







 本文介绍如何使用Prototype模式、DynamicMethod和Flyweight模式来提高系统的开发和运行效率。通过具体的例子展示了如何利用Prototype模式简化业务实体类的克隆过程,减少重复代码,同时通过DynamicMethod提高克隆效率。
本文介绍如何使用Prototype模式、DynamicMethod和Flyweight模式来提高系统的开发和运行效率。通过具体的例子展示了如何利用Prototype模式简化业务实体类的克隆过程,减少重复代码,同时通过DynamicMethod提高克隆效率。
DynamicMethod可以实现运行时的高效,Flyweight模式可以实现数据的共享,而Prototype模式通过实现对象的Clone,使我们的系统不必关心具体业务类的创建、构成和表示。三者结合,可以使我们系统的开发效率和运行效率都得到极大的提高。
上一篇文章《用DynamicMethod提升ORM系统转换业务数据的性能》中讲了DynamicMethod在转换业务数据方面的应用,本文继续探讨DynamicMethod在其他方面的应用情况,并试图将设计模式这个高深的东西平民化,走进我们的生活,为我们服务。
在实践中,我们经常需要对一个业务数据进行修改,然后把更新后的结果保存到数据库中。以修改该某个用户的Email地址为例说明实现这个功能一般的做法:
首先,假设保存用户信息的业务实体类User的定义如下:
public class User
{
private string _userid;
private string _username;
private string _pwd;
private string _email;
public string UserID
{
set { _userid = value; }
get { return _userid; }
}
public string UserName
{
set { _username = value; }
get { return _username; }
}
public string Pwd
{
set { _pwd = value; }
get { return _pwd; }
}
public string Email
{
set { _email = value; }
get { return _email; }
}
}
另外,假设我们有一个接口DBWR,他有一函数可以实现把业务数据更新到数据库中去,其原型如下:
public class DBWR
{
public static readonly DBWR Instance = new DBWR();
private DBWR() { }
public int UpdateObject(object OldObject, object NewObject);
}
其中,OldObject表示原来对象,NewObject表示更新后的对象,返回受到影响的行数。
现在,我们已经有了一个User的实例,我们叫他OldObject,UserID =’C00001’, UserName =’Yahong’, Pwd = ’xxx’,Email =’yahongq123@163.com’,现在需要把Email的值更改为’yahongq111@163.com’,那么我们可以这样实现该User的Email信息的更新:
User NewObject = new User();
NewObject.UserID = "C00001";
NewObject.UserName = "Yahong";
NewObject.Pwd = "xxx";
NewObject.Email = "yahongq111@163.com";
DBWR.Instance.UpdateObject(OldObject, NewObject);
很好,我们的任务已经完成。但是,如果我们更进一步想一想,一个MIS系统中业务实体类可能有成百上千,甚至上万个,而且对每个业务实体类的更新操作也有很多处,如果我们的每次更新操作,都需要这样New一次,然后对各个属性赋值,工作量可想而知。User类还好,只有4个属性,如果碰上一个有40个属性的类,即使我们只需要更新其中的一个属性,用这种方法,我们也需要给其余39个没有更新的属性赋值,如果我们需要在10个不同的地方更新这个类,如果这种具有40~50属性的类有几十上百个,那真是一场噩梦。
于是我们希望有一个Copy业务实体类功能,它提供一份基于某个给定对象的副本,那样的话,我们就不用对不需要更新的属性赋值了,我们把这个功能叫做Clone。
现在,User的定义如下:
public class User
{
//
//省略的定义
//
public User Clone()
{
User Result = new User();
Result.UserID = UserID;
Result.UserName = UserName;
Result.Pwd = Pwd;
Result.Email = Email;
return Result;
}
}
有了该功能后,上面更新Email的代码就变成了如下所示了:
User NewObject = OldObject.Clone();
NewObject.Email = "yahongq111@163.com";
DBWR.Instance.UpdateObject(OldObject, NewObject);
呵呵,代码一下子由6行变成了3行,而且,实体类的属性越多,我们节省的代码也就越多,而且还不容易出错。不过,用这种办法,系统中的上千实体类都必须提供Clone方法的实现,工作量仍然很大。那么,有没有可能提供对Clone的缺省实现呢?也就是说让这些实体类都继承自一个基类——BusinessObject,在BusinessObject中实现Clone方法,这样的话,就不用这么辛苦了,其定义如下:
public abstract class BusinessObject
{
public virtual BusinessObject Clone()
{
Type CloneType = GetType();
BusinessObject Result = (BusinessObject)Activator.CreateInstance();
PropertyInfo[] Properties = CloneType.GetProperties(BindingFlags.Public | BindingFlags.Instance);
foreach (PropertyInfo AProp in Properties)
{
if (!(AProp.CanWrite && AProp.CanRead))
continue;
object value = AProp.GetValue(this, null);
AProp.SetValue(Result, value, null);
}
return Result;
}
}
现在我们不禁为自己的聪明而感到高兴,现在更新Email的代码就变成了这样:
User NewObject = (User)OldObject.Clone();
NewObject.Email = "yahongq111@163.com";
DBWR.Instance.UpdateObject(OldObject, NewObject);
实体类和Client
的关系如下所示:
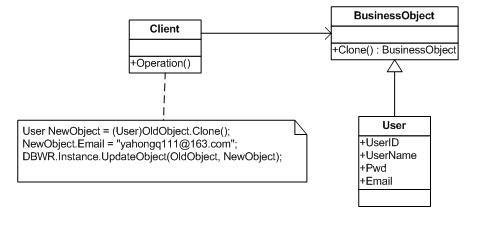
