




 本文深入探讨了结构化学习的概念,介绍了其在语音识别、翻译、语法分析、目标检测、摘要生成及信息检索等领域的应用,并提出了一个统一的框架来理解和解决结构化学习问题。
本文深入探讨了结构化学习的概念,介绍了其在语音识别、翻译、语法分析、目标检测、摘要生成及信息检索等领域的应用,并提出了一个统一的框架来理解和解决结构化学习问题。
文章目录
公式输入请参考: 在线Latex公式
PPT
Structured Learning
我们学过的DL,SVM等,输入和输出都是向量,但是,有的时候,我们想要输入的不是一个向量,按照OO的思想来讲,我想要输入一个对象,如:输入树形结构,输出也是一个树形结构。
f
:
X
→
Y
f:X\rightarrow Y
f:X→Y
这里的X和Y不再局限于向量,而是对象。
Xis the space of one kind of obiect. Y is the space of another kind of object.
· We need a more powerful function
f
f
f
· Input and output are both objects with structures
· Object: sequence, list, tree, bounaing box……
Example Application
· Speech recognition
·X: Speech signal(sequence)>Y: text(sequence)
· Translation
·X: Mandarin sentence(sequence)->Y: English sentence(sequence)
· Syntactic Paring
·X: sentence>Y: parsing tree(tree structure)
· Object Detection
·X: Image->Y: bounding box
· Summarization
·X: long document.>Y: summary(short paragraph)
· Retrieval
·X: keyword ->y: search result(a list of webpage)
看上去ST貌似很麻烦,实际上ST有一个统一的框架:
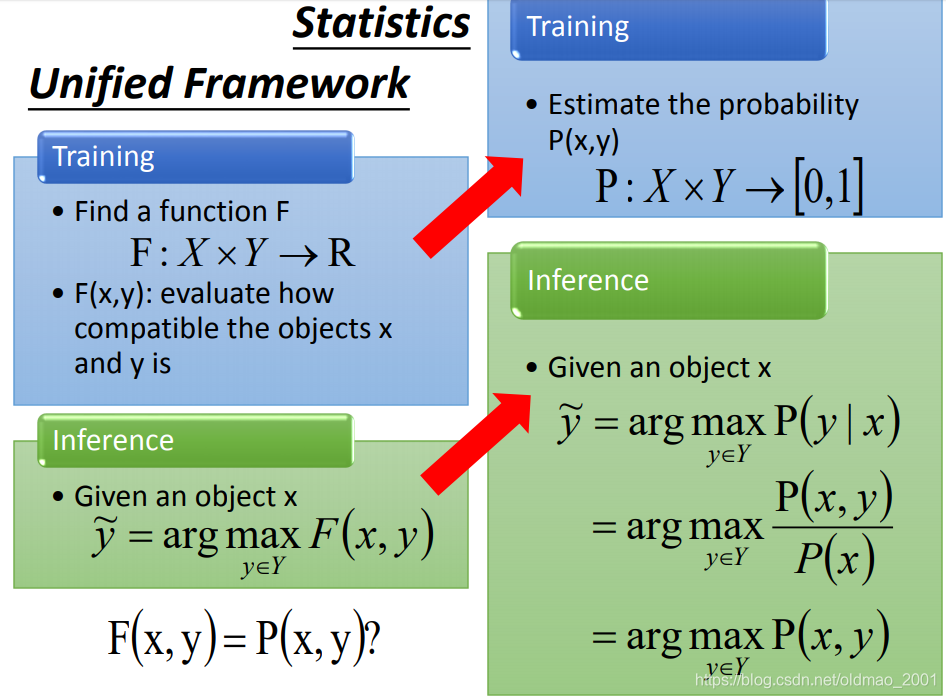
Unified Framework
Training
找到一个函数
F
F
F,这里和之前不一样,之前都是找
f
f
f
函数
F
F
F的输入是
X
X
X和
Y
Y
Y,输出是一个实数
R
R
R。
F
(
x
,
y
)
F(x,y)
F(x,y)是衡量输入
X
X
X和
Y
Y
Y之间有多匹配,匹配度(compatible)越高,输出值越大
Inference(Testing)
给定一个对象X,目标是:
y
~
=
a
r
g
m
a
x
y
∈
Y
F
(
x
,
y
)
\tilde y=arg\underset{y\in Y}{max}F(x,y)
y~=argy∈YmaxF(x,y)
上节中的函数
f
f
f,是输入
X
X
X,输出
Y
Y
Y:
f
:
X
→
Y
f:X\rightarrow Y
f:X→Y,结合上面的式子:
f
(
x
)
=
y
~
=
a
r
g
m
a
x
y
∈
Y
F
(
x
,
y
)
f(x)=\tilde y=arg\underset{y\in Y}{max}F(x,y)
f(x)=y~=argy∈YmaxF(x,y)
不知道为什么?没关系,看个例子:
Unified Framework-Object Detection
·Task description
·Using a bounding box to highlight the position of a certain object in an image.
输入
X
X
X:图像,输出
Y
Y
Y:边界框
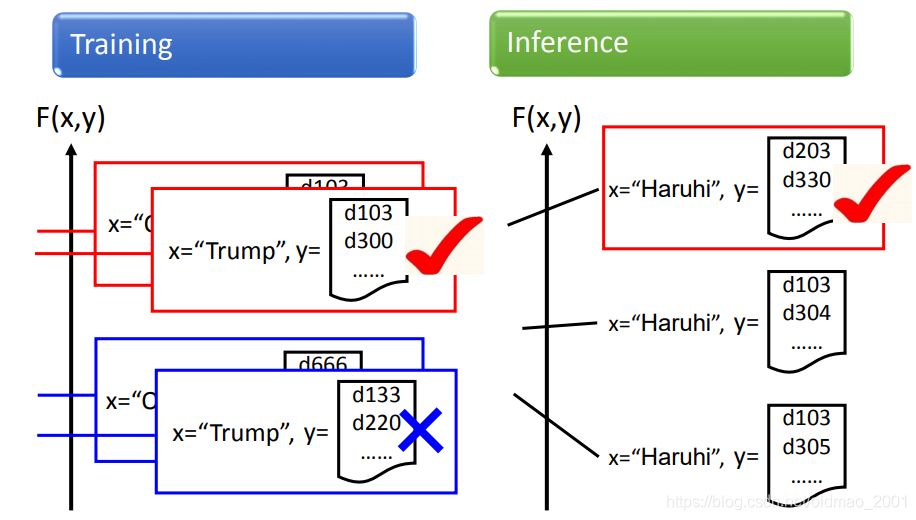
例如:

