






 本文详细介绍了ShardingSphere在数据源配置、SQL路由与执行、分片策略、数据结果集归并等方面的工作原理。通过自定义数据源和配置注入器,实现了对HikariDataSource的扩展,以解决Sharding-JDBC中属性设置不生效的问题。在SQL路由过程中,ShardingPreparedStatement根据分片规则和SQL类型进行解析和路由,利用PreparedStatementRoutingEngine确定实际的数据库和表。分片策略如StandardShardingStrategy和ComplexShardingStrategy用于计算分片节点。数据结果集的归并通过MergeEngine实现,根据不同的场景选择MemoryMergedResult或StreamMergedResult。此外,还探讨了流式查询(ResultsetRowsStreaming)的优势和弊端,以及如何根据连接限制和内存限制选择合适的QueryResult类型。
本文详细介绍了ShardingSphere在数据源配置、SQL路由与执行、分片策略、数据结果集归并等方面的工作原理。通过自定义数据源和配置注入器,实现了对HikariDataSource的扩展,以解决Sharding-JDBC中属性设置不生效的问题。在SQL路由过程中,ShardingPreparedStatement根据分片规则和SQL类型进行解析和路由,利用PreparedStatementRoutingEngine确定实际的数据库和表。分片策略如StandardShardingStrategy和ComplexShardingStrategy用于计算分片节点。数据结果集的归并通过MergeEngine实现,根据不同的场景选择MemoryMergedResult或StreamMergedResult。此外,还探讨了流式查询(ResultsetRowsStreaming)的优势和弊端,以及如何根据连接限制和内存限制选择合适的QueryResult类型。
目录
自定义数据源 DataSourcePropertiesSetter
Query执行过程 ShardingPreparedStatement#executeQuery
sql路由 PreparedStatementRoutingEngine#route
自定义数据源 DataSourcePropertiesSetter
通过实现接口 org.apache.shardingsphere.spring.boot.datasource.DataSourcePropertiesSetter 来反射方式给DataSource注入属性。
package org.apache.shardingsphere.spring.boot.datasource;
/** Hikari datasource properties setter. */
public final class HikariDataSourcePropertiesSetter implements DataSourcePropertiesSetter {
public void propertiesSet(final Environment environment, final String prefix, final String dataSourceName, final DataSource dataSource) {
Properties properties = new Properties();
String datasourcePropertiesKey = prefix + dataSourceName.trim() + ".data-source-properties";
if (PropertyUtil.containPropertyPrefix(environment, datasourcePropertiesKey)) {
Map datasourceProperties = PropertyUtil.handle(environment, datasourcePropertiesKey, Map.class);
properties.putAll(datasourceProperties);
Method method = dataSource.getClass().getMethod("setDataSourceProperties", Properties.class);
method.invoke(dataSource, properties);
}
}
@Override
public String getType() {
return "com.zaxxer.hikari.HikariDataSource";
}
}SpringBootConfiguration(shardingsphere自己的)因实现了EnvironmentAware接口,所以会执行它的#setEnvironment方法。

所以:上示例代码中的 String prefix = "spring.shardingsphere.datasource."。
同时,调用方法SpringBootConfiguration#getDataSource创建DataSource,会根据#getType()指定类型的数据源匹配属性注入文件。
自定义数据源和配置注入器:
package com.noob.shardingJdbc.dataSoure;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import com.zaxxer.hikari.util.PropertyElf;
import java.util.Properties;
public class CustomizeHikariDataSource extends HikariDataSource {
public CustomizeHikariDataSource() { super(); }
public CustomizeHikariDataSource(HikariConfig configuration) { super(configuration); }
/* 解决sharding-jdbc在设置setDataSourceProperties后不生效的问题 */
@Override
public void setDataSourceProperties(Properties dsProperties) {
super.setDataSourceProperties(dsProperties); // 只是设置dataSourceProperties
// 还需要真实写入到dataSource的成员属性里。 见HikariConfig(Properties properties)
PropertyElf.setTargetFromProperties(this, this.getDataSourceProperties());
}
}
//--------
import lombok.SneakyThrows;
import org.apache.shardingsphere.spring.boot.datasource.DataSourcePropertiesSetter;
import org.apache.shardingsphere.spring.boot.datasource.HikariDataSourcePropertiesSetter;
import org.springframework.core.env.Environment;
import javax.sql.DataSource;
public final class CustomizeHikariDataSourcePropertiesSetter implements DataSourcePropertiesSetter {
HikariDataSourcePropertiesSetter setter = new HikariDataSourcePropertiesSetter();
@SneakyThrows(ReflectiveOperationException.class)
public void propertiesSet(final Environment environment, final String prefix, final String dataSourceName, final DataSource dataSource) {
