 Java线程池ThreadPoolExecutor详解与并发安全
Java线程池ThreadPoolExecutor详解与并发安全





 本文深入探讨了Java中的ThreadPoolExecutor线程池的原理与使用,包括核心线程数、最大线程数、阻塞队列、拒绝策略等配置参数。讲解了任务执行流程、线程池停止策略以及ExecutorCompletionService的使用,同时分析了FutureTask的并发安全性。文章强调了线程池在保证并发安全和资源管理上的重要性,以及如何确保任务的正确执行和线程池的高效运行。
本文深入探讨了Java中的ThreadPoolExecutor线程池的原理与使用,包括核心线程数、最大线程数、阻塞队列、拒绝策略等配置参数。讲解了任务执行流程、线程池停止策略以及ExecutorCompletionService的使用,同时分析了FutureTask的并发安全性。文章强调了线程池在保证并发安全和资源管理上的重要性,以及如何确保任务的正确执行和线程池的高效运行。
目录
ThreadPoolExecutor线程池
可控有序创建、销毁线程,复用线程上下文。
- 因操作系统资源有限, 避免Cpu<时间片调度要切换不同的线程上下文;top查看Cpu%的 sy >、内存 等资源被耗尽;
- 创建、销毁线程也需要时间,当占用内存过多,引起JVM的GC停顿。
创建时需要指定的参数:
| corePoolSize | 核心线程数 |
| maximumPoolSize | 最大线程数 |
| keepAliveTime + unit | 超过核心线程数的临时线程持续时间 |
| BlockingQueue | 阻塞队列,保证并发读写安全 |
| ThreadFactory | 创建Worker工作线程的工厂类 |
| RejectedExecutionHandler | 队列已满且无法再新增临时线程时,拒绝策略 |
使用时要考究:
- 确定线程数 和 临时线程的持续时间。
- Cpu核数 * ( 1 + wait_time / cpu_time) 。 Cpu密集型: Cpu核数 ; IO密集型: 2 * Cpu核数; Runtime.getRuntime().availableProcessors()
- 操作系统对于能创建的线程栈大小、个数都有限制,过多的线程会挤占Cpu、内存资源。( ulimit -a : max user processes 、stack size ; JVM : -Xss)
- 确定阻塞队列的类型和容量。 如果是无界的(eg. LinkedBlockingQueue),当任务大量积压时会挤占内存。
确定拒绝策略。在关键场景下如何保证数据不丢失是很重要的!
任务的执行顺序和提交顺序可能会不一致!
eg. 任务A先进了阻塞队列,任务B因阻塞队列满了而创建了临时线程反而会首先处理;如果有先后依赖关系,那任务B的处理线程Worker就需要阻塞等待。
所以任务尽可能不要有先后依赖关系,且不要做耗时过长的操作, 这样后续任务就不会阻塞太久。
Executors工具类提供了不限于以下几种创建线程池的方法:
public class Executors {
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}停止线程池
- #shutdown : 设置线程池状态为SHUTDOWN 。
- #shutdownNow : 设置线程池状态为STOP, 移除阻塞队列的task 。
它俩都会遍历每一个Worker执行 Thread#interrupt() 来发起中断,只在线程阻塞时才响应中断信号 。#execute方法内判定线程池处在这两种状态时是无法新提交task的。
任务执行
任务提交有2种方式
- void ThreadPoolExecutor#execute(Runnable command)
- Future<?> AbstractExecutorService#submit :抽象父类提供的方法。入参可以是Runnable、Callable ,会被封装为FutureTask对象去执行方法#execute ,返回的就是该FutureTask
#execute(Runnable command)
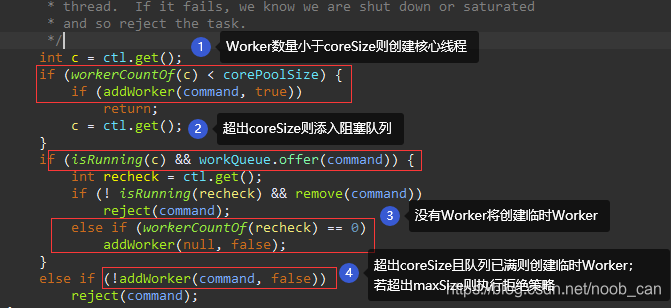
当一个新任务提交到线程池里,内部执行优先顺序是:
- 创建核心线程(满) → 添入阻塞队列(满) → 创建最大临时线程(满) → 拒绝策略; 在初次创建Worker时一般是会指定'firstTask'为传入的Runnable。
- 而当核心线程数为0时, 添入阻塞队列后判定【当前池内线程数为0 】则创建一个临时线程worker从阻塞队列中拿任务执行;这种情况'firstTask'就为空。
工作线程Worker
Worker#run() -> ThreadPoolExecutor#runWorker(Worker w) : 优先处理初始化时指定的firstTask,再从阻塞队列里拿任务处理。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 优先处理firstTask, 再从阻塞队列里拿
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted; if not, ensure thread is not interrupted.