貌似叫凉宫春日?

按框架的讲法:
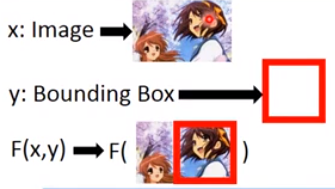
F
(
x
,
y
)
F(x,y)
F(x,y)是衡量框和人物的匹配度。
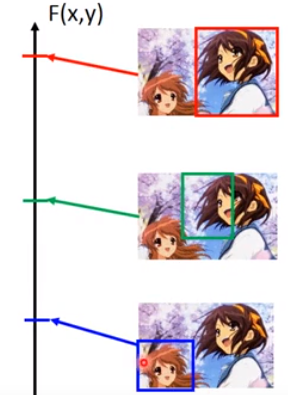
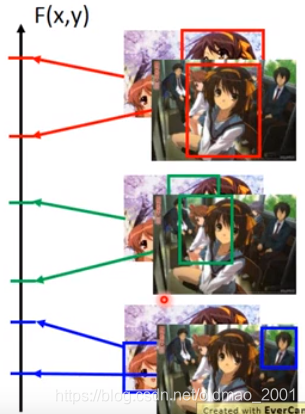
testing的时候就是找一张含有图片。

然后穷举所有框框有可能出现的地方。然后看哪个框框的得分最高
Unified Framework-Summarization
·Task description
·Given a long document
·Select a set of sentences from the document,and cascade the sentences to form a short paragraph.
输入是一个长文档
X
=
{
s
1
,
s
2
,
s
3
,
.
.
.
s
i
,
.
.
.
}
X=\{s_1,s_2,s_3,...s_i,...\}
X={s1,s2,s3,...si,...},其中
s
i
s_i
si表示文档中第
i
i
i个句子。
输出是一个总结
Y
=
{
s
1
,
s
3
,
s
5
3
}
Y=\{s_1,s_3,s_53\}
Y={s1,s3,s53}
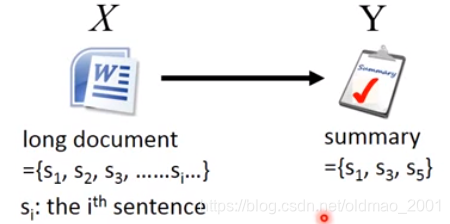
训练:当文档与总结配对的时候
F
(
x
,
y
)
F(x,y)
F(x,y)的值很大
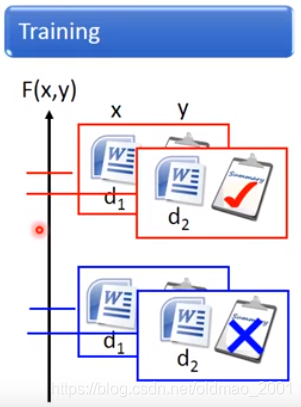
testing的时候,穷举所有的总结,看哪个总结配上文档
F
(
x
,
y
)
F(x,y)
F(x,y)值最大。
Unified Framework-Retrieval
·Task description
·User input a keyword
Q
Q
Q
·System returns a
l
i
s
t
list
list of web pages
输入是查询词,输出是查询的结果
Unified Framework的统计学角度理解
训练:
估计两个对象
X
X
X和
Y
Y
Y的联合分布概率,记为
P
(
x
,
y
)
P(x,y)
P(x,y):
P
:
X
×
Y
→
[
0
,
1
]
P : X \times Y\rightarrow[0,1]
P:X×Y→[0,1]
testing就是:
给定x的条件下,求y出现的最大概率
y
~
=
a
r
g
m
a
x
y
∈
Y
P
(
y
∣
x
)
=
a
r
g
m
a
x
y
∈
Y
P
(
x
,
y
)
P
(
x
)
\tilde y=arg\underset{y\in Y}{max}P(y|x)=arg\underset{y\in Y}{max}\cfrac{P(x,y)}{P(x)}
y~=argy∈YmaxP(y∣x)=argy∈YmaxP(x)P(x,y)
由于分母和y求最大值没有关系,所以分母可以去掉
y
~
=
a
r
g
m
a
x
y
∈
Y
P
(
x
,
y
)
\tilde y=arg\underset{y\in Y}{max}P(x,y)
y~=argy∈YmaxP(x,y)
这样就和前面讲的对应起来了:
最下面的问号意思是:之前的
F
(
x
,
y
)