setter.propertiesSet(environment, prefix, dataSourceName, dataSource);
}
@Override
public String getType() {
return "com.noob.shardingJdbc.dataSoure.CustomizeHikariDataSource";
}
}自动配置类 SpringBootConfiguration
package: org.apache.shardingsphere.shardingjdbc.spring.boot 。
根据配置差异会选择实例化不同的DataSource类型:
-
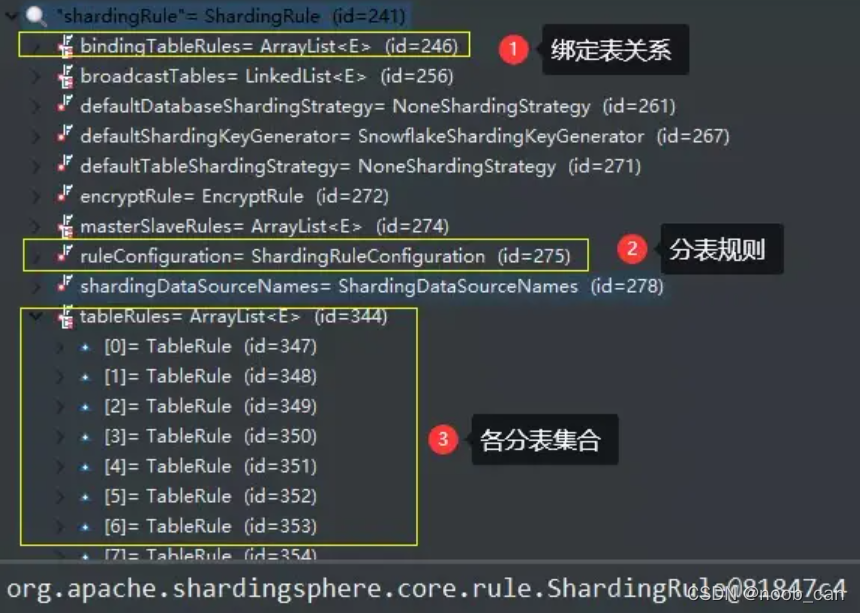
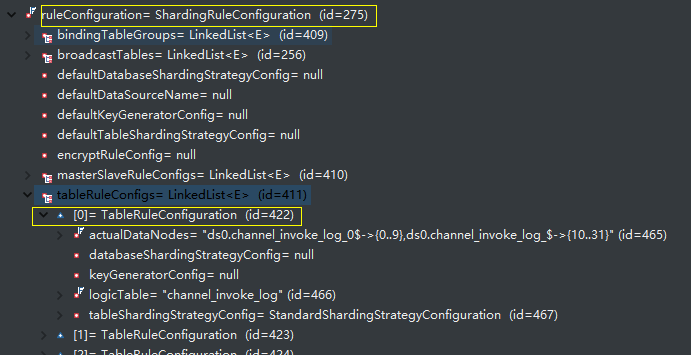
按分片策略路由。
ShardingRuleCondition -> ShardingDataSource -> ShardingPreparedStatement -> ShardingConnection
ShardingRuntimeContext -> ShardingRule -> ShardingRouter#router -
区分读写请求,写走主库,读按负载策略LoadBalanceAlgorithm路由从库。
MasterSlaveRuleCondition -> MasterSlaveDataSource ->MasterSlavePreparedStatement -> MasterSlaveConnection
MasterSlaveRuntimeContext -> MasterSlaveRule -> MasterSlaveRouter#router
2020-03-15 17:24:46.705 [main] INFO [trace=,span=,parent=] ShardingSphere-SQL - Rule Type: sharding
2020-03-15 17:24:46.705 [main] INFO [trace=,span=,parent=] ShardingSphere-SQL - Logic SQL: select * from limit_use u , repayment_plan t where t.loan_no ='LOAN683009630195941376' and u.loan_no = t.loan_no
2020-03-15 17:24:46.705 [main] INFO [trace=,span=,parent=] ShardingSphere-SQL - SQLStatement: SelectSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.SelectStatement@734c98ff, tablesContext=TablesContext(tables=[Table(name=limit_use, alias=Optional.of(u)), Table(name=repayment_plan, alias=Optional.of(t))], schema=Optional.absent())), projectionsContext=ProjectionsContext(startIndex=7, stopIndex=7, distinctRow=false, projections=[ShorthandProjection(owner=Optional.absent())], columnLabels=[id, flow_no, customer_id, customer_name, certificate_no, loan_no, mobile_phone, bank_account_id, bank_account_no, repay_bank_account_id, repay_bank_account_no, contract_no, use_amount, total_periods, term_type, term, channel, loan_type, loan_type_id, repayment_method, due_day, apply_date, accept_date, settle_date, interest_rate, loan_date, interest_start_date, use_status, purpose, trade_channel, trade_status, trade_no, trade_message, business_error_code, reason, version, merge_loan_flag, merge_loan_account, create_time, update_time, id, loan_no, period, should_repayment_date, should_repayment_principal, should_repayment_interest, should_repayment_penalty, should_repayment_fee, actual_repayment_principal, actual_repayment_interest, actual_repayment_penalty, actual_repayment_fee, interest_deduction_amount, penalty_deduction_amount, remaining_principal, is_overdue, actual_repayment_date, repayment_plan_status, grace_days, version, create_time, update_time]), groupByContext=org.apache.shardingsphere.sql.parser.relation.segment.select.groupby.GroupByContext@7a203af7, orderByContext=org.apache.shardingsphere.sql.parser.relation.segment.select.orderby.OrderByContext@360e9b23, paginationContext=org.apache.shardingsphere.sql.parser.relation.segment.select.pagination.PaginationContext@67ee3b1, containsSubquery=false)
2020-03-15 17:24:46.705 [main] INFO [trace=,span=,parent=] ShardingSphere-SQL - Actual SQL: ds0 ::: select * from limit_use_08 u , repayment_plan_08 t where t.loan_no ='LOAN683009630195941376' and u.loan_no = t.loan_noQuery执行过程 ShardingPreparedStatement#executeQuery
下文以4.0.1版本的sharding模式为例 , 4.0.0-RC1 与 4.0.1 版本 在解析sq路由的变动还是挺大的。
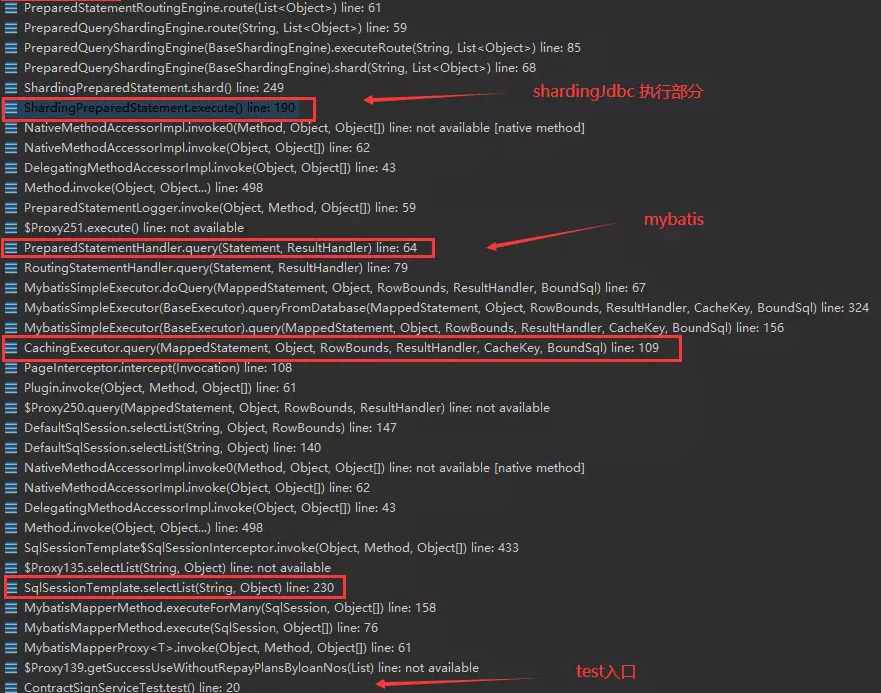
从mybatis执行进入ShardingJdbc逻辑:
"SimpleExecutor -> PreparedStatementHandler -> PreparedStatement " 这个流程里拿到的DataSource、Connection、Statement都是ShardingJdbc的: ShardingDataSource -> ShardingConnection -> ShardingPreparedStatement。
#executeQuery的过程:
- 依据分片规则 和 sql类型 解析确定路由到的具体库&表, 重写sql生成真实的脚本,解析后多个库表会有多个; (ps.对于其他确定是单播的情况只有1个)
- 初始化执行器 PreparedStatementExecutor。 先按数据源分组,以下逻辑前提是在同个数据源下:
- 按 “单次查询最大连接数”规则 再对sql集合分组,该集合size就是需要从该DataSource里拿到有效空闲的Connection数!(分组规则: 按“单次查询最大连接数”划分区间段,sql集合size值落在的区间段序列作为集合切割条数 Lists.partition(sqlUnits, desiredPartitionSize))
- 选择Connect模式:内存限制 CONNECTION_STRICTLY / 连接限制 CONNECTION_STRICTLY 。每一个真实sql表都有一个执行单元StatementExecuteUnit , 它们的分组隶属于ShardingExecuteGroup,内部共用同一连接!
- 如果一个连接需要处理多个sql表,则选择Connect模式的“连接限制” ,此时会使用MemoryQueryResult来封装ResultSet, 将数据行一并读入到内存中!
- 按分组ShardingExecuteGroup执行sql ,同个组内可选 并行parallel 或 串行serial 执行,得到封装sql执行结果集ResultSet的QueryResult。
- 数据结果集归并引擎MergeEngine 会按sql语句规则选择 流式 | 内存 的方式来计算整合得到最终数据ShardingResultSet(MergedResult)。
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious(); // 清除上次执行各处理缓存
shard(); // BaseShardingEngine#shard分片解析出路由sqlRouteResult
initPreparedStatementExecutor(); // 依路由结果初始化各个分库表的执行上下文Statement
// 数据结果集QueryResult,需要选择归并方式
MergeEngine mergeEngine = MergeEngineFactory.newInstance(connection.getRuntimeContext().getDatabaseType(),
connection.getRuntimeContext().getRule(), sqlRouteResult, connection.getRuntimeContext().getMetaData().getRelationMetas(), preparedStatementExecutor.executeQuery());
result = getResultSet(mergeEngine);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
sql路由 PreparedStatementRoutingEngine#route
分片入口: BaseShardingEngine#shard()
public SQLRouteResult shard(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
// 先 PreparedStatementRoutingEngine#route:解析分库分表规则得到sql路由结果SQLRouteResult
SQLRouteResult result = executeRoute(sql, clonedParameters);
// BaseShardingEngine#rewriteAndConvert: 依据SQLRouteResult改写sql成真实的库表。
result.getRouteUnits().addAll(HintManager.isDatabaseShardingOnly() ? convert(sql, clonedParameters, result) : rewriteAndConvert(sql, clonedParameters, result));
boolean showSQL = shardingProperties.getValue(ShardingPropertiesConstant.SQL_SHOW);
if (showSQL) {
boolean showSimple = shardingProperties.getValue(ShardingPropertiesConstant.SQL_SIMPLE);
SQLLogger.logSQL(sql, showSimple, result.getSqlStatementContext(), result.getRouteUnits());
}
return result;
}PreparedStatementRoutingEngine#route
public SQLRouteResult route(final List<Object> parameters) {
if (null == sqlStatement) {
sqlStatement = shardingRouter.parse(logicSQL, true);
}
// 先 分片路由 再 主从库路由。
return masterSlaveRouter.route(shardingRouter.route(logicSQL, parameters, sqlStatement));
}SQLParseEngine#parse 解析sql成语法树 -> ShardingRouter#route() -> RoutingEngine#route() : 按分库分表规则得到真实的库表
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) {
// ShardingStatementValidator.validate 对 insert、update 时 禁止对分表字段更新
Optional<ShardingStatementValidator> shardingStatementValidator = ShardingStatementValidatorFactory.newInstance(sqlStatement);
if (shardingStatementValidator.isPresent()) {
shardingStatementValidator.get().validate(shardingRule, sqlStatement, parameters);
}
SQLStatementContext sqlStatementContext = SQLStatementContextFactory.newInstance(metaData.getRelationMetas(), logicSQL, parameters, sqlStatement);
Optional<GeneratedKey> generatedKey = sqlStatement instanceof InsertStatement
? GeneratedKey.getGenerateKey(shardingRule, metaData.getTables(), parameters, (InsertStatement) sqlStatement) : Optional.<GeneratedKey>absent();
// 入参条件
ShardingConditions shardingConditions = getShardingConditions(parameters, sqlStatementContext, generatedKey.orNull(), metaData.getRelationMetas());
boolean needMergeShardingValues = isNeedMergeShardingValues(sqlStatementContext);
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement && needMergeShardingValues) {
checkSubqueryShardingValues(sqlStatementContext, shardingConditions);