这是Prototype模式,不过没有像《设计模式》中文版中所说的那样可以“减少系统中类的数目”,但是却符合Prototype的意图——“用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象”。而且确实我们的BusinessObject创建、构成和表示可以和前端的Client独立起来,我们不用关心BusinessObject是如何被创建的,其内部表示应该怎样,我们只要Clone一下就有了他的一个新实例,而且各个属性的值和我们给定他的原型的各个属性的值相等。
看起来,似乎问题都解决了。可是,再看看我们的Clone方法,其核心是利用反射,而反射的性能是非常的低的,在大中型并发系统中,我们应该避免这样做,比较好的替代方法就是用DynamicMethod。下面是一个用DynamicMethod实现的全功能的Clone类:
public static class DataCloner
{
delegate object ObjectCloneMethod(object AObject);
public static T GenericClone<T>(T AObject)
{
if (AObject is ValueType||AObject==null)
return AObject;
return (T)GetColoneMethod(AObject.GetType())(AObject);
}
public static object Clone(object AObject)
{
if (AObject is ValueType || AObject == null)
return AObject;
return GetColoneMethod(AObject.GetType())(AObject);
}
static readonly Hashtable MethodList = new Hashtable();
static ObjectCloneMethod GetColoneMethod(Type CloneType)
{
lock (MethodList)
{
if (MethodList.ContainsKey(CloneType.GUID))
return (ObjectCloneMethod)MethodList[CloneType.GUID];
lock (MethodList)
{
Type[] methodArgs ={ typeof(object) };
DynamicMethod AMethod = new DynamicMethod("", typeof(object), methodArgs, CloneType);
ILGenerator il = AMethod.GetILGenerator();
ConstructorInfo createInfo = CloneType.GetConstructor(new Type[0]);
il.DeclareLocal(CloneType);
il.Emit(OpCodes.Newobj, createInfo);
il.Emit(OpCodes.Stloc_0);
PropertyInfo[] Properties = CloneType.GetProperties(BindingFlags.Public | BindingFlags.Instance);
foreach (PropertyInfo AProp in Properties)
{
if (!(AProp.CanWrite && AProp.CanRead))
continue;
il.Emit(OpCodes.Ldloc_0);
il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Callvirt, AProp.GetGetMethod());
il.Emit(OpCodes.Callvirt, AProp.GetSetMethod());
}
il.Emit(OpCodes.Ldloc_0);
il.Emit(OpCodes.Ret);
ObjectCloneMethod Result = null;
try
{
Result = (ObjectCloneMethod)AMethod.CreateDelegate(typeof(ObjectCloneMethod));
}
catch (Exception ex)
{
//
//记录日志
//
throw ex;
}
MethodList.Add(CloneType.GUID, Result);
return Result;
}
}
}
}
分析一下上面的代码,在Clone一个对象的时候,我们先从一个Hashtable中查找被Clone对象的所属类的DynamicMethod,如果找不到,则创建之,并放入Hashtable中以备后用。这样,Clone一个对象的时候,就只有第一次Clone的时候需要创建DynamicMethod
,以后就可以直接拿来用了。其类的简单示意图如下:
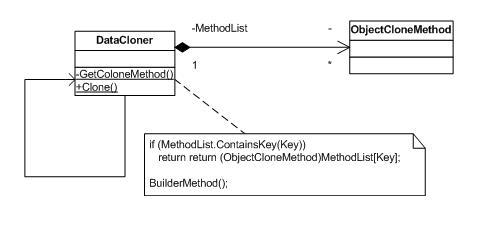
这是一个Flyweight模式的简化情况。在这里,DataCloner既是FlyweightFactory,他通过GetColoneMethod创建Flyweight——ObjectCloneMethod,又是Client,它的Clone方法必须使用与某个类相关的ObjectCloneMethod。
现在BusinessObject的定义可以这样:
public abstract class BusinessObject
{
public virtual BusinessObject Clone()
{
Type CloneType = GetType();
return (BusinessObject)DataCloner.Clone(this);
}
}
有了DataCloner,我们就可以让这些业务实体类不用继承自BusinessObject,这样似乎更加灵活。比如,继承自BusinessObject的情况,客户端是要这样:
User NewObject = (User)OldObject.Clone();
NewObject.Email = "yahongq111@163.com";
DBWR.Instance.UpdateObject(OldObject, NewObject);
而我们不用继承的时候是这样:
User NewObject = DataCloner.GenericClone<User>(OldObject);
NewObject.Email = "yahongq111@163.com";
DBWR.Instance.UpdateObject(OldObject, NewObject);
单从这些代码似乎看不出什么区别,但是,如果我们的业务实体类已经定义好了,并且被编译成了DLL,他们并没有从BusinessObject继承,那么我们就只有选择第二种方法了,当然,我们可以用Adapter模式重新定义,但是工作量有多大,就只有我们自己知道了。
有时候,面向过程比面向对象更加实用。
关于Flyweight模式,其实我们已经大量运用了。比如我们系统的各种元数据,在系统启动的时候加载,存储在系统的全局缓存中,在以后需要使用的时候,就直接从缓存中提取,而不用重新创建。个人认为,把需要经常访问的数据放在缓存中的做法,就是Flyweight的一个应用实例,只是没有书上说的那么典型罢了,但意图和书上是相同的:运用共享技术有效的支持大量细粒度的对象。
欢迎大家拍砖。

















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









