







目录
当表数据很大时,每次更新只有很小一部分数据,如果只保留一张全量表,则无法查询历史某个时间段表的全量记录。如果每天都保留一张全量表,则会增大存储压力。
这时候解决方案就是制作拉链表,拉链表就是在原表的基础上,新增两列记录每条数据记录的生命周期开始和结束时间。
一、什么是拉链表
拉链表是一种用于记录数据更新生命周期的表格结构,主要应用于数据仓库中。它通过记录每条数据的开始时间和结束时间,来跟踪数据的变化历史。在实际应用中,数仓拉链表可以帮助企业更好地进行数据分析和决策。
数仓拉链表是一种特殊的维度表,用于记录某个属性在不同时间段内的历史变化情况,在实际应用中有着广泛的应用场景,可以帮助企业更好地管理各种类型的信息。通常情况下,每个维度记录都会对应一个或多个拉链记录,每个拉链记录包含了该维度在某个时间段内的所有属性值。
例如,在一个销售数据仓库中,可以使用数仓拉链表来记录产品信息的历史变化情况。假设某个产品在2019年1月1日上市,并且在2020年1月1日进行了一次改版,则可以使用数仓拉链表来记录该产品在不同时间段内的版本信息。
二、拉链表的作用
拉链表的作用主要是在数据仓库中记录和管理数据的历史变化。通过拉链表,可以保留数据的历史版本,使得用户能够查询数据在任何给定时间点的状态。这种表的设计允许数据随时间的变化而变化,同时保留历史数据,以便进行趋势分析、数据回溯等操作。
具体来说,拉链表能够帮助实现以下几点:
1.记录数据的历史变化:通过保留数据的历史状态,可以追踪数据随时间的变化情况。
2.支持时间点查询:用户可以查询数据在特定时间点的状态,这对于分析数据的历史趋势非常有用。