mergeShardingConditions(shardingConditions);
}
RoutingEngine routingEngine = RoutingEngineFactory.newInstance(shardingRule, metaData, sqlStatementContext, shardingConditions);
// 通过条件和分表规则 路由执行
RoutingResult routingResult = routingEngine.route();
if (needMergeShardingValues) {
// 分表子查询时 需要判定RoutingUnits 惟一
Preconditions.checkState(1 == routingResult.getRoutingUnits().size(), "Must have one sharding with subquery.");
}
SQLRouteResult result = new SQLRouteResult(sqlStatementContext, shardingConditions, generatedKey.orNull());
result.setRoutingResult(routingResult);
if (sqlStatementContext instanceof InsertSQLStatementContext) {
setGeneratedValues(result);
}
return result;
}这里重点关注RoutingEngineFactory#newInstance 依据 分片规则和sql执行上下文SQLStatementContext 等创建的不同场景RoutingEngine
public static RoutingEngine newInstance(final ShardingRule shardingRule,
final ShardingSphereMetaData metaData, final SQLStatementContext sqlStatementContext, final ShardingConditions shardingConditions) {
SQLStatement sqlStatement = sqlStatementContext.getSqlStatement();
Collection<String> tableNames = sqlStatementContext.getTablesContext().getTableNames();
if (sqlStatement instanceof TCLStatement) {
//授权、角色控制等数据库控制语言: 全库路由, 基于每个DataSourceName构建一个RoutingUnit
return new DatabaseBroadcastRoutingEngine(shardingRule);
}
if (sqlStatement instanceof DDLStatement) {
//数据定义语言:全库表路由
return new TableBroadcastRoutingEngine(shardingRule, metaData.getTables(), sqlStatementContext);
}
if (sqlStatement instanceof DALStatement) {
return getDALRoutingEngine(shardingRule, sqlStatement, tableNames);
}
if (sqlStatement instanceof DCLStatement) {
return getDCLRoutingEngine(shardingRule, sqlStatementContext, metaData);
}
if (shardingRule.isAllInDefaultDataSource(tableNames)) {
// 默认的数据库
return new DefaultDatabaseRoutingEngine(shardingRule, tableNames);
}
if (shardingRule.isAllBroadcastTables(tableNames)) {
// UnicastRoutingEngine 代表单播路由,它只需要从任意库中的任意真实表中获取数据即可。
// 例如 DESCRIBE 语句就适合使用 UnicastRoutingEngine,因为每个真实表中的数据描述结构都是相同的。
return sqlStatement instanceof SelectStatement ? new UnicastRoutingEngine(shardingRule, tableNames) : new DatabaseBroadcastRoutingEngine(shardingRule);
}
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement && tableNames.isEmpty() && shardingRule.hasDefaultDataSourceName()) {
return new DefaultDatabaseRoutingEngine(shardingRule, tableNames);
}
if (sqlStatementContext.getSqlStatement() instanceof DMLStatement && shardingConditions.isAlwaysFalse() || tableNames.isEmpty() || !shardingRule.tableRuleExists(tableNames)) {
return new UnicastRoutingEngine(shardingRule, tableNames);
}
return getShardingRoutingEngine(shardingRule, sqlStatementContext, shardingConditions, tableNames); // StandardRoutingEngine(单个表或者有绑定关系的多个表) 或 ComplexRoutingEngine
}ShardingRule#isAllInDefaultDataSource:对于不分片的表,会判定是否有默认的数据库配置。
// 有默认数据库 && 没有路由规则 && 不是广播表 && 有表名
public boolean isAllInDefaultDataSource(final Collection<String> logicTableNames) {
if (!hasDefaultDataSourceName()) {
return false;
}
for (String each : logicTableNames) {
if (findTableRule(each).isPresent() || isBroadcastTable(each)) {
return false;
}
}
return !logicTableNames.isEmpty();
}ShardingDataSourceNames#getDefaultDataSourceName : 只有1个数据库时它就是默认
// 只有1个数据库,则它就是默认;否则取配置的default
public String getDefaultDataSourceName() {
return 1 == dataSourceNames.size() ? dataSourceNames.iterator().next() : shardingRuleConfig.getDefaultDataSourceName();
}StandardRoutingEngine#route() -> #getDataNodes:
private Collection<DataNode> getDataNodes(final TableRule tableRule) {
if (isRoutingByHint(tableRule)) {
// 先判定指定datebase和table都是Hint路由策略!