// This requires a recheck in second case to deal with shutdownNow race while clearing interrupt
if ( (runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted() )
wt.interrupt(); // 再次检测STOP状态下发起interrupt
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false; // 正常执行下拿到task为空
} finally {
//break出循环后删除线程
processWorkerExit(w, completedAbruptly);
}
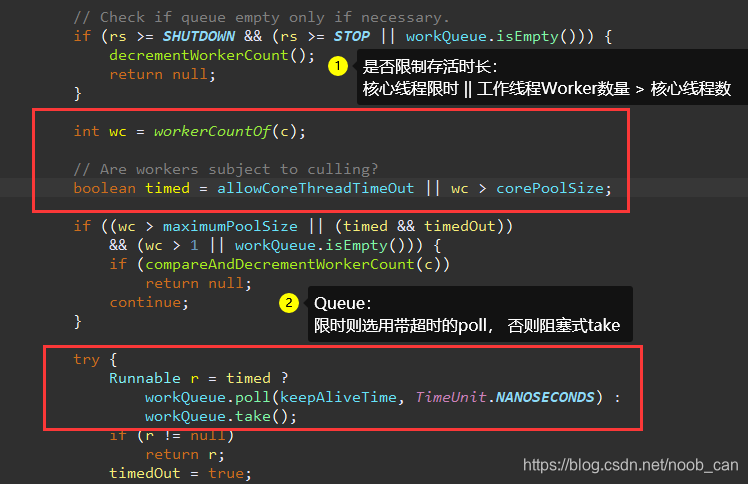
}- 判定【活跃线程数已经超过了核心线程数】,则使用阻塞队列提供的带超时阻塞方式workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)来获取,否则使用take()一直阻塞。 见: ThreadPoolExecutor#getTask()
- 当阻塞超时后仍没有获取到任务,则从线程池的Worker列表里删除当前Worker, Worker计数减一。 见: ThreadPoolExecutor#processWorkerExit
方法ThreadPoolExecutor#runWorker里,标记“completedAbruptly”:
- 工作线程正常执行未发生异常:当前线程总数超过了CoreSize,那阻塞获取超时后返回的任务就为空,此时跳出循环逻辑;此时“completedAbruptly” 为 false。
- 工作线程发生执行异常:“completedAbruptly” 为 true。
执行进入ThreadPoolExecutor#processWorkerExit 方法:
- completedAbruptly == true :先将worker计数 CAS 减一;
- 从worker列表里删除该worker;
- completedAbruptly == false: 判定小于核心线程数会新增一个线程。 即使coreSize设置为0,队列里还有未处理任务,会维持1个有效的工作线程Worker。
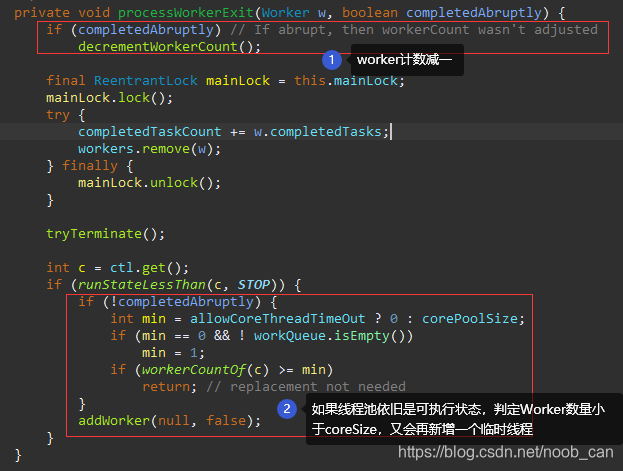
此处的addWorker方法传入的“core”是false, 但线程池对核心线程池的判定逻辑不取决于它。只是为了并发时超出了coreSize也能够新增一个线程
ExecutorCompletionService
构建时,要注意BlockingQueue的容量不能小于提交的任务数。
public class ExecutorCompletionService<V> implements CompletionService<V> {
private final Executor executor;
private final AbstractExecutorService aes;
private final BlockingQueue<Future<V>> completionQueue; // FutureTask执行完毕队列
public Future<V> submit(Callable<V> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
executor.execute(new QueueingFuture(f));
return f;
}
public Future<V> take() throws InterruptedException {