3.管理数据的增删改:拉链表通过标记数据的新增、删除和更新状态,帮助管理数据的生命周期。
拉链表的实现通常涉及将来源表数据同步到中间表中,然后通过数据关联和标记,将新增、更新、删除的数据根据不同策略输入到拉链表中,从而有效地管理和跟踪数据的历史变化。
三、如何搭建数仓拉链表?
1.搭建思路
注:若来源表数据小于 10000 ,可参考本文方案;若来源表数据大于 10000,可参考:数仓拉链表(来源表数据大于10000)
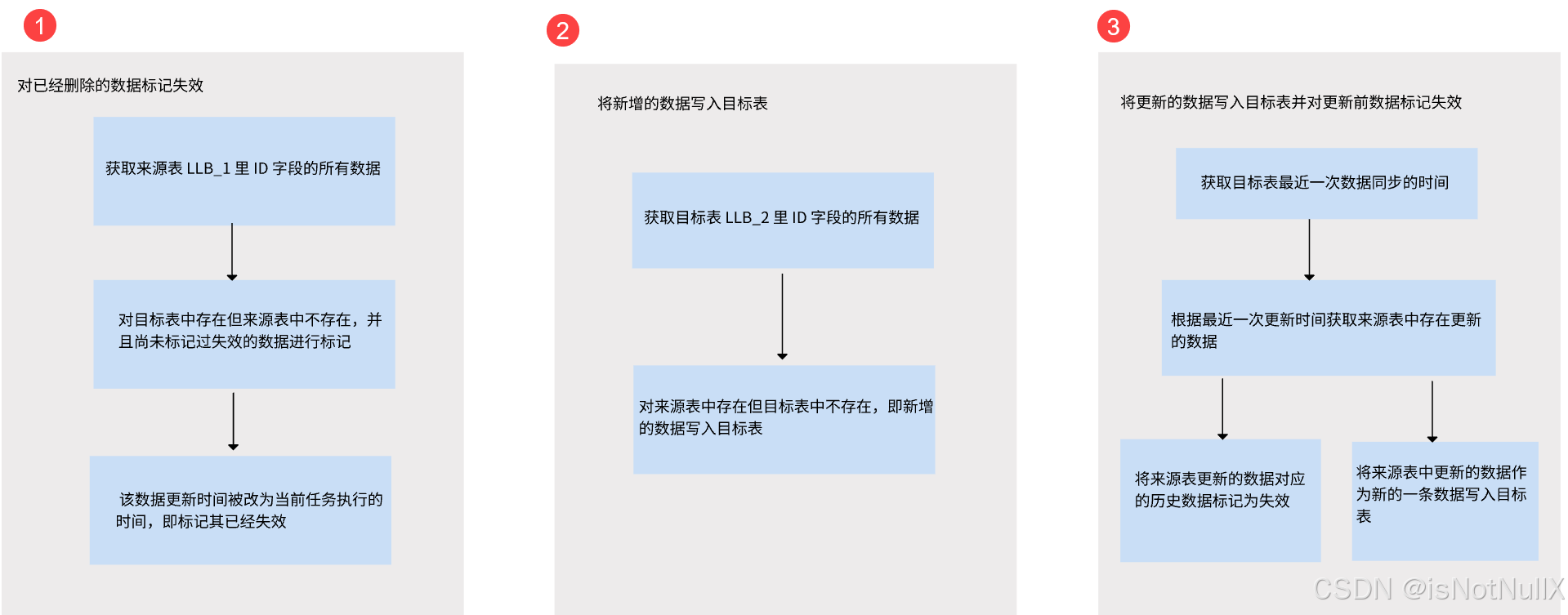
定时任务数仓拉链表的整体构建思路为:目标表内的所有数据只增不减,对于来源表新增、删除、更新数据的处理如下:
- 来源表有数据更新,则在目标表中:插入更新的数据,原记录失效时间变化为新记录插入时间。
- 来源表数据有新增记录,则在目标表中:直接插入新增的数据,生效时间为当前插入时间,失效时间不封顶。
- 来源表有数据删除,则在目标表中:对该记录失效时间进行变更,表明该记录失效。
任务 DEMO 详情参见:
官方demo:FineDataLink数据平台 02场景案例>数据仓库场景>03数仓拉链表
2.实现方法
(1)场景说明
数据库 test_2 中新建一张表 LLB_1,作为来源表,其主键为 ID,如下图所示:

数据库 test_1 中新建一张表 LLB_2,作为目标表,KEY_VALUES 为主键,自增序列(即行号),如下图所示:

目标表 LLB_2 中保留着来源表 LLB_1 上一次更新的数据,而当前来源表已经发生了如下改变:
- 删除了 1001 线圈的记录
- 新增了 1004 木材的记录
