




 本文介绍了一种爬取特定电影网站上2022年热门电影的方法,通过定位目标页面、提取子页面链接及下载地址,最终获取电影资源。
本文介绍了一种爬取特定电影网站上2022年热门电影的方法,通过定位目标页面、提取子页面链接及下载地址,最终获取电影资源。
文章目录
一 需求
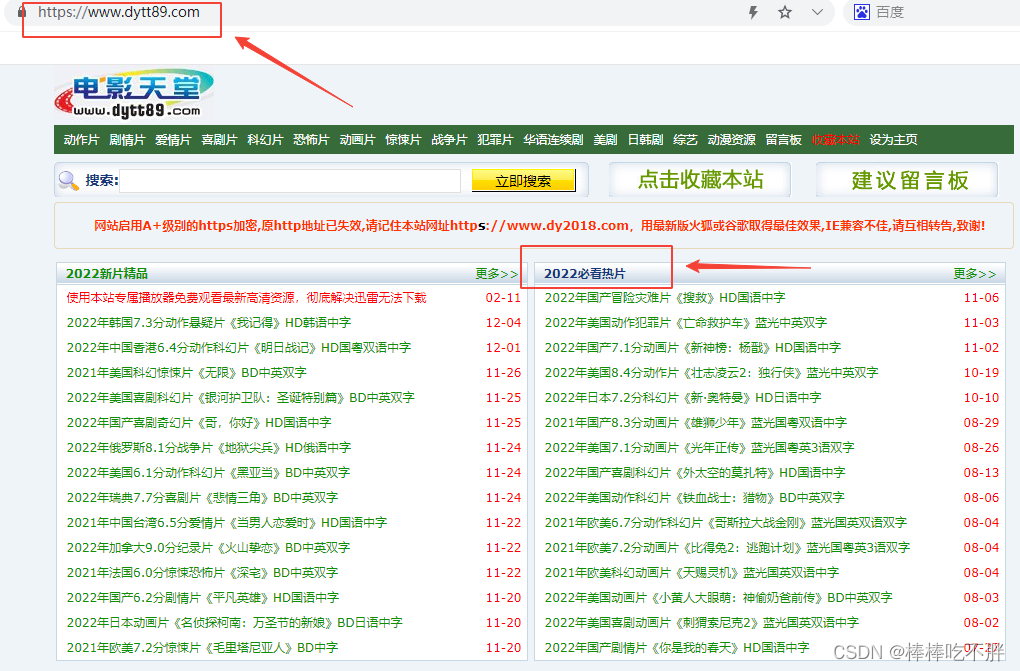
在某个电影网站,爬取2022必看热片中具体的电影资源,并得到其下载地址
二 总体思路
1)从网址定位到2022必看热片
2)从2022必看热片定位到子页面的链接地址
3)请求子页面的链接地址,拿到我们想要的下载地址
三 分析步骤
1)从网址定位到2022必看热片
首先是获取网页的资源信息。
获取URL网页。
再利用requets获取网页内容。在这里由于该网站设立了相关防火墙等安全策略,于是我们要添加相关参数,取消安全验证。
最后打印相关的页面信息资源。
上述环节可以参考笔者之前的文章。
python-(6-3-1)爬虫—requests入门(基于get请求)
这时我们会发现报错信息。

大概意思是,获取该网站数据时,对数据流编码和解码的方式发生了错误。于是我们需要设置本地的字符集编码方式。
这时打开网页的源代码,在最上方我们可以找到爬取的网页的编码方式:charset=gb2312