return routeByHint(tableRule);
}
if (isRoutingByShardingConditions(tableRule)) {
// datebase和table都不是Hint策略
return routeByShardingConditions(tableRule);
}
return routeByMixedConditions(tableRule);
}StandardRoutingEngine#routeByShardingConditions -> #routeTables:
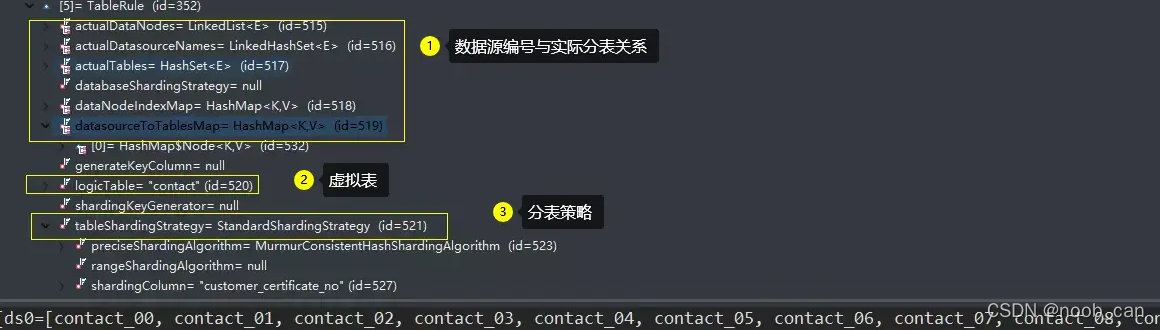
根据配置的分片规则获取指定的算法ShardingStrategy来计算出路由的实际的分库及分表序列

分片策略 ShardingStrategy
- StandardShardingStrategy#doSharding (单字段): 只取RouteValue 集合中的第一个值作为判定依据
- ComplexShardingStrategy#doSharding (混合字段): 当ListRouteValue传入的需要计算分片规则的数据值有N个就会计算N次分表,通过TreeSet去重
... 其他策略不深入了
public final class ListRouteValue<T extends Comparable<?>> implements RouteValue {
private final String columnName; // 表字段
private final String tableName; // 表
private final Collection<T> values; // 字段入参值数据结果集的归并 MergeEngine
 https://blog.youkuaiyun.com/shardingsphere/article/details/99316821?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-1-99316821-blog-120070807.pc_relevant_eslanding_v1&spm=1001.2101.3001.4242.2&utm_relevant_index=4
https://blog.youkuaiyun.com/shardingsphere/article/details/99316821?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-1-99316821-blog-120070807.pc_relevant_eslanding_v1&spm=1001.2101.3001.4242.2&utm_relevant_index=4package org.apache.shardingsphere.sharding.merge;
public final class MergeEngineFactory {
/**
* Create merge engine instance.
*
* @param databaseType database type
* @param shardingRule sharding rule 分片规则
* @param routeResult SQL route result sql路由结果
* @param relationMetas relation metas
* @param queryResults query results 查询结果集
* @return merge engine instance
*/
public static MergeEngine newInstance(final DatabaseType databaseType, final ShardingRule shardingRule,
final SQLRouteResult routeResult, final RelationMetas relationMetas, final List<QueryResult> queryResults) {
if (routeResult.getSqlStatementContext() instanceof SelectSQLStatementContext) {
return new DQLMergeEngine(databaseType, (SelectSQLStatementContext) routeResult.getSqlStatementContext(), queryResults);
}
if (routeResult.getSqlStatementContext().getSqlStatement() instanceof DALStatement) {
return new DALMergeEngine(shardingRule, queryResults, routeResult.getSqlStatementContext(), relationMetas);
}
return new TransparentMergeEngine(queryResults);
}这里拿查询语句的 DQLMergeEngine#merge() -> #build来分析。
public MergedResult merge() throws SQLException {
if (1 == queryResults.size()) {
// 如果只有一个归并的结果集,使用了IteratorStreamMergedResult流式归并。
return new IteratorStreamMergedResult(queryResults);
}
Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));
selectSQLStatementContext.setIndexes(columnLabelIndexMap);
return decorate(build(columnLabelIndexMap));
}
// 在不同的ordrBy\ groupBy\Distinct 场景下选择哪种MergedResult
private MergedResult build(final Map<String, Integer> columnLabelIndexMap) throws SQLException {
if (isNeedProcessGroupBy()) {
// 优先判定了GroupBy
return getGroupByMergedResult(columnLabelIndexMap);
}
if (isNeedProcessDistinctRow()) {
setGroupByForDistinctRow();
return getGroupByMergedResult(columnLabelIndexMap);
}
if (isNeedProcessOrderBy()) {
// 如果只有orderby 选择StreamMergedResult
return new OrderByStreamMergedResult(queryResults, selectSQLStatementContext.getOrderByContext().getItems());
}
return new IteratorStreamMergedResult(queryResults);
}
private MergedResult getGroupByMergedResult(final Map<String, Integer> columnLabelIndexMap) throws SQLException {
// sql的排序项 order by与分组项 group by 的字段以及排序类型(ASC或DESC)保持一致时选择StreamMergedResult
return selectSQLStatementContext.isSameGroupByAndOrderByItems()
? new GroupByStreamMergedResult(columnLabelIndexMap, queryResults, selectSQLStatementContext)
: new GroupByMemoryMergedResult(queryResults, selectSQLStatementContext);
}- MemoryMergedResult 内存归并 需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算整合。

- StreamMergedResult 流式归并 要求sql的排序项 order by与分组项 group by 的字段以及排序类型(ASC或DESC)必须保持一致! 每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据。相当于归并算法!

