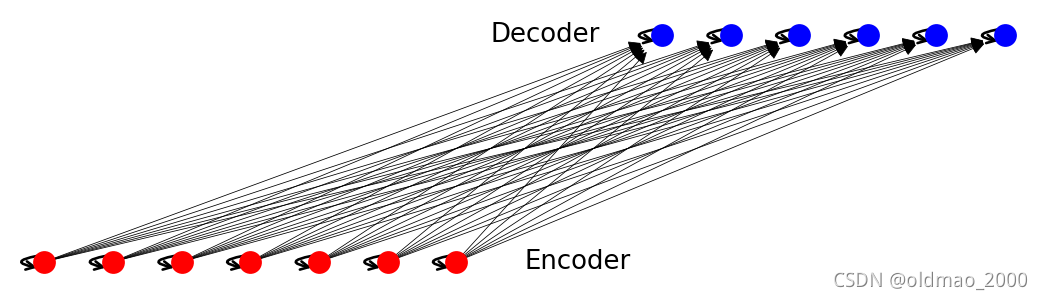
第三个图是:Cross-language graph.是一个二部图,就是每个输入节点
s
i
s_i
si都和每个输出节点
t
j
t_j
tj有一个对应关系
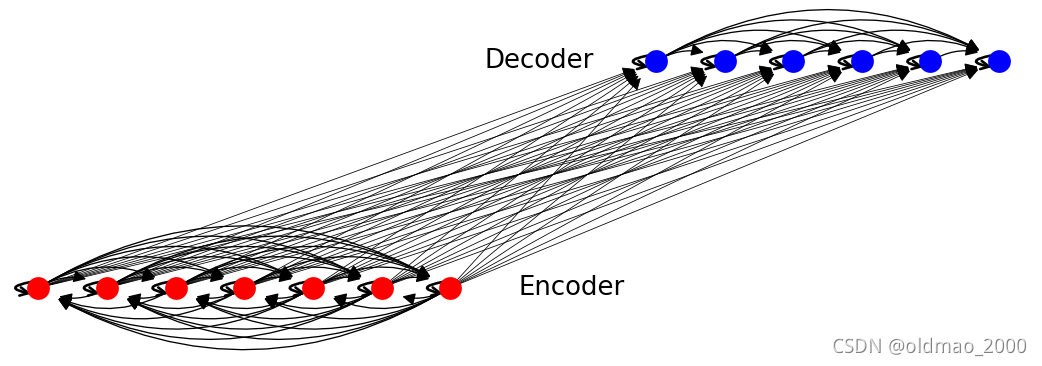
可以看到这里给出的三个子图实际上对应到Transformer的输入输出,Encoder和Decoder。三个子图合起来就是:
消息传递
有了图结构,就可以进行消息传递了。
假设节点
i
i
i对应的qkv都已经计算完成。那么对于每个节点
i
i
i的注意力消息传递都可以分为两个步骤:
1、计算节点
i
i
i和其他所有邻居节点之间的
s
c
o
r
e
i
j
=
q
i
⋅
k
j
score_{ij}=q_i\cdot k_j
scoreij=qi⋅kj
def message_func(edges):
return {'score': ((edges.src['k'] * edges.dst['q'])
.sum(-1, keepdim=True)),
'v': edges.src['v']}
如果搞不清从谁到谁,可以这样想,消息汇聚就是从邻居节点汇聚消息到当前节点,所以邻居节点是src,当前节点是dst。
2、消息汇聚:计算与
i
i
i相邻的所有节点
j
j
j的
v
j
v_j
vj的加权和,权重就是上一步的score。
import torch as th
import torch.nn.functional as F
def reduce_func(nodes, d_k=64):
v = nodes.mailbox['v']#邻居的embedding
att = F.softmax(nodes.mailbox['score'] / th.sqrt(d_k), 1)
return {'dx': (att * v).sum(1)}
原生Transformer实操部分下节讲。


















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