因此,我们需要在pycharm中添加几行信息。(被框住的内容)
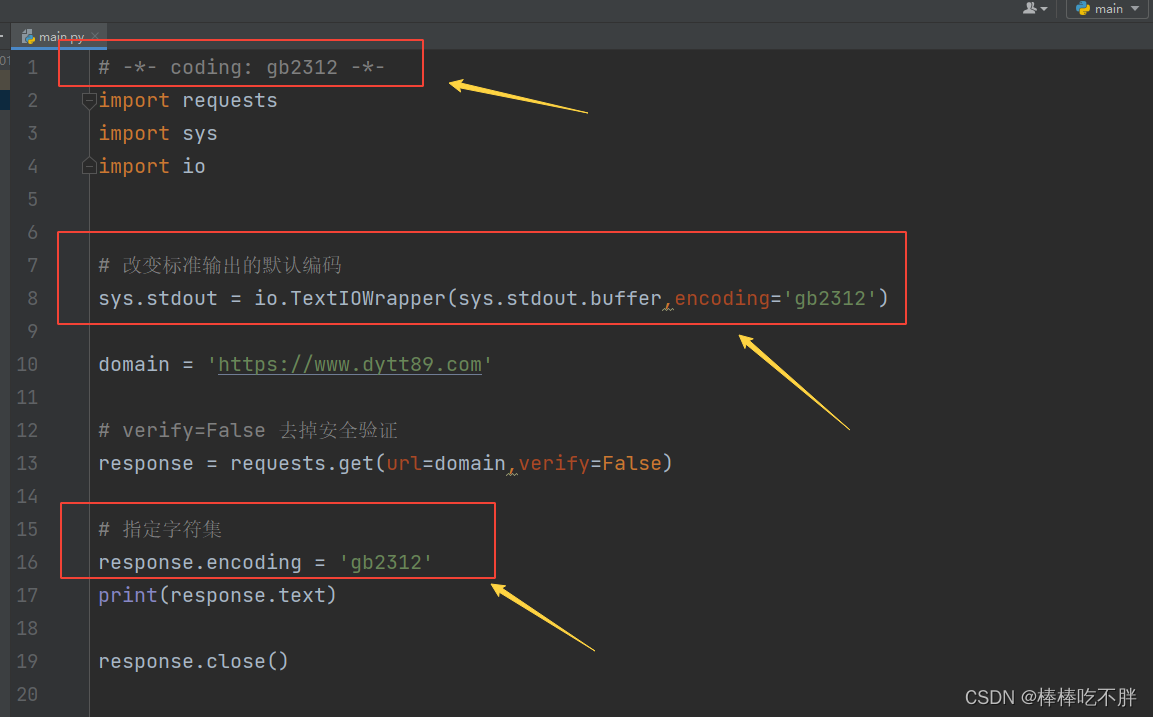
这样我们就能解决字符集编码以及最后的乱码问题。
2)从2022必看热片定位到子页面的链接地址
接着,打开网页源代码。
按住ctrl+F,搜索2022必看热片,进行内容定位。
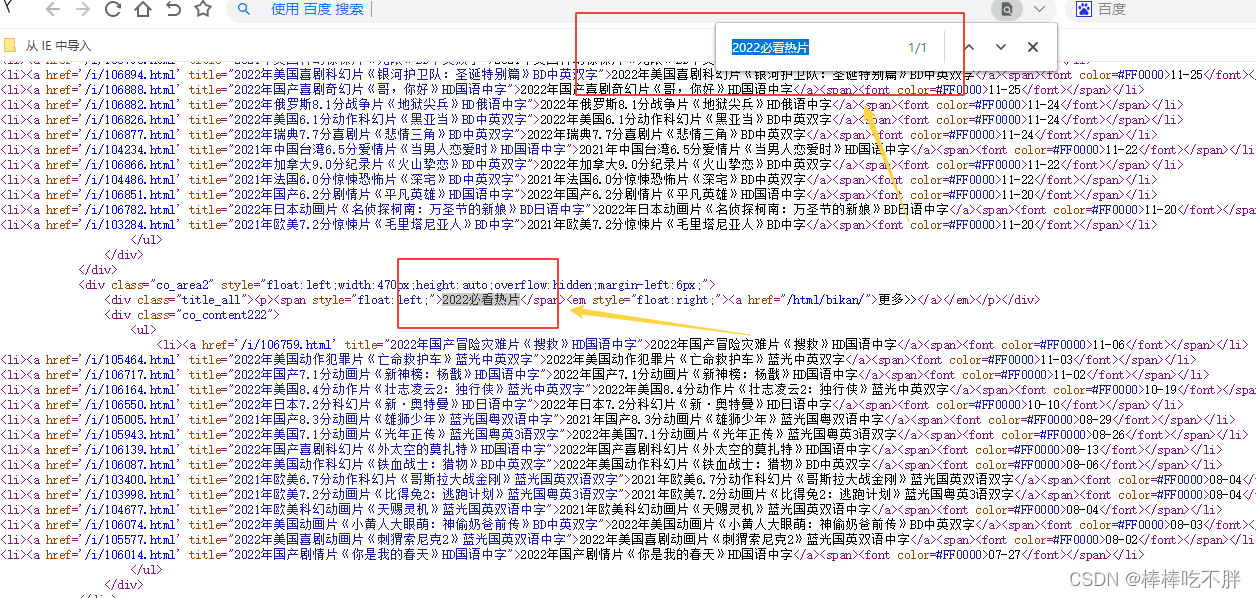
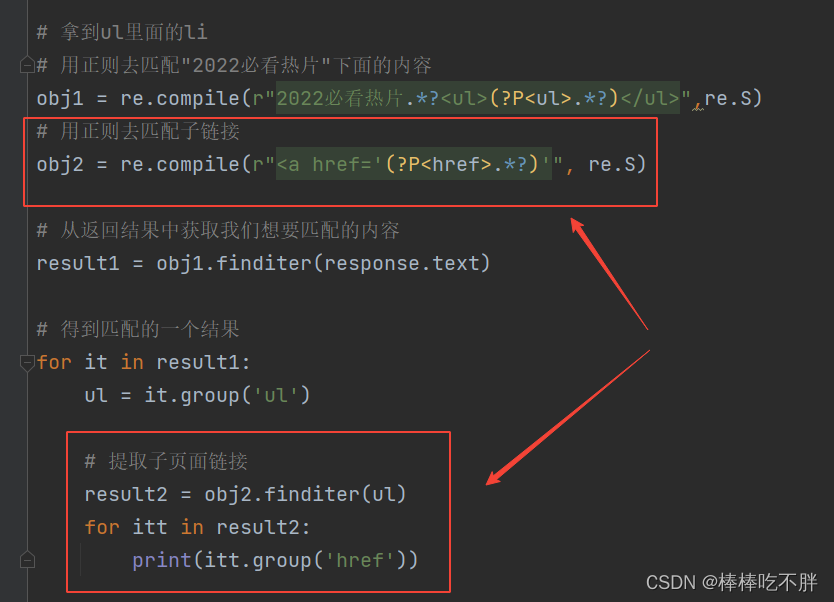
接下来利用正则表达匹配我们需要的内容。
如下图所示,我们从2022必看热片开始,一直到<ul>是不需要的,接着一直到</ul>中间的内容是需要我们提取的内容。