在OrderByStreamMergedResult里:
有一个优先级队列‘PriorityQueue orderByValuesQueue’ 用来对每个结果集QueryResult单次下翻<#next()>后返回的单条数据实时排序。 MergedResult#next() 和 MergedResult#getValue 配合操作QueryResult完成归并。
public class OrderByStreamMergedResult extends StreamMergedResult {
private final Collection<OrderByItem> orderByItems;
@Getter(AccessLevel.PROTECTED)
private final Queue<OrderByValue> orderByValuesQueue;
@Getter(AccessLevel.PROTECTED)
private boolean isFirstNext;
public OrderByStreamMergedResult(final List<QueryResult> queryResults, final Collection<OrderByItem> orderByItems) throws SQLException {
this.orderByItems = orderByItems;
this.orderByValuesQueue = new PriorityQueue<>(queryResults.size());
orderResultSetsToQueue(queryResults);
isFirstNext = true;
}
...
// 下翻
public boolean next() throws SQLException {
if (orderByValuesQueue.isEmpty()) {
return false;
}
if (isFirstNext) {
isFirstNext = false;
return true;
}
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
if (firstOrderByValue.next()) { // 这里最终是QueryResult.next()
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
setCurrentQueryResult(orderByValuesQueue.peek().getQueryResult());
return true;
}
}Jdbc的数据结果集ResultSet
这里解释下ResultSet#next():将指针移动到当前位置的下一行。
ResultSet 指针的初始位置位于第一行之前。每调用一次next(),指针后移一位;当next()方法返回 false,表示指针位于最后一行之后,如果再调用next()就会出现异常。只有记录指针不断next后移才能不断依次取出nextRow。
非流式查询ResultsetRowsStatic
默认使用!会提前while循环从数据库IO读出所有rows来缓存到程序内存中。 如果查询数据量过大会导致内存占用溢出!
流式查询ResultsetRowsStreaming
流式查询的好处是能够避免数据量过大导致 OOM。
查询成功后不是返回一个集合而是返回一个迭代器,应用每次#next()发起一次对数据库的IO读来拿下一行数据。
当客户端向MySQL_Server端发起查询时,MySQL_Server会通过输出流将 SQL 结果集返回输出,也就是向本地的内核对应的 Socket_Buffer 中写入数据,然后将内核中的数据通过 TCP 链路回传数据到 JDBC 对应的服务器内核缓冲区。
-
JDBC的inputStream#read()方法会去读取内核缓冲区数据,每次只是从内核中读取一个package大小的数据,只是返回一行数据,如果1个package无法组装1行数据,会再读1个package。
-
MySQL_Server会向 JDBC 代表的客户端内核源源不断的输送数据,直到客户端请求 Socket 缓冲区满,这时的 MySQL_Server会阻塞。
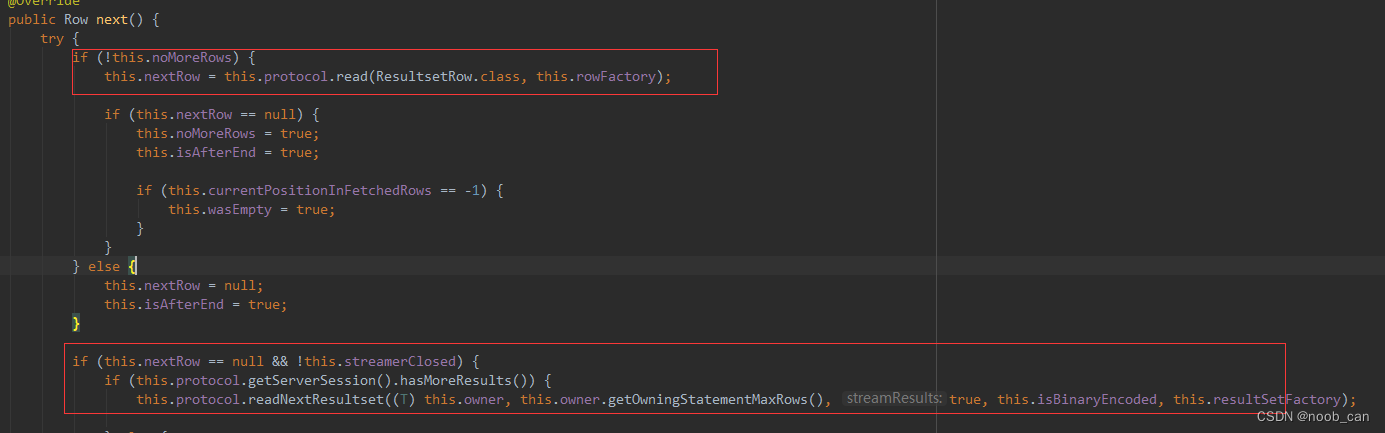
ResultSet 对象的类型:
- ResultSet.TYPE_FORWARD_ONLY 只能向前滚动
- ResultSet.TYPE_SCROLL_INSENSITIVE 和 Result.TYPE_SCROLL_SENSITIVE 这两个方法都能够实现任意的前后滚动,使用各种移动的 ResultSet 指针的方法。二者的区别在于前者对于修改不敏感,而后者对于修改敏感。

游标查询ResultsetRowsCursor
MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable (可关闭)和 java.lang.Iterable(可遍历) 接口。
ResultsetRowsCursor 内部维护了一个集合‘List<Row> fetchedRows’来保存每次从数据库IO读来的指定'fetchSize'数量的批次数据,直到该批次被程序#next()读出完毕开始下一批次读取。
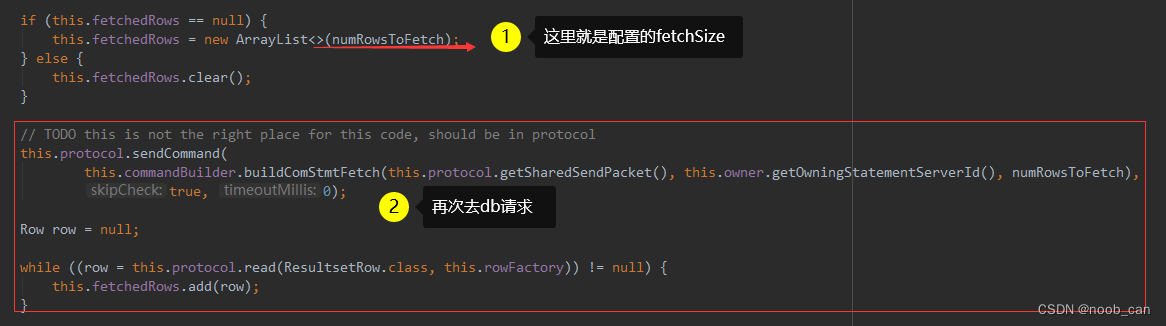
需要在数据库连接信息里拼接参数useCursorFetch=true 且 FetchSize > 0 :
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/mysql-demo?useCursorFetch=true", "root", "123456");
String sql = "select * from t_loan limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true)
// 设置流式查询参数。 普通查询直接 stmt = conn.prepareStatement(sql);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
rs.close();
}流式查询的弊端
采用游标查询的方式的缺点很明显。
流式(游标)查询需要注意:当前查询会独占连接!必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常!执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后需要自己关闭。
由于MySQL_Server不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL_Server需要建立一个临时空间来存放需要拿走的数据。
因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
- IOPS 飙升,因为需要返回的数据需要写入到临时空间中,存在大量的 IO 读取和写入,此流程可能会引起其它业务的写入抖动
- 磁盘空间飙升,写入临时空间的数据会在读取完成或客户端发起 ResultSet#close 操作时由 MySQL_Server 回收
- 客户端 JDBC 发起sql_query,可能会有长时间等待,这段时间为MySQL_Server准备数据阶段。但是 普通查询等待时间与游标查询等待时间原理上是不一致的: 前者是在读取网络缓冲区的数据,没有响应到业务层面;后者是 MySQL 在准备临时数据空间,没有响应到 JDBC
- 数据准备完成后,进行到传输数据阶段,网络响应开始飙升,IOPS 由"写"转变为"读"
