



引言
Meta推出了一项名为“Massively Multilingual Speech”(MMS)的项目,旨在解决语音识别和生成技术中的多语言挑战。这个项目结合了wav2vec 2.0的自监督学习方法和一个新的数据集,提供了超过1,100种语言的标记数据和近4,000种语言的非标记数据。这些语言中的一些,如Tatuyo语,仅有几百名讲者,而且大多数这些语言之前没有任何语音技术。
MMS项目的模型在现有模型上取得了显著的性能提升,并覆盖了比现有模型多10倍的语言。Meta公开分享了这些模型和代码,以便研究社区能够在此基础上进一步构建。MMS支持1,107种语言的语音识别和文本转语音,以及超过4,000种语言的语言识别。
在数据收集方面,Meta利用了诸如圣经之类的文本,这些文本已被翻译成多种语言,并且有公开可用的不同语言的音频录音。通过这些数据,Meta创建了一个包含1,100多种语言的新约阅读数据集,平均每种语言提供了32小时的数据。此外,通过考虑其他宗教读物的未标记录音,Meta将可用语言的数量增加到了4,000多种。

技术实现
在技术实现方面,Meta基于wav2vec 2.0的自监督语音表示学习工作,大大减少了训练良好系统所需的标记数据量。具体来说,Meta在超过1,400种语言的大约500,000小时的语音数据上训练了自监督模型。然后,这些模型被微调用于特定的语音任务,如多语言语音识别或语言识别。
性能方面
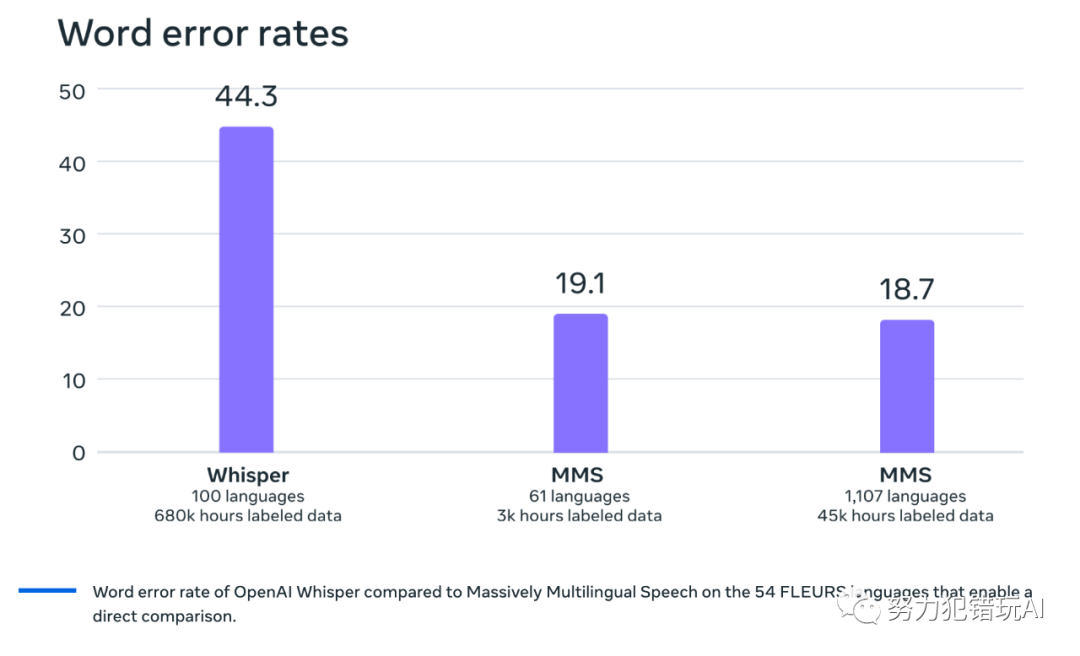
在性能方面,Meta对使用Massively Multilingual Speech数据训练的模型进行了评估。例如,在FLEURS基准测试中,Meta训练了一个覆盖1,100多种语言的多语言语音识别模型,使用了10亿参数的wav2vec 2.0模型。尽管语言数量的增加会导致性能略有下降,但下降幅度非常小:从61种语言增加到1,107种语言,字符错误率仅增加了约0.4%,但语言覆盖范围增加了18倍以上。
此外,Meta还构建了覆盖1,100多种语言的文本转语音系统。尽管Massively Multilingual Speech数据中许多语言的不同发言者数量相对较少,甚至有些只有一个发言者,但这对于构建文本转语音系统来说是一个优势。Meta发现这些系统产生的语音质量良好。
应用场景
Meta的“Massively Multilingual Speech”(MMS)项目不仅在技术上取得了显著进步,而且在实际应用方面也具有广泛的潜力。以下是一些适用的应用场景:
-
全球通信和协作:MMS项目支持超过1,100种语言的语音识别和文本转语音,这使得全球范围内的人们可以使用自己的母语进行通信。这对于国际公司和组织来说尤其重要,它们需要跨越语言障碍以促进更有效的全球合作。
-
教育和学习:MMS可以用于开发教育应用程序,帮助学习者学习新语言或提高语言技能。它也可以用于创建多语言的教育内容,使学习资源对更广泛的受众开放。
-
内容创作和翻译:内容创作者可以利用MMS将他们的作品翻译成多种语言,从而触及更广泛的受众。这对于新闻机构、博客作者和视频制作者来说尤其有用。
-
客户服务和支持:企业可以使用MMS来提供多语言的客户服务,无论客户使用何种语言,都能得到及时有效的帮助。
-
辅助技术:对于有语言障碍或听力障碍的人来说,MMS可以作为一种辅助工具,帮助他们更好地理解和交流。
-
语言保存和记录:对于那些只有少数人使用的语言,MMS提供了一种记录和保存这些语言的方式,这对于语言学家和文化保存者来说非常重要。
-
旅游和国际交流:MMS可以用于开发旅游应用程序,帮助游客更好地理解和沟通,无论他们身在何处。
总的来说,Meta的Massively Multilingual Speech项目在推动多语言语音技术方面迈出了重要一步。未来,Meta希望增加语言覆盖范围,支持更多语言,并解决处理方言的挑战,这对现有的语音技术来说往往是困难的。Meta的目标是让人们更容易地以自己偏好的语言获取信息和使用设备。此外,Meta还设想未来一个单一模型能够解决所有语言的多种语音任务,从而实现更好的整体性能。
参考资料
GitHub
https://github.com/facebookresearch/fairseq
huggingface
https://huggingface.co/facebook/mms-tts-eng
AI快站国内模型下载
https://aifasthub.com/models/facebook


















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