- 更改了 1002 铜管的 UNIT 为 5000
接下来要将来源表数据的变化,更新到目标表中,同时满足保留历史快照的要求。
(2)方案说明
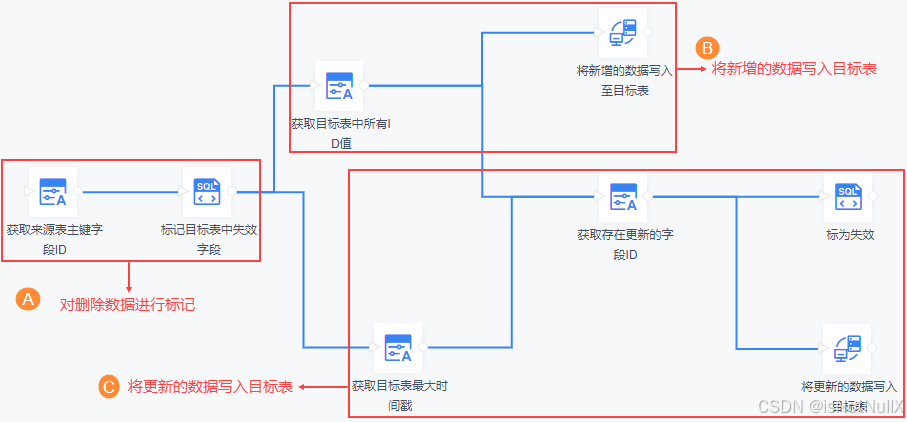
在 FineDataLink 中任务设计如下图所示:
3.操作步骤
(1)对删除的数据进行标记
- 首先需要获取来源表 LLB_1 里 ID 字段的所有数据,便于后续将其作为参数,与目标表数据进行对比,找到来源表删除的数据。
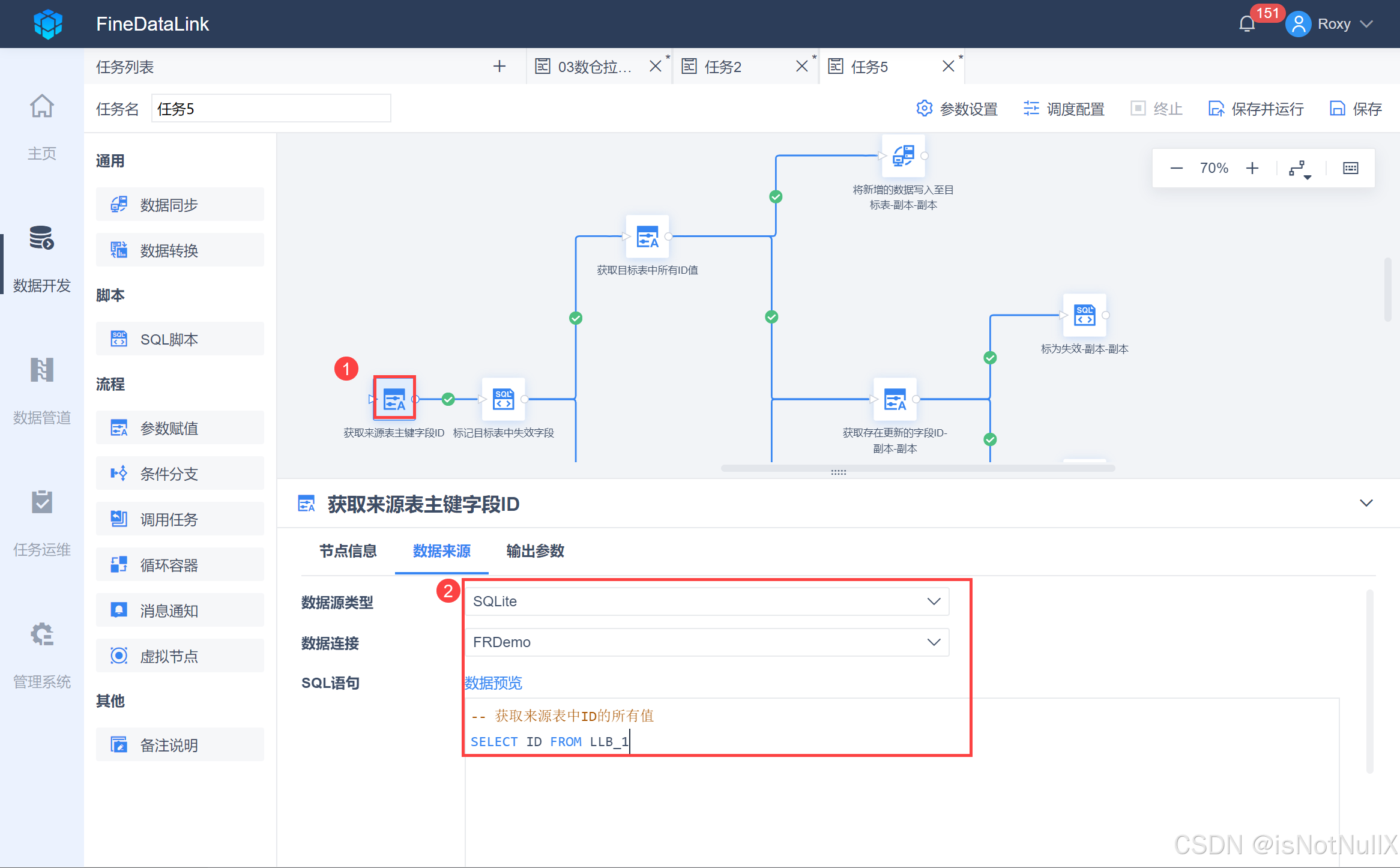
- 创建一个定时任务,将一个「参数赋值」节点拖到设计界面,并重命名为「获取来源表主键字段ID」,输入 SQL 语句,如下图所示:
-- 获取来源表中ID的所有值
SELECT ID FROM LLB_1
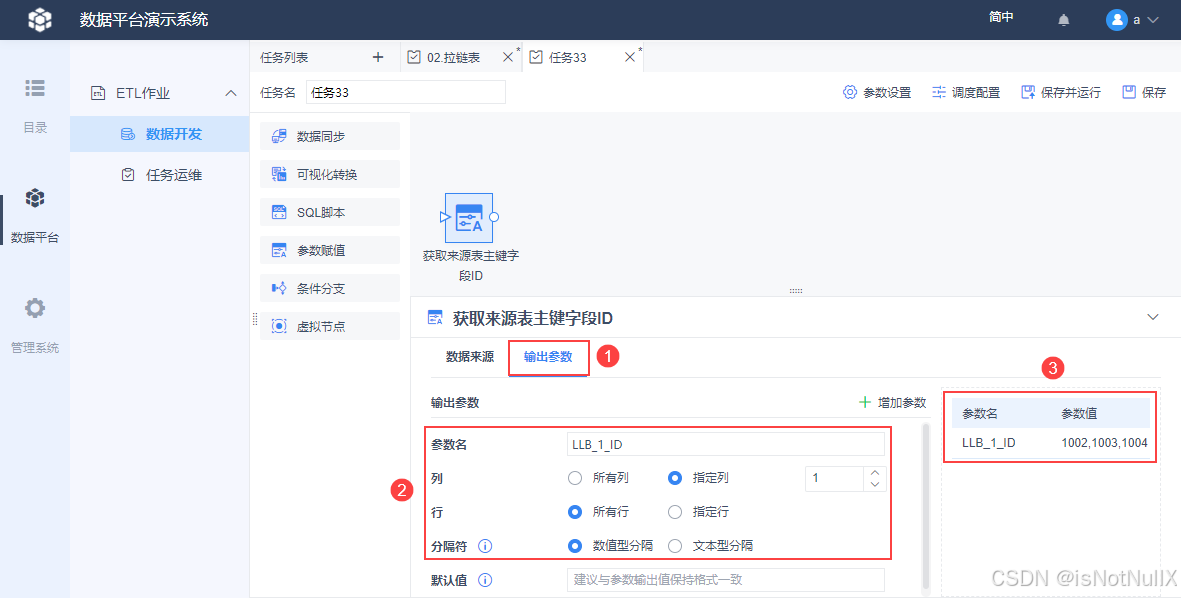
- 将获取到的 ID 设置为参数,如下图设置,设置好后可使用参数预览先看看效果。
- 接着需要对目标表 LLB_2 中存在但来源表 LLB_1 中不存在,并且尚未标记过失效(ODS_END_DATE时间为2199-12-20 23:59:59)的被删除的数据进行标记。
- 将一个「SQL脚本」拖到设计界面,重命名为「标记目标表中失效字段」,并用线条跟上游「获取来源表主键字段ID」节点连接。
输入 SQL 语句,如下图所示:
-- 筛除出目标表中存在但是来源表不存在,且尚未标记过失效的字段,进行标记(update)
UPDATE LLB_2 SET LLB_2.ODS_END_DATE = NOW()