数据结果集 QueryResult
ConnectionMode 的两种模式:
- 内存限制(MEMORY_STRICTLY): 采用流式处理StreamQueryResult,依次操作ResultSet#next()
- 连接限制(CONNECTION_STRICTLY) : 采用MemoryQueryResult,在实例化阶段就会一次性循环操作ResultSet#next()将数据库返回的所有数据行都读入内存。
针对于每一个数据源下: 当配置的maxConnectionsSizePerQuery(默认1)小于 解析到真实表个数时 (一个连接需要处理多个表) 会选择该模式!(因为流式查询需要独占连接)

它们的区别是:
- 流式: StreamQueryResult#next() 是直接操作ResultSet#next()
- 内存: MemoryQueryResult在实例化创建时就会提前循环迭代处理ResultSet,缓存了所有数据行。当调用#next()方法时使用的是该集合缓存的迭代器#next()
public final class MemoryQueryResult implements QueryResult {
private final ResultSetMetaData resultSetMetaData;
private final Iterator<List<Object>> rows; // 总数据的迭代器
private List<Object> currentRow;
public MemoryQueryResult(final ResultSet resultSet) throws SQLException {
resultSetMetaData = resultSet.getMetaData();
rows = getRows(resultSet); // 实例化时直接迭代处理ResultSet缓存全部数据
}
private Iterator<List<Object>> getRows(final ResultSet resultSet) throws SQLException {
Collection<List<Object>> result = new LinkedList<>();
while (resultSet.next()) {
List<Object> rowData = new ArrayList<>(resultSet.getMetaData().getColumnCount());
for (int columnIndex = 1; columnIndex <= resultSet.getMetaData().getColumnCount(); columnIndex++) {
Object rowValue = getRowValue(resultSet, columnIndex);
rowData.add(resultSet.wasNull() ? null : rowValue);
}
result.add(rowData);
}
return result.iterator();
}
-----
public final class StreamQueryResult implements QueryResult {
private final ResultSetMetaData resultSetMetaData;
private final ResultSet resultSet;
public StreamQueryResult(final ResultSet resultSet) throws SQLException {
resultSetMetaData = resultSet.getMetaData();
this.resultSet = resultSet;
}
@Override
public boolean next() throws SQLException {
return resultSet.next();
}如何选择QueryResult类型
public final class RouteUnit {
private final String dataSourceName; // 数据源
private final SQLUnit sqlUnit; // 重写后的真实sql和入参关系
}
public final class SQLUnit {
private final String sql;
private final List<Object> parameters;
}SQLRouteResult里有保存路由的实际库表信息对象RouteUnit的集合。
RoutingResult:
[RoutingUnit(dataSourceName=ds0, masterSlaveLogicDataSourceName=ds0, tableUnits=[TableUnit(logicTableName=limit_use, actualTableName=limit_use_08), TableUnit(logicTableName=repayment_plan, actualTableName=repayment_plan_08)]),
RoutingUnit(dataSourceName=ds0, masterSlaveLogicDataSourceName=ds0, tableUnits=[TableUnit(logicTableName=limit_use, actualTableName=limit_use_00), TableUnit(logicTableName=repayment_plan, actualTableName=repayment_plan_08)])]当线程执行到初始化PreparedStatementExecutor过程:
ShardingPreparedStatement#executeQuery() -> [ #initPreparedStatementExecutor -> PreparedStatementExecutor#init -> #obtainExecuteGroups -> SQLExecutePrepareTemplate#getSynchronizedExecuteUnitGroups -> #getSQLExecuteGroups ]
private Collection<ShardingExecuteGroup<StatementExecuteUnit>> getSynchronizedExecuteUnitGroups(
final Collection<RouteUnit> routeUnits, final SQLExecutePrepareCallback callback) throws SQLException {
// 按dataSource库分组
Map<String, List<SQLUnit>> sqlUnitGroups = getSQLUnitGroups(routeUnits);
Collection<ShardingExecuteGroup<StatementExecuteUnit>> result = new LinkedList<>();
for (Entry<String, List<SQLUnit>> entry : sqlUnitGroups.entrySet()) {
result.addAll(getSQLExecuteGroups(entry.getKey(), entry.getValue(), callback));
}
return result;
}
// 把库表信息RouteUnit集合按数据源DataSourceName分组
