



 本文介绍了一种基于多任务级联神经网络的实时人脸检测、配准及头部姿态估计方法。该方法在MTCNN的基础上,利用人脸配准与头部姿态间的内在联系,增强了密集人脸配准性能。实验结果显示,此方法在大姿态情况下仍能获得准确的特征点定位。
本文介绍了一种基于多任务级联神经网络的实时人脸检测、配准及头部姿态估计方法。该方法在MTCNN的基础上,利用人脸配准与头部姿态间的内在联系,增强了密集人脸配准性能。实验结果显示,此方法在大姿态情况下仍能获得准确的特征点定位。
文章发表在ICPR2018上,采用一个多任务级联神经网络的框架来实现实时的人脸检测、人脸配准以及头部姿态估计。MTCNN能够实现实时的人脸检测和人脸配准,尽管它在人脸配准方面的性能超越了许多其他最新的方法,但它仅仅输出了 5 个特征点,当需要输出更加密集的特征点时并不能得到很好的效果。所以,本文利用了人脸配准和头部姿态估计之间的内在联系来增强密集的人脸配准性能。
1.网络结构
四个阶段的网络设计如下图:
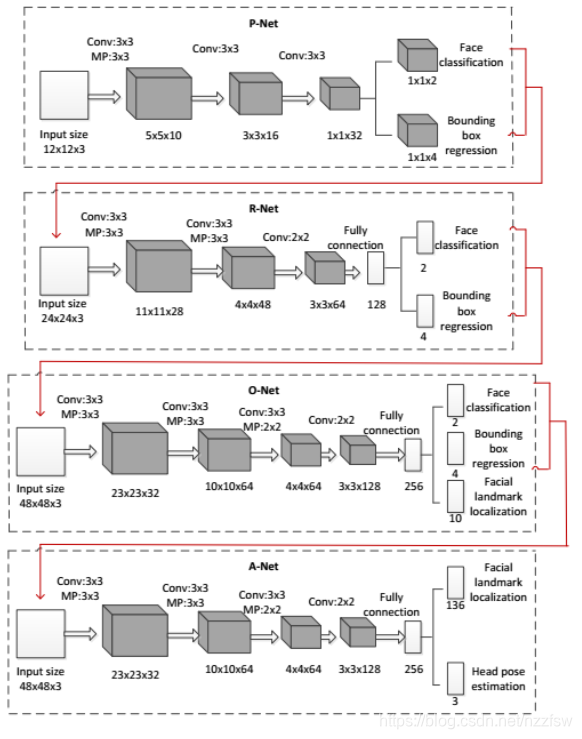
前三个阶段与MTCNN类似,最后一个阶段利用特征点和头部姿态之间的内在联系来同时训练网络。
2.实验结果

在上图 ,左边的两列图像来自于 LFPW,中间的两列图像来自于 HELEN,右边的两列图像来自于 IBUG,每
两列图像左侧一列是 our method without pose 的测试结果,右侧一列是我们的方法的测试结果。从图 中 可以观察到,通过我们的方法得到的特征点位置更加贴合人脸的眉毛、眼睛、鼻子、嘴唇以及外轮廓,而 our method without pose 在非正脸的情况下,特征点的位置容易发生“漂移”的情况。这也进一步说明了,即使是在大姿态的情况下,我们的方法也能够得到比较出色的特征点定位结果。


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