于是代码就很明朗了。
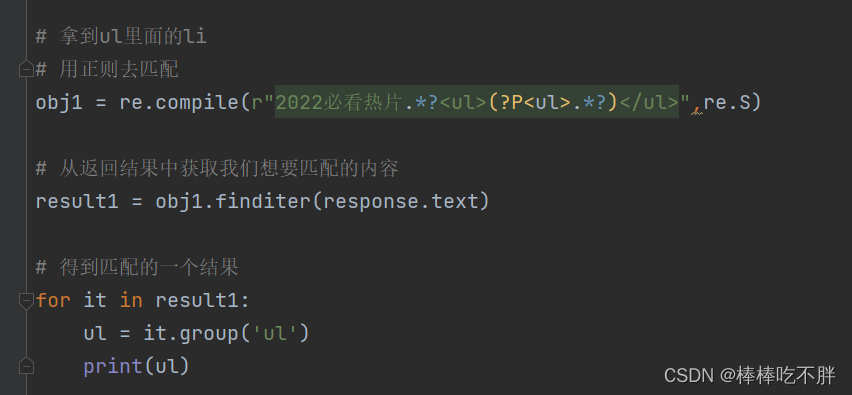
这里的re知识不作过多讲解,如果不太清楚,可以查看笔者写的文章。
python-(6-4-1)爬虫—利用re解析获得数据信息
接下来,我们要知道,每一个子页面,背后一定有一个 URL 地址,并且都不一样。
页面源代码中,每一个 a 标签,都代表一个超链接。