private Map<String, List<SQLUnit>> getSQLUnitGroups(final Collection<RouteUnit> routeUnits) {
Map<String, List<SQLUnit>> result = new LinkedHashMap<>(routeUnits.size(), 1);
for (RouteUnit each : routeUnits) {
if (!result.containsKey(each.getDataSourceName())) {
result.put(each.getDataSourceName(), new LinkedList<SQLUnit>());
}
result.get(each.getDataSourceName()).add(each.getSqlUnit());
}
return result;
}
private List<ShardingExecuteGroup<StatementExecuteUnit>> getSQLExecuteGroups(final String dataSourceName,
final List<SQLUnit> sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException {
List<ShardingExecuteGroup<StatementExecuteUnit>> result = new LinkedList<>();
//按maxConnectionsSizePerQuery计算出多少个表分成同组。
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
// 分组最终的个数就是拿Connection的个数
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
// maxConnectionsSizePerQuery(单次查询最大连接数)< sql数量 ,使用CONNECTION_STRICTLY连接限制。
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
for (List<SQLUnit> each : sqlUnitPartitions) {
// 同一数据源内的多个表的操作可能是会共用一个连接
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
}
private ShardingExecuteGroup<StatementExecuteUnit> getSQLExecuteGroup(final ConnectionMode connectionMode, final Connection connection,
final String dataSourceName, final List<SQLUnit> sqlUnitGroup, final SQLExecutePrepareCallback callback) throws SQLException {
List<StatementExecuteUnit> result = new LinkedList<>();
for (SQLUnit each : sqlUnitGroup) {
// 分组内每个SQLUnit 都对应一个执行单元StatementExecuteUnit, 但connection是共用的
result.add(callback.createStatementExecuteUnit(connection, new RouteUnit(dataSourceName, each), connectionMode));
}
return new ShardingExecuteGroup<>(result);
}
- 将sqlRouteResult内的库表路由信息RouteUnit集合按数据源分组。
- 单个数据源DataSource内:
- 如果有多个表SQLUnit需要访问,依单次查询最大连接数maxConnectionsSizePerQuery,按规则计算得到单个分组的数据量阈值, 给SQLUnit集合按数量切分,同组内的SQLUnit会共用同一个连接。有N个组就从该DataSource里拿N个Connection ;
- maxConnectionsSizePerQuery < SQLUnit总量 (也就是说: 一个连接处理多个表),则选择 ConnectionMode.CONNECTION_STRICTLY 连接限制,否则是 ConnectionMode.MEMORY_STRICTLY 内存限制。
- 每个SQLUnit 都对应一个执行单元StatementExecuteUnit, 它们隶属于同一组ShardingExecuteGroup,connection共用。
// ShardingPropertiesConstant: MAX_CONNECTIONS_SIZE_PER_QUERY("max.connections.size.per.query", String.valueOf(1), int.class),
当线程在 ShardingPreparedStatement#executeQuery() 里, ShardingPreparedStatement#initPreparedStatementExecutor() 执行器初始完成后的逻辑
[ PreparedStatementExecutor#executeQuery() -> #executeCallback ->ShardingExecuteEngine#groupExecute ] :将前述过程里分组后的多个ShardingExecuteGroup依次执行处理。ShardingExecuteGroup内部可选 并行 或 串行 执行 <ShardingConnection#isHoldTransaction() 持有事务选择serial>。
SqlExecuteTemplate 执行 StatementExecuteUnit 会回调 SQLExecuteCallback#executeSQL 方法,最终调用 PreparedStatementExecutor#getQueryResult 方法。
// PreparedStatementExecutor执行
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
return getQueryResult(statement, connectionMode);
}
};
return executeCallback(executeCallback);
}
private QueryResult getQueryResult(final Statement statement, final ConnectionMode connectionMode) throws SQLException {
PreparedStatement preparedStatement = (PreparedStatement) statement;
ResultSet resultSet = preparedStatement.executeQuery();
getResultSets().add(resultSet);
return ConnectionMode.MEMORY_STRICTLY == connectionMode ? new StreamQueryResult(resultSet) : new MemoryQueryResult(resultSet);
}

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