WHERE LLB_2.ID NOT IN (${LLB_1_ID}) AND LLB_2.ODS_END_DATE = '2199-12-20 23:59:59'
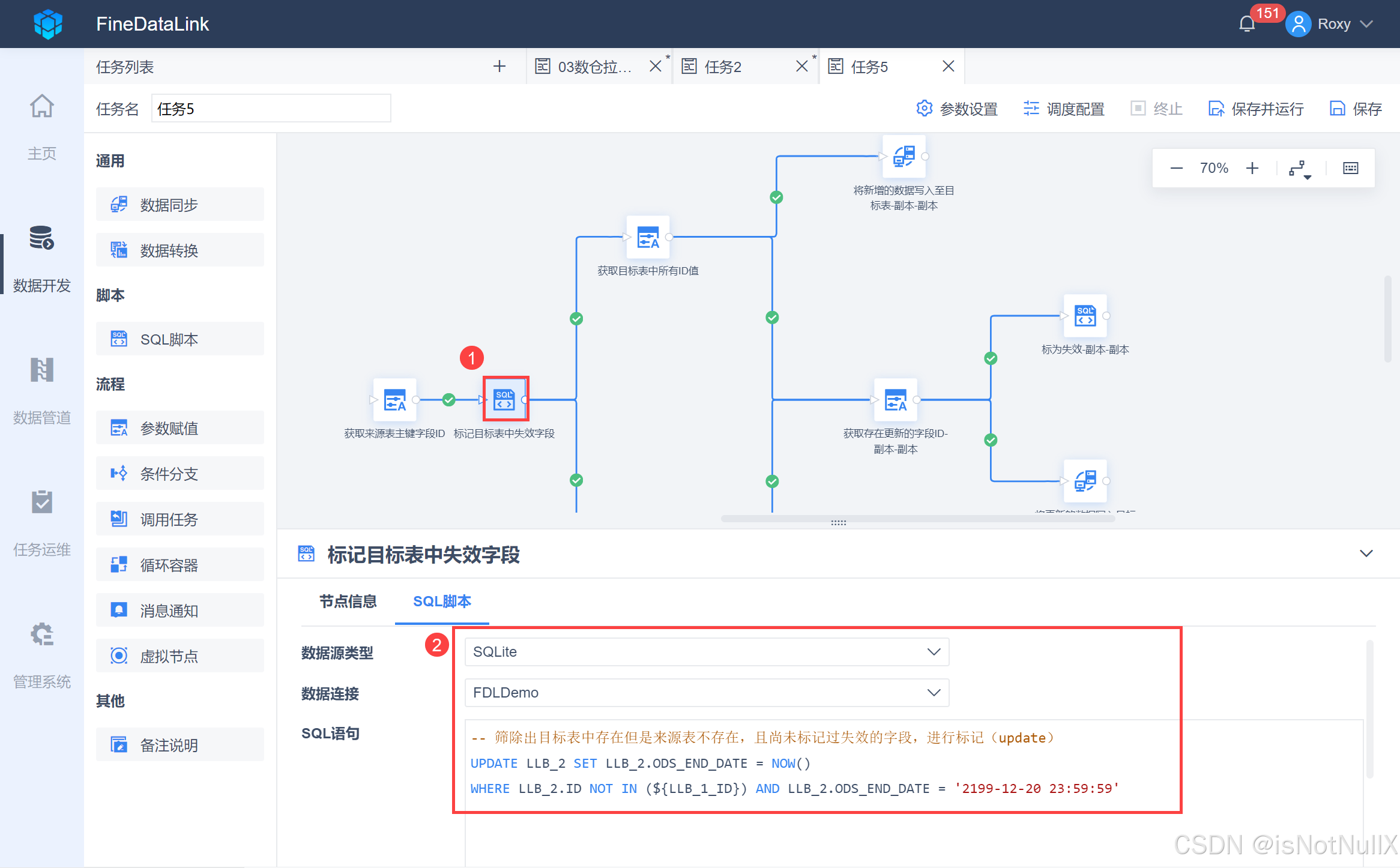
此步骤目标表中 1001 线圈数据(也就是在来源表中已经删除的数据)的更新时间会被改为当前任务执行的时间,即标记其已经失效,如下图所示:

(2)将新增数据写入目标表
- 获取目标表 LLB_2 里 ID 字段的所有数据,便于后续将其作为参数,与来源表LLB_1数据进行对比,找到来源表新增的数据。
- 将一个「参数赋值」节点拖到设计界面,并重命名为「获取目标表中所有ID值」,并用线条跟上游「标记目标表中失效字段」节点连接。输入 SQL 语句获取 LLB_2 表里 ID 字段的所有数据,如下图所示:
-- 获取目标表中ID的所有值
SELECT ID FROM LLB_2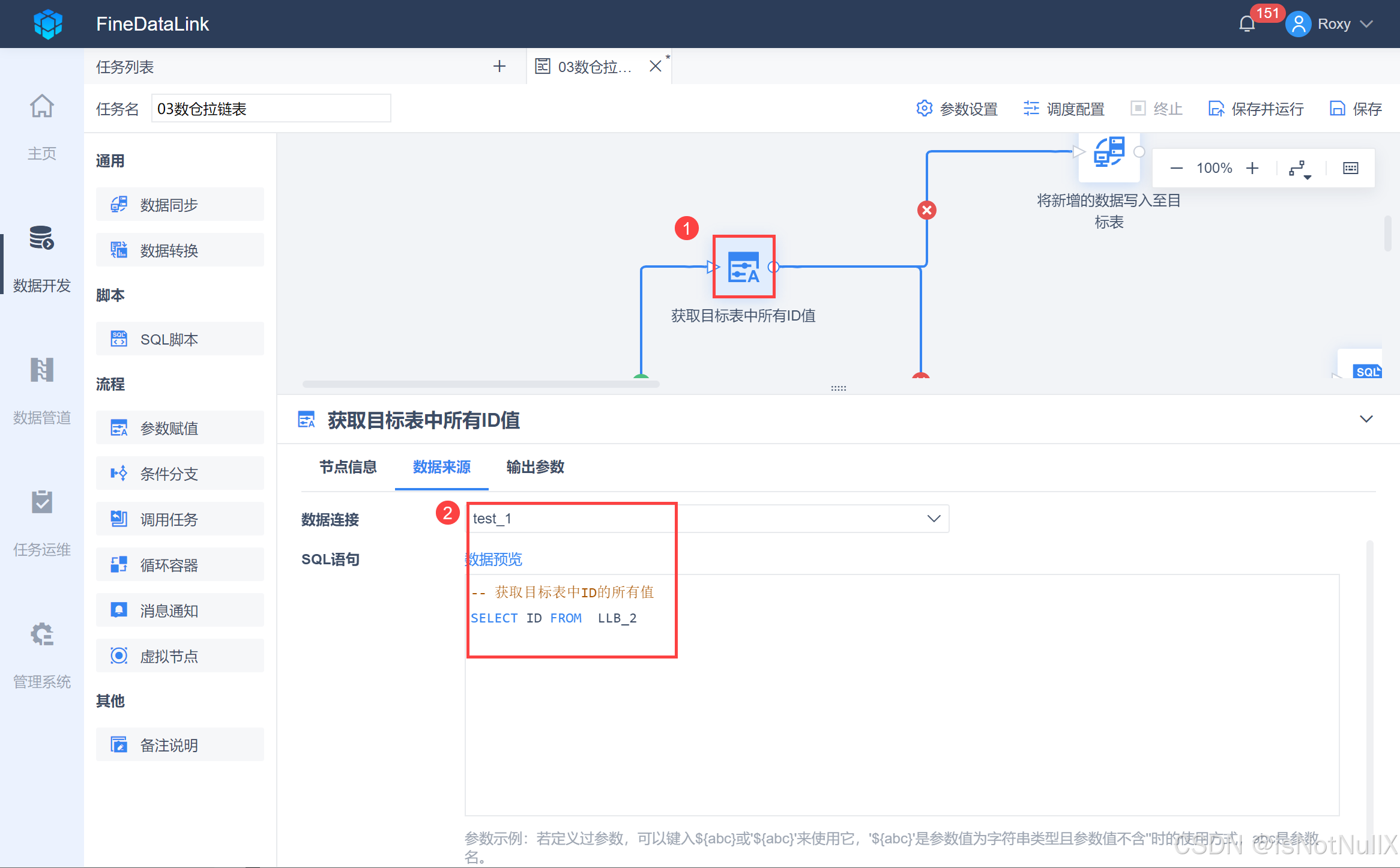
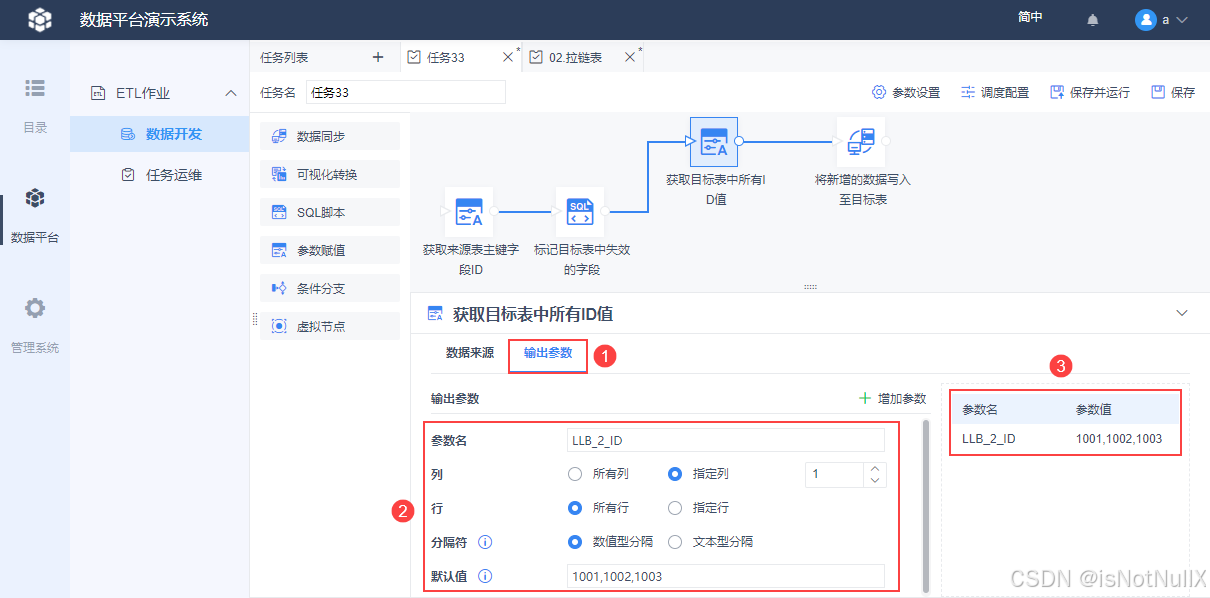
- 将获取到的 ID 输出为参数,如下图设置,设置好后可使用参数预览先看看效果。
注:此处要设置默认值,作用是下游节点可以预览数据和配置映射关系,但是运行任务时不会使用这些默认值。
- 接着需要对来源表 LLB_1 中存在但目标表 LLB_2 中不存在,也就是新增的数据写入目标表 LLB_2。
- 将一个「数据同步」节点拖到设计界面,并重命名为「将新增的数据写入至目标表」,并用线条跟上游「获取目标表中所有ID值」节点连接。