而每一个超链接,跳转的URL都是后面跟随的href中。

顺便一提,后面的title是鼠标放在超链接上面时,浮现的文字。
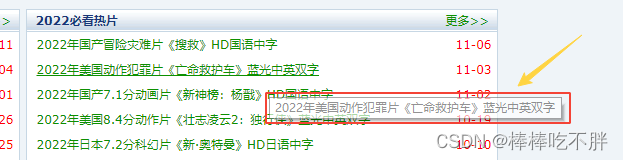
所以,我们需要的是herf后面的内容。
于是,我们就得到了每一个想要获取的电影的完整URL,即domain和itt拼接起来。
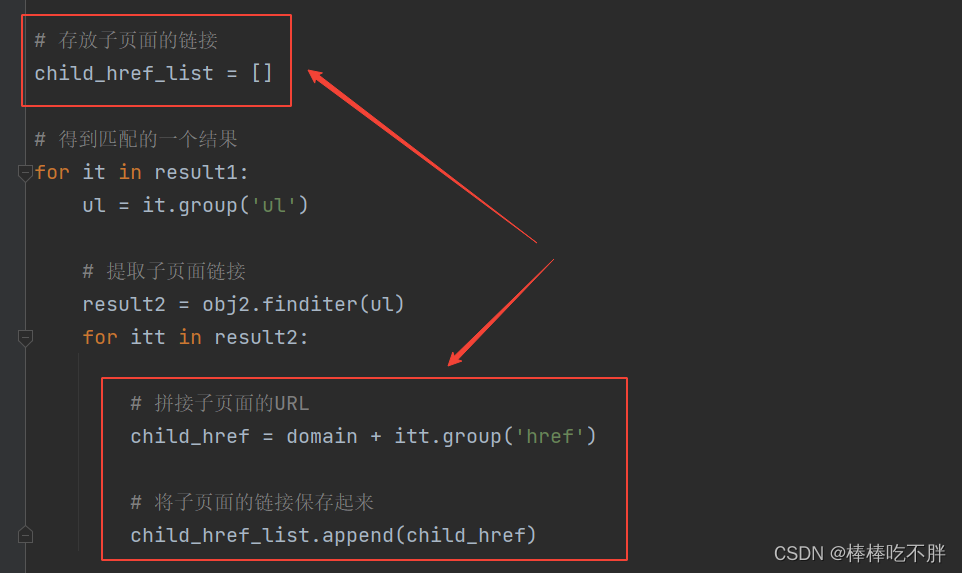
最后我们的代码如下:
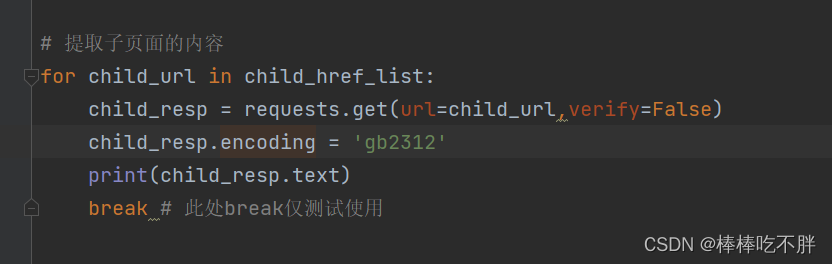
3)请求子页面的链接地址,拿到我们想要的下载地址
接下来就要获取子链接中的片名和下载链接,利用正则表达式。

在片名和下载地址之间,有一长串的内容,这么大的内容我们是不需要的。

最后再接收这些爬取到的数据,任务完成。
四 完整代码
# -*- coding: gb2312 -*-
import requests
import sys
import io
import re
# 改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb2312')
domain = 'https://www.dytt89.com'
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36"
}
# verify=False 去掉安全验证
response = requests.get(url=domain,verify=False)
# 指定字符集
response.encoding = 'gb2312'
# 此处是测试获取到的内容是否有乱码
#print(response.text)
# 拿到ul里面的li
# 用正则去匹配"2022必看热片"下面的内容
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>",re.S)
# 用正则去匹配子链接
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
# 用正则去匹配电影名和下载地址
obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />.*?<td '
r'style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">',re.S)
# 从返回结果中获取我们想要匹配的内容
result1 = obj1.finditer(response.text)
# 存放子页面的链接
child_href_list = []
# 得到匹配的一个结果
for it in result1:
ul = it.group('ul')
# 提取子页面链接
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面的URL
child_href = domain + itt.group('href')
# 将子页面的链接保存起来
child_href_list.append(child_href)
# 提取子页面的内容
for child_url in child_href_list:
child_resp = requests.get(url=child_url,verify=False)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
print(result3.group("movie"))
print(result3.group("download"))
# break # 测试使用时开启
# 关闭请求响应的连接
response.close()

















 4570
4570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