F(x,y)
F(x,y)是求xy的匹配度,
P
(
x
,
y
)
P(x,y)
P(x,y)是求xy的联合概率,这里两个事情是不是一样??理论上是一样的
但是统计学上有如下缺点:
·Probability cannot explain everything
·0-1constraint is not necessary. 很多对象是高维的,加这个限制就要做normalization,花费太大精力,没有必要。
好处就是:容易理解。
Energy-based Model:这个是立坤大佬提出的模型,实际上也是ST。
http://www.cs.nyu.edu/~yann/research/ebm/
Unified Framework的三个问题
问题一
很难想象
F
(
x
,
y
)
F(x,y)
F(x,y)是什么样子
·Evaluation:What does
F
(
x
,
y
)
F(x,y)
F(x,y) look like?
·How
F
(
x
,
y
)
F(x,y)
F(x,y) compute the "compatibility"of objects
x
x
x and
y
y
y

问题二
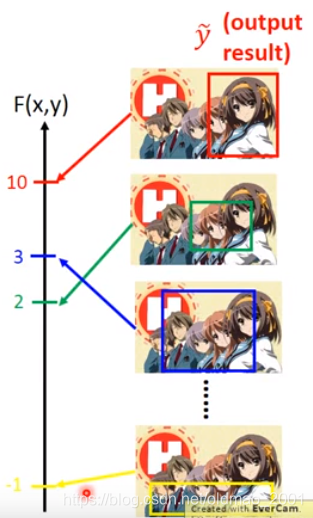
在testing阶段如何求解最大值问题。
·Inference:How to solve the “arg max” problem
y
~
=
a
r
g
m
a
x
y
∈
Y
F
(
x
,
y
)
\tilde y=arg\underset{y\in Y}{max}F(x,y)
y~=argy∈YmaxF(x,y)
The space Y can be extremely large!
Object Detection:Y=All possible bounding box(maybe tractable)这个就有无穷多个组合。。。
Summarization:Y=All combination of sentence set in a document …
Retrieval: Y=All possible webpage ranking ….
问题三
Training: Given training data, how to find
F
(
x
,
y
)
F(x,y)
F(x,y)
我们有的训练数据:
{
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
.
.
.
,
(
x
r
,
y
^
r
)
,
.
.
.
}
\{(x^1,\widehat y^1),(x^2,\widehat y^2),...,(x^r,\widehat y^r),...\}
{(x1,y
1),(x2,y
2),...,(xr,y
r),...}
我们要训练
F
(
x
,
y
)
F(x,y)
F(x,y),使得正确匹配的
(
x
,
y
^
)
(x,\widehat y)
(x,y
)的得分要高于其他(x,y),这个训练过程是非常难以完成。
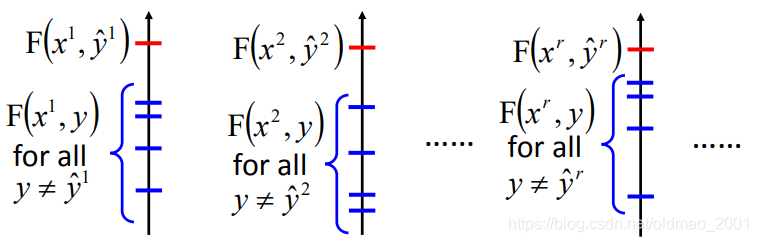
小结

要下课了,后面提示这三个问题要用GAN解决。


















 4240
4240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