写入 SQL 语句获取来源表新增的数据,如下图所示:
-- 获取来源表中存在但是目标表中不存在的字段,即新增的数据
SELECT *,'2199-12-20 23:59:59' AS ODS_END_DATE FROM LLB_1 WHERE ID NOT IN (${LLB_2_ID})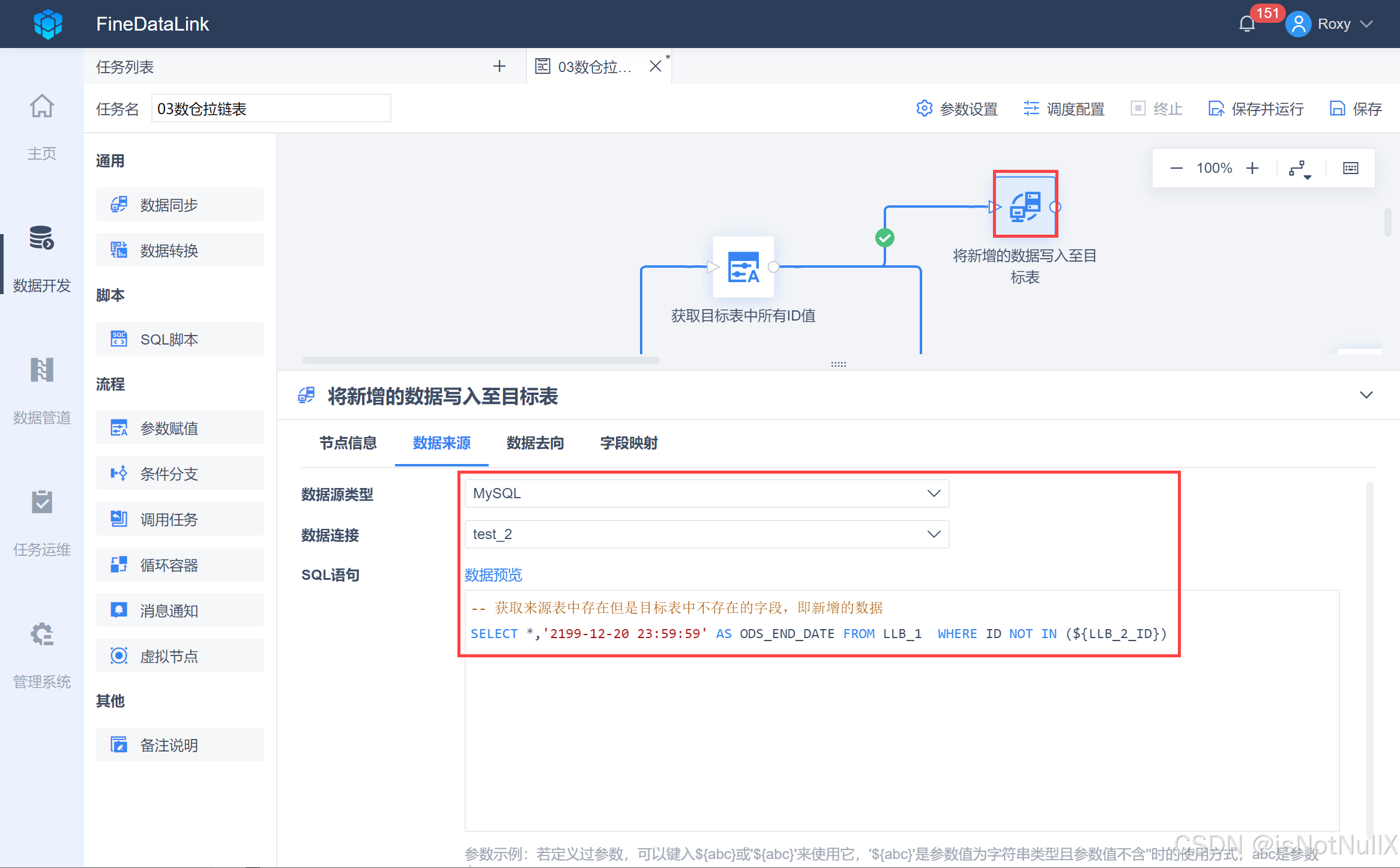
- 再设置这个数据同步节点的数据去向,将新增的数据写到目标表 LLB_2 中去。
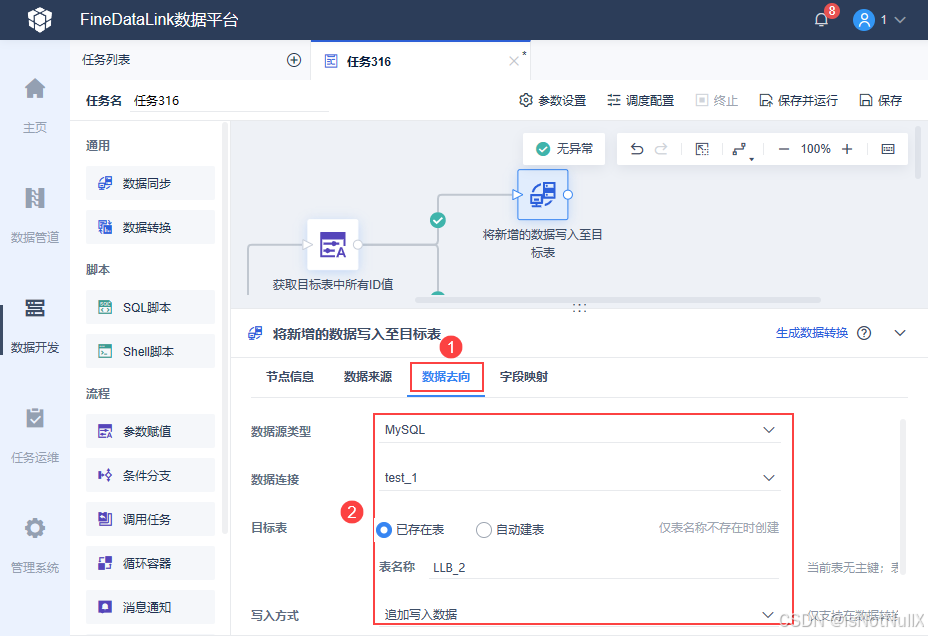
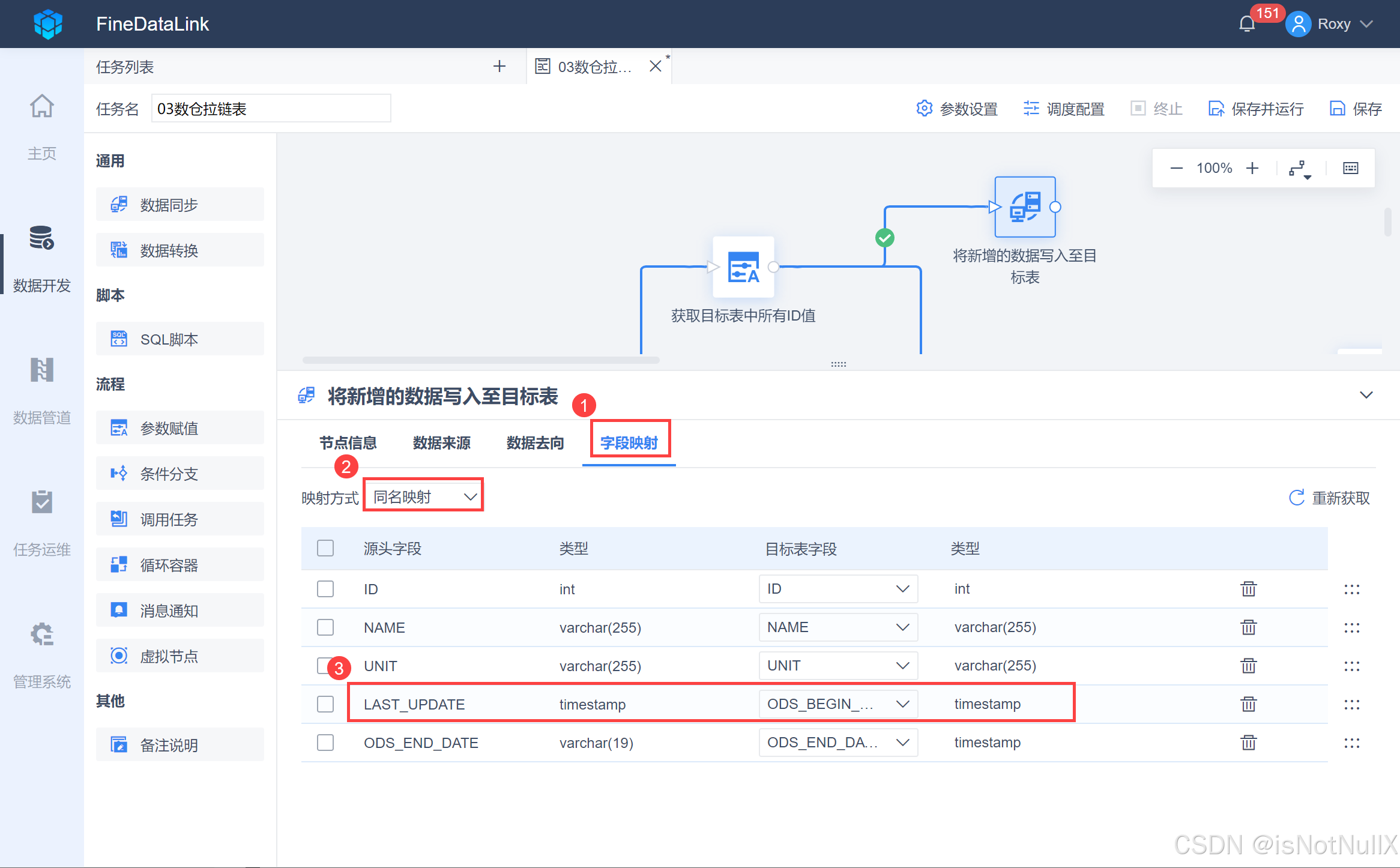
- 由于来源表和目标表的字段有一些不一致,因此在写入的时候,字段映射采用「同名映射」,同时需要手动调整对应目标字段,如下图所示:
字段映射关系详情参见:数据同步概述- FineDataLink帮助文档 3.3 节。
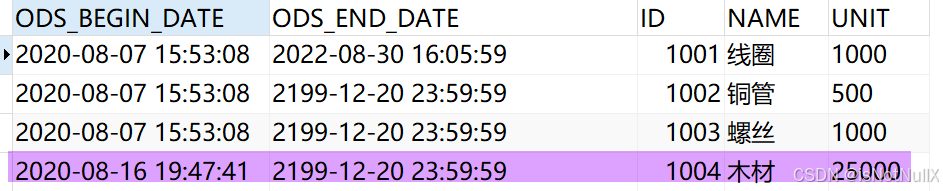
此步骤目标表中会新增 1004 木材数据(也就是在来源表中新增的数据),如下图所示:
(3)将更新的数据写入目标表
- 找到更新的数据
获取目标表 LLB_2 里 ODS_BEGIN_DATE 最晚时间,也就是最近一次数据同步的时间,便于后续将其作为参数,与来源表LLB_1数据进行对比,找到来源表更新的数据。
将一个「参数赋值」节点拖到设计界面,并重命名为「获取目标表最大时间戳」,并用线条跟上游「标记目标表中失效的字段」节点连接,输入 SQL 语句,获取目标表 LLB_2 中最近一次数据同步的时间,如下图所示:
SELECT MAX(ODS_BEGIN_DATE) FROM LLB_2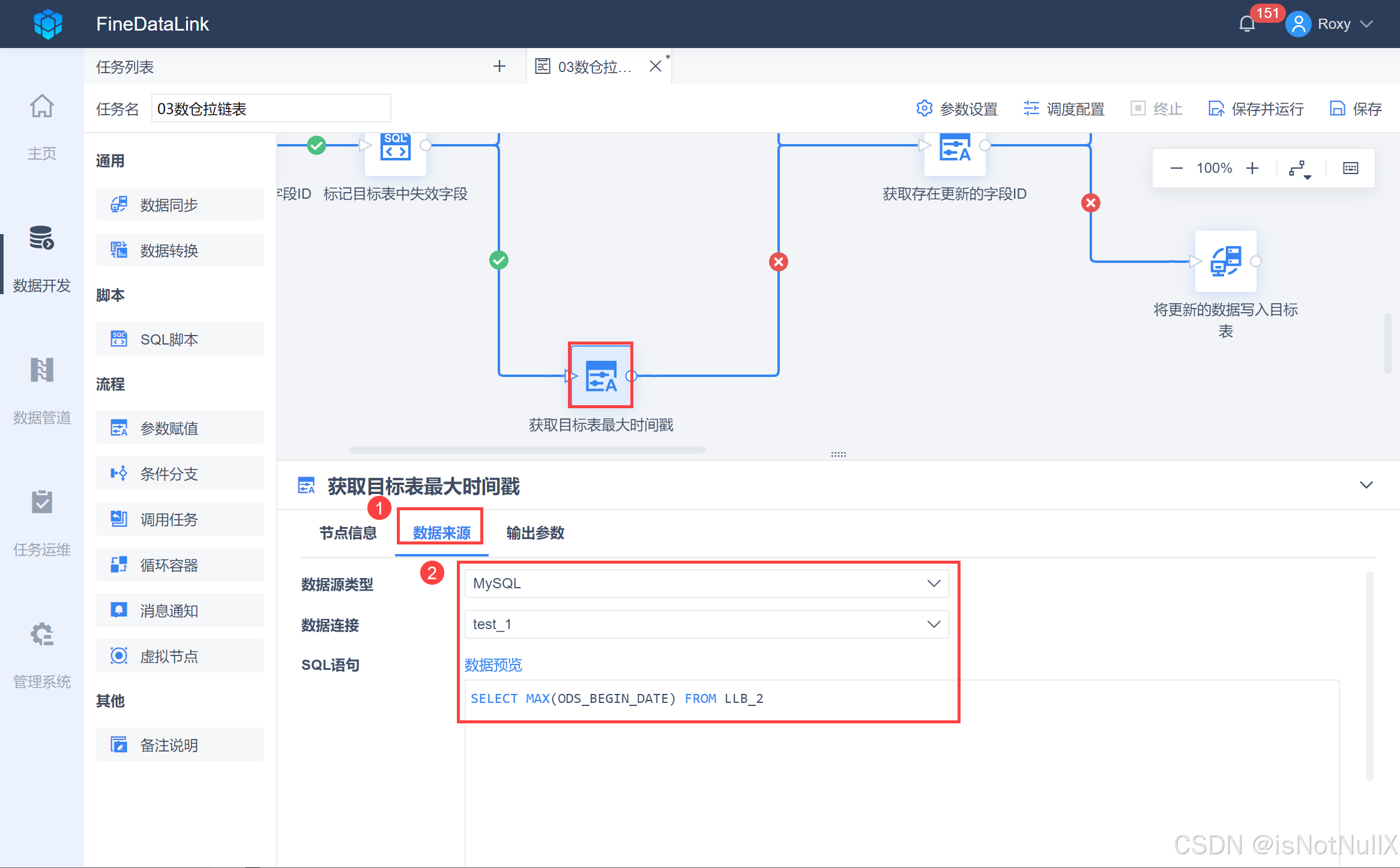
将取出来的最近一次同步时间输出为参数,如下图设置,可以使用参数预览先看看效果。
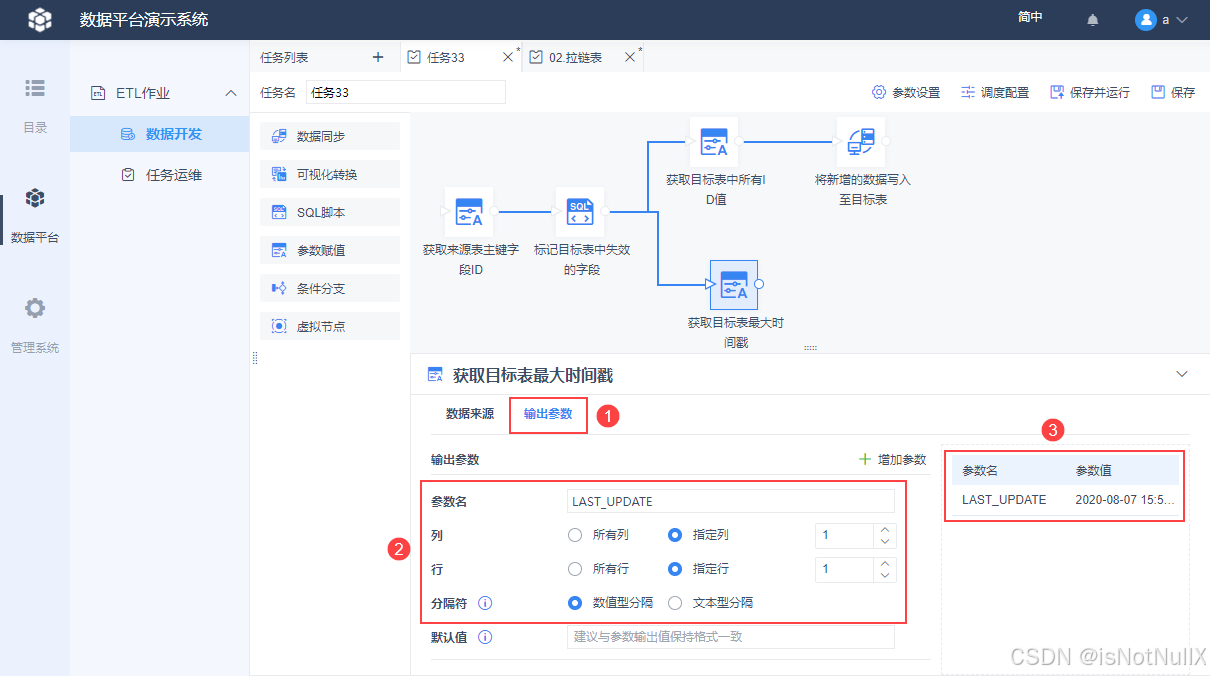
此时即可根据最近一次更新时间获取来源表 LLB_1 中存在更新的数据。
将一个「参数赋值」节点拖到设计界面,并重命名为「获取存在更新的字段ID」,并用线条跟上游「获取目标表中所有ID值」和「获取目标表最大时间戳」节点连接。输入 SQL 语句如下图所示:
-- 获取来源表中存在更新的数据
-- 获取思路:在来源表中寻找更新时间戳大于目标表中最大更新时间戳,且在目标表中已经存在的字段行
SELECT * FROM LLB_1 WHERE LLB_1.LAST_UPDATE > '${LAST_UPDATE}' AND LLB_1.ID IN (${LLB_2_ID})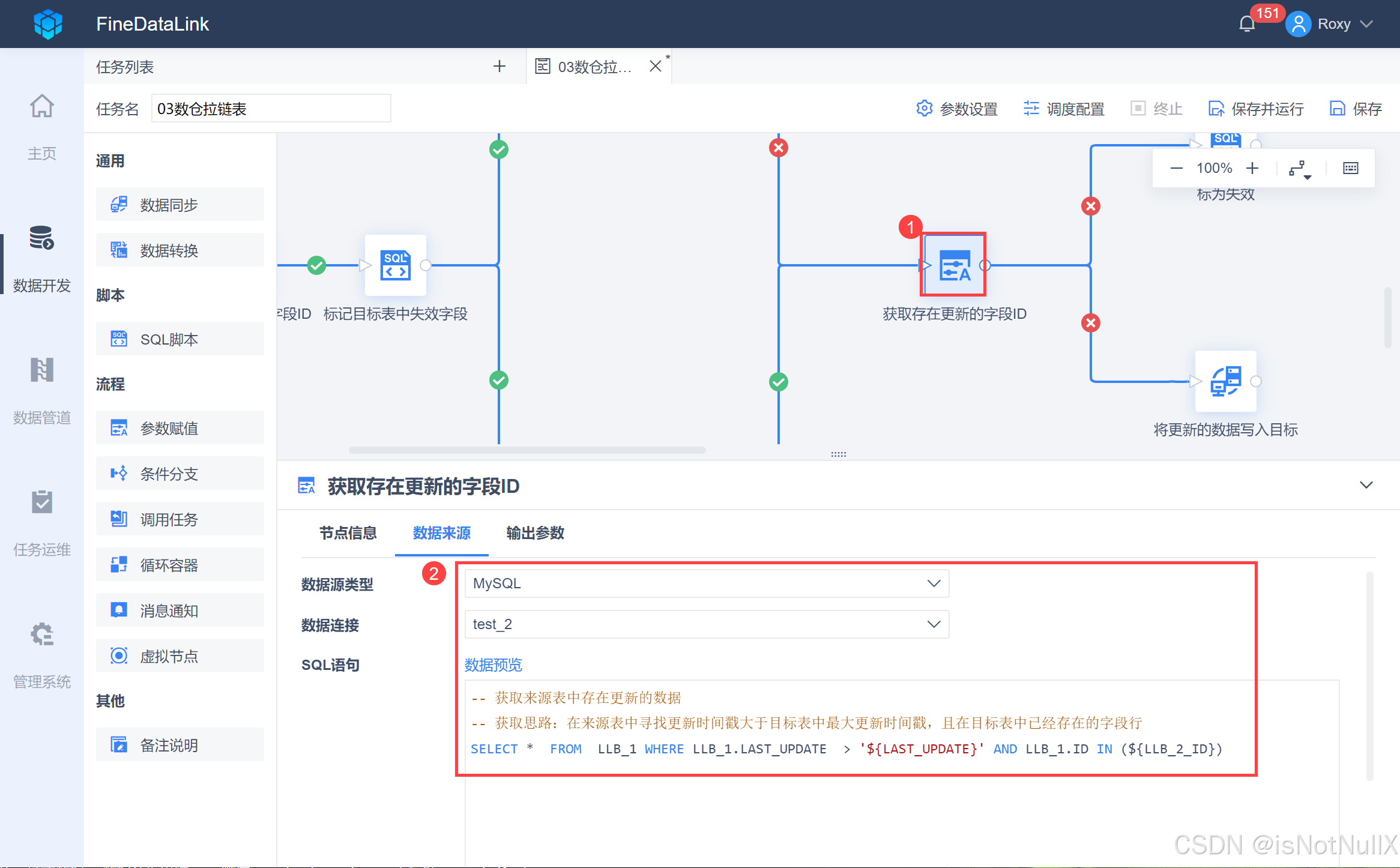
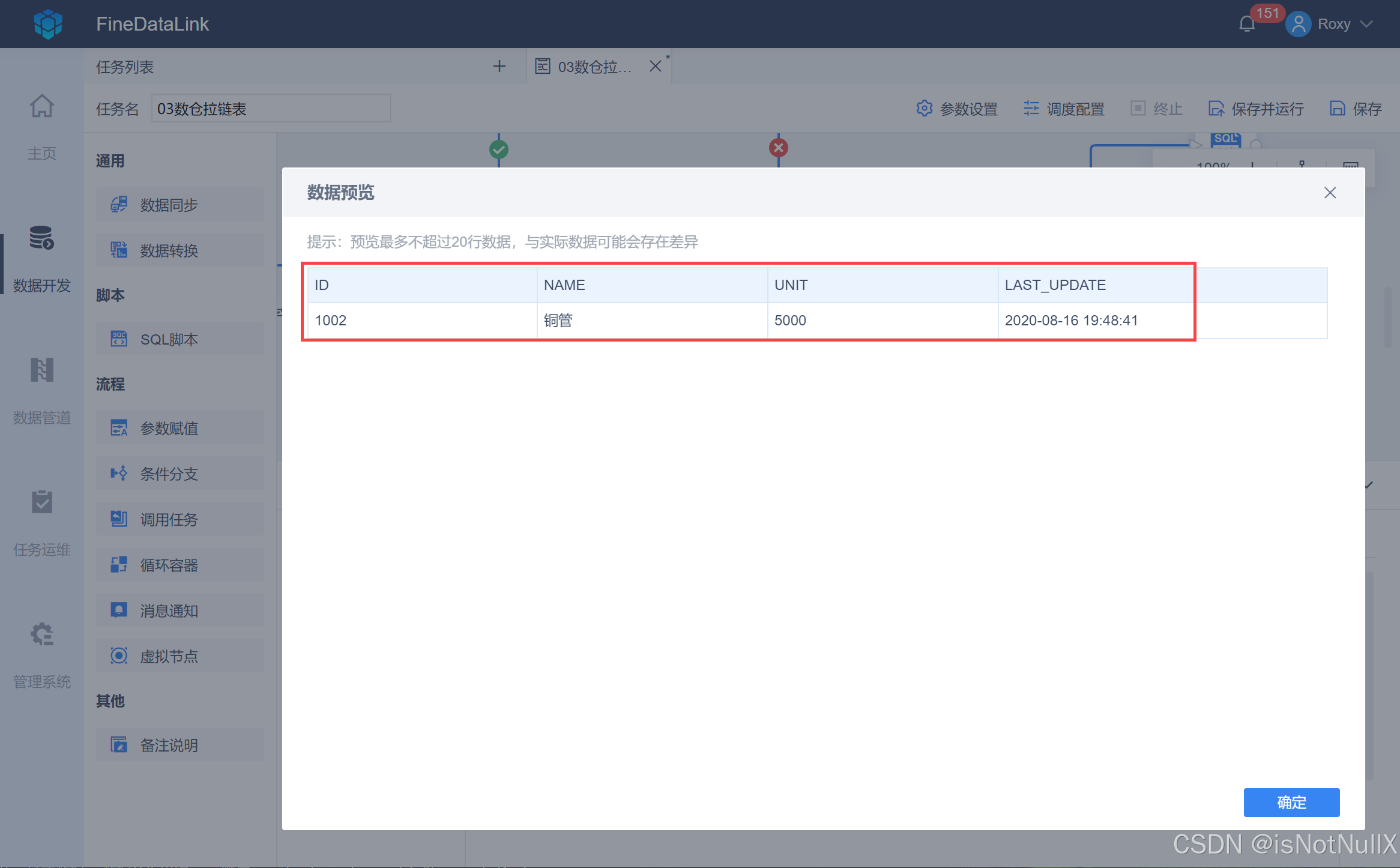
点击数据预览即可看到来源表中有数据更新的数据 1002 铜管数据,如下图所示:
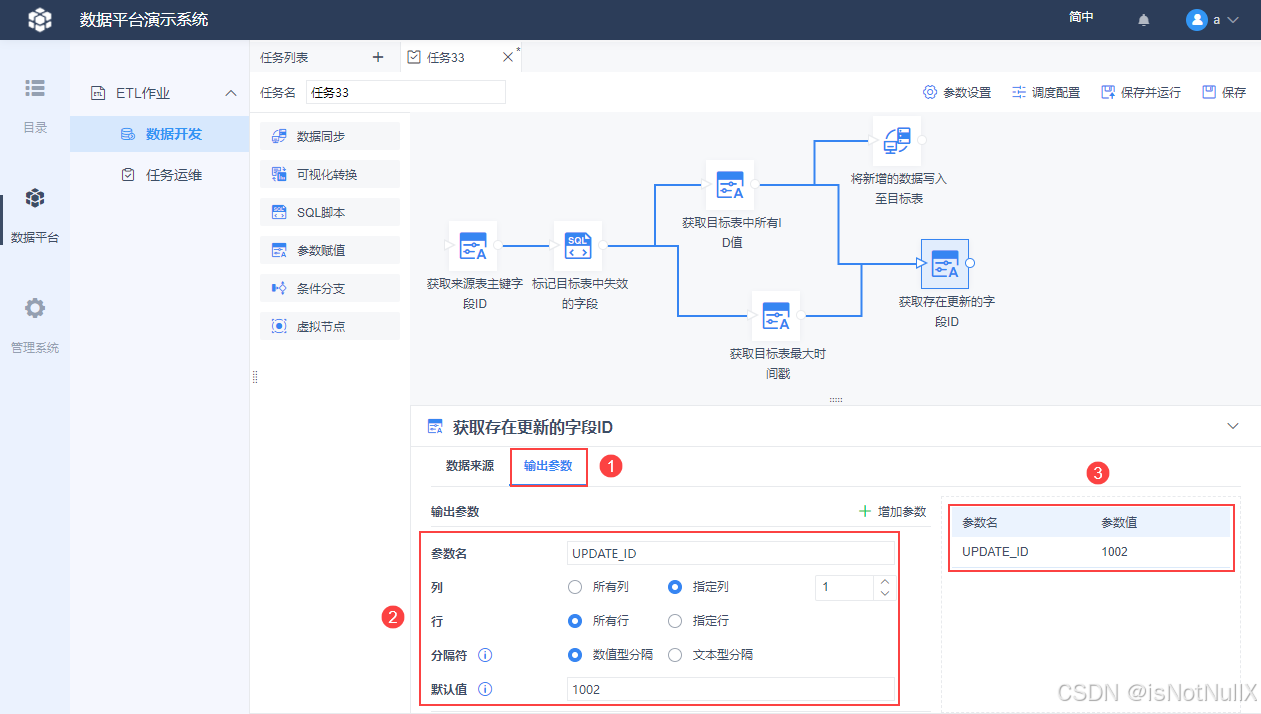
将更新过的 ID 输出为参数,如下图设置,可以使用参数预览先看看效果。
- 将更新数据对应的历史数据标记为失效
找到来源表更新的数据,然后即可将更新数据对应的历史数据标记为失效。
将一个「SQL脚本」拖到设计界面,重命名为「标为失效」,并用线条跟上游「获取存在更新的字段ID」节点连接,输入 SQL 语句,如下图所示:
-- 存在更新的数据插入目标表后,历史的数据就可以标记为失效了
UPDATE LLB_2 SET LLB_2.ODS_END_DATE = NOW()
WHERE LLB_2.ID IN (${UPDATE_ID}) AND LLB_2.ODS_END_DATE = '2199-12-20 23:59:59'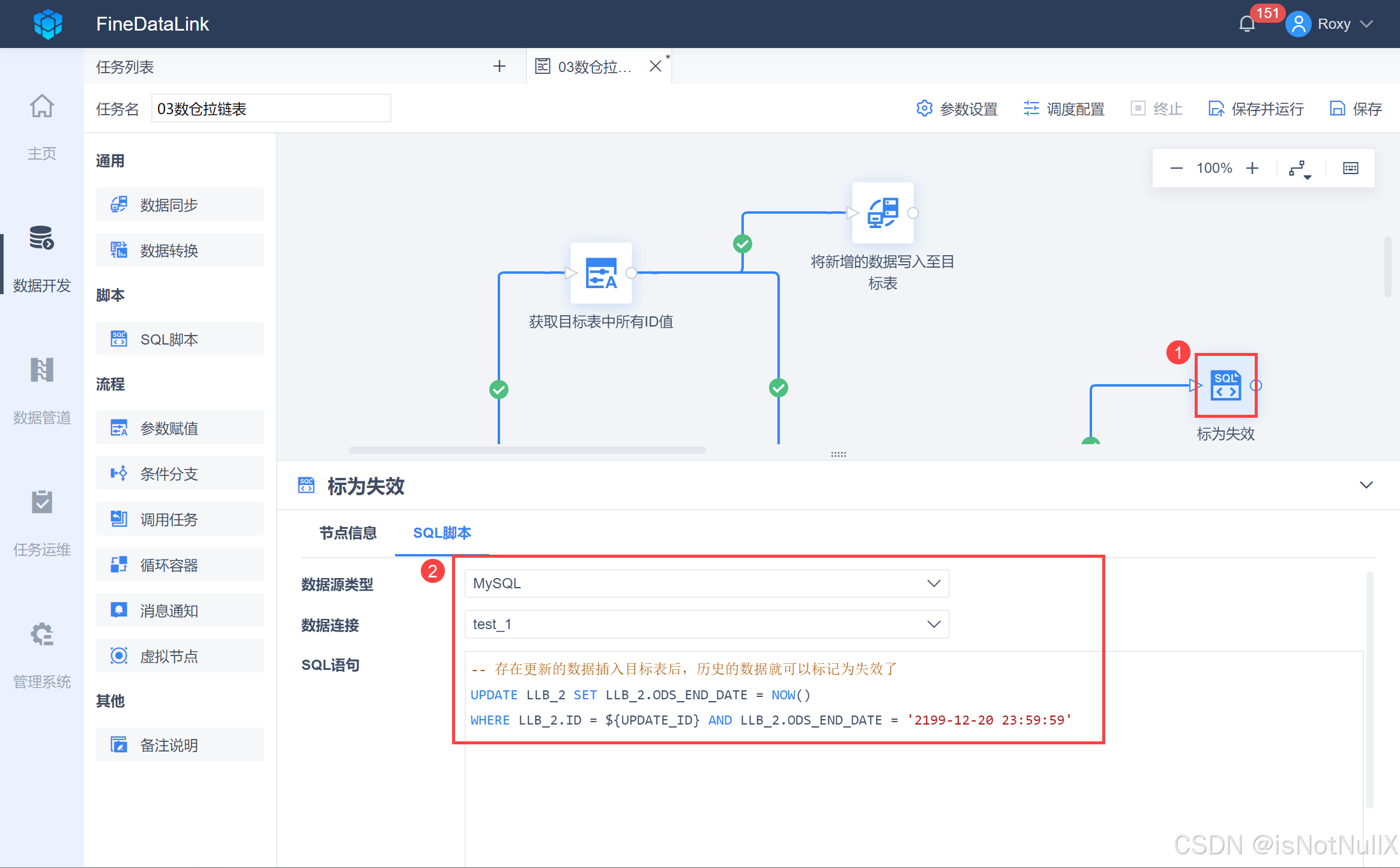
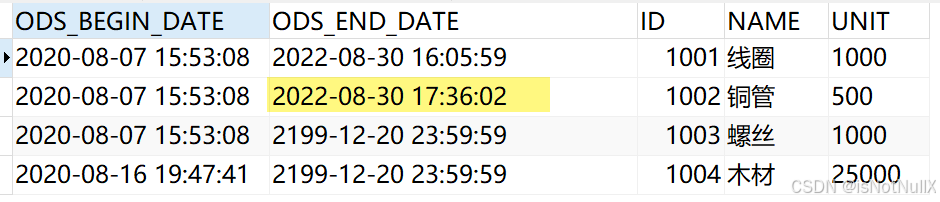
此步骤,目标表中会将来源表更新的数据对应的历史数据标记为失效,即结束时间由之前的 2199-12-20 23:59:59 改为任务更新的时间,如下图所示:
- 将新数据写入目标表
找到来源表更新的数据,可以将更新数据作为一条新的数据写入目标数据表。
将一个「数据同步」节点拖到设计界面,并重命名为「将更新的数据写入至目标表」,并用线条跟上游「获取存在更新的字段ID」节点连接,然后写入 SQL 语句,因为新写入的数据并没有失效,所以需要将 2199-12-20 23:59:59 写入目标数据表的 ODS_END_DATE 字段中。
-- 在来源表中,获取存在更新的字段行
SELECT *,'2199-12-20 23:59:59' AS ODS_END_DATE FROM LLB_1
WHERE LLB_1.ID IN (${UPDATE_ID})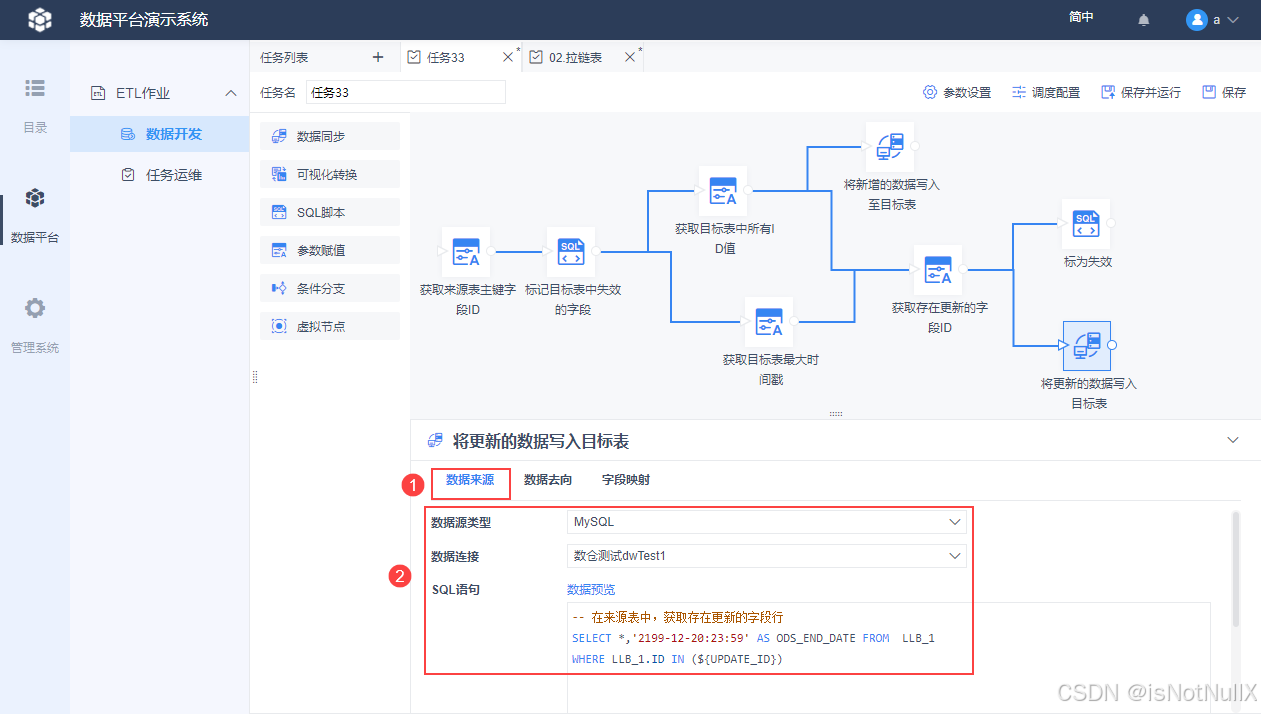
再设置这个数据同步节点的数据去向,将更新的数据写到目标表 LLB_2 中去。
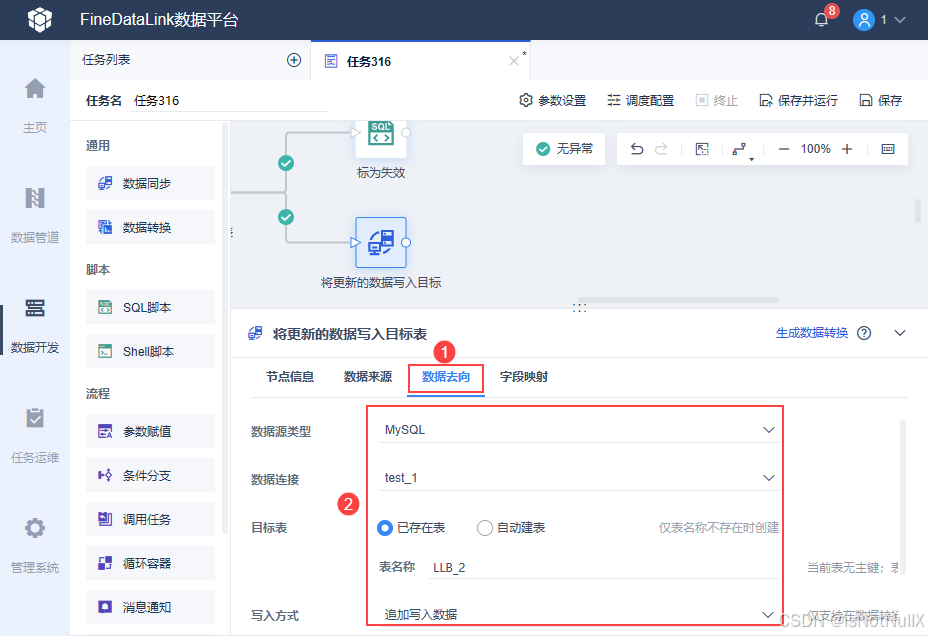
由于来源表和目标表的字段有一些不一致,因此在写入的时候,字段映射采用「同名映射」,同时需要手动调整对应目标字段,如下图所示:
字段映射关系详情参见:数据同步概述- FineDataLink帮助文档 3.3 节。
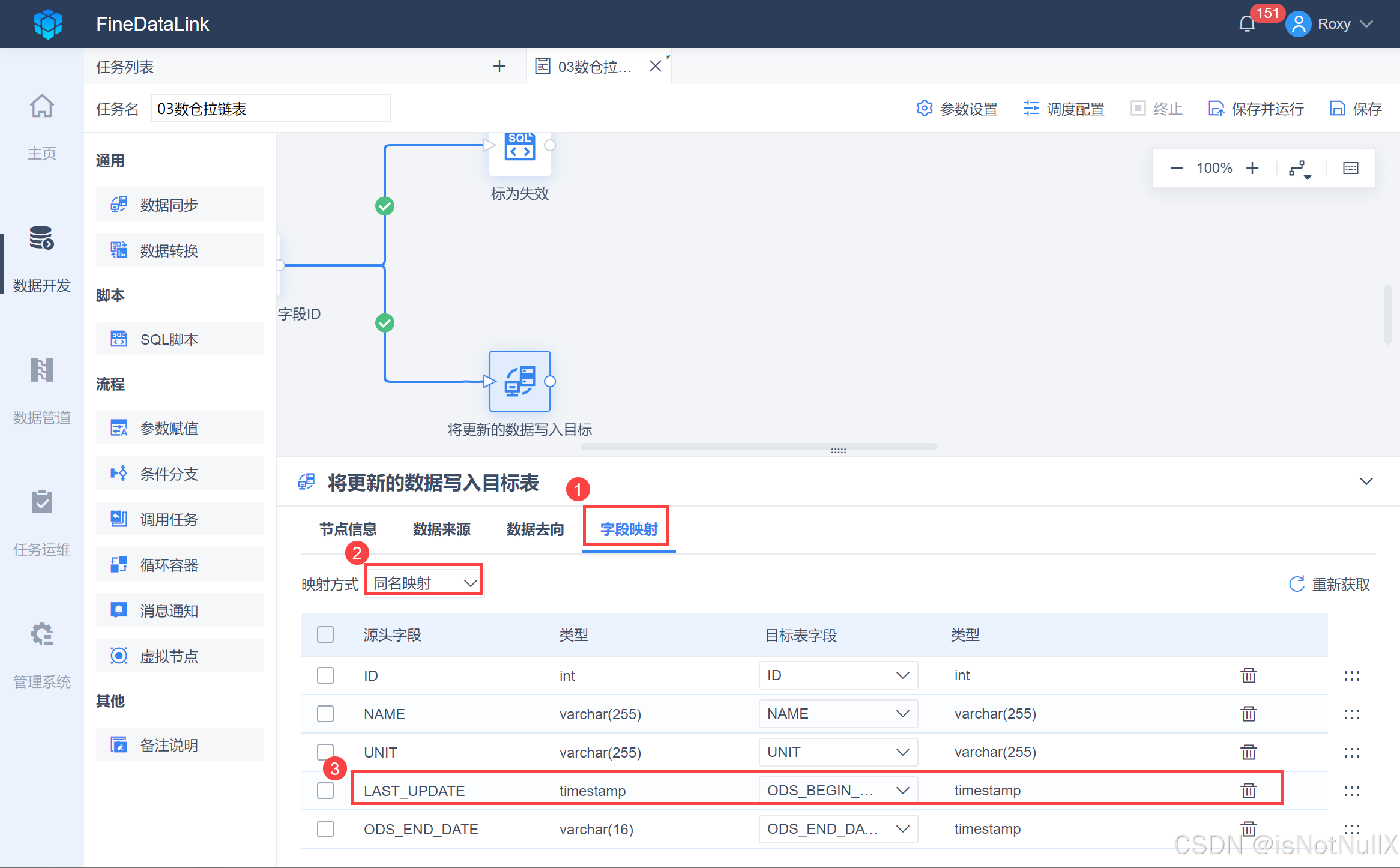
此步骤目标表中会新增 1002 铜管数据(也就是在来源表中更新的数据),作为一条新增的数据写入目标表,同时结束时间显示为 2199-12-20 23:59:59,即未失效,如下图所示:
(4)运行任务
执行该定时任务。
4.效果查看
更新后的目标数据表中会有如下变化:
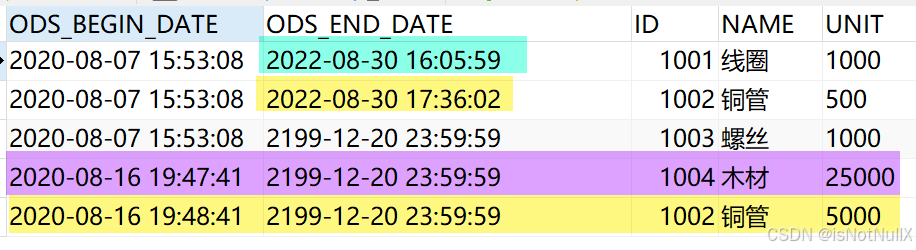
通过这些步骤,FineDataLink可以快速构建高效可靠的数仓拉链表,为企业数据分析和决策提供有力支持。
帆软FineDataLink——中国领先的低代码/高时效数据治理工具,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
了解更多数据仓库与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能
往期推荐:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