return completionQueue.take();
}
public Future<V> poll() {
return completionQueue.poll();
}
public Future<V> poll(long timeout, TimeUnit unit)
throws InterruptedException {
return completionQueue.poll(timeout, unit);
}- ExecutorCompletionService#submit 方法将Callable | Runnable 封装成FutureTask后,又再包裹了一层QueueingFuture。当FutureTask执行完毕后,会放入到完成队列completionQueue里。
- ExecutorCompletionService#take() 可以阻塞式从completionQueue拿到执行结束的FutureTask。
FutureTask
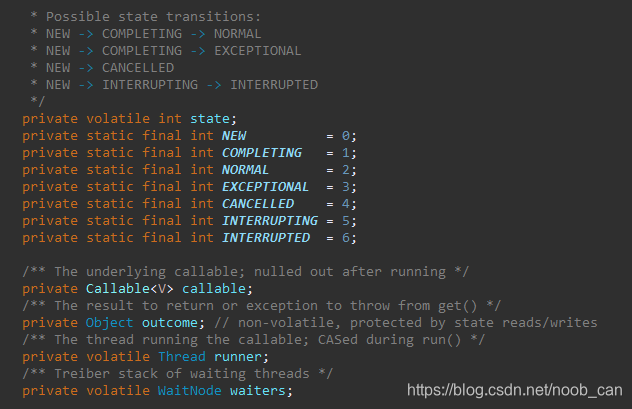
Unsafe.CAS方式保证原子性处理:
- 内部volatile变量“state”值的变化 , 用来记录 Callable 执行状态, 刚创建时是 NEW。
- 等待线程节点链“waiters”的新增、删除、查找 操作。
先 FutureTask#run()
首先
CAS绑定“runner”为当前线程。执行Callable.call()
正常执行:得到result后设置给 outcome, "state"状态从 NEW 设置成 COMPLETING ;
发生异常: 将异常Throwable设置给outcome , "state"状态设置成 EXCEPTIONAL;
执行完成后,循环判定:还有挂起等待状态的线程在链“waiters”上,则
CAS方式清空该链,并逐个LockSupport#unpark唤醒节点线程。
后 FutureTask#get()
判定当前"state"状态标识:
还未有结果,则将当前线程封装为WaitNode,以
CAS方式 “前插” 到单向链“waiters”里,并LockSupport#park 挂起线程。有结果时
判定"state"状态是NORMAL, 则直接返回正常结果;
异常结果则将Throwable包装成ExecutionException并抛出。
主要逻辑源码:
// 执行Callable.call() 完成后,唤醒等待线程
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) { // 循环判定等待链存在节点,就去cas清空它
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
// 逐个唤醒
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
// get()时挂起等待结果
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q); // 前插
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}如何保证并发安全的?
- 等待链头“waiters” 是被
volatile修饰的。 - get()时 等待线程节点插入链是“前插” ,执行Callable完成后finishCompletion()过程里是循环判定【还有挂起等待的线程在链上,就
CAS清空 】。两种场景下都是:只有当 UNSAFE#compareAndSwapObject 对等待链的头节点CAS操作成功后,才会继续向下处理。所以如果发生并发,必定有一个CAS是不成功的,就会重新volatile获取 “waiters” 再来判定处理。 - 方法awaitDone里会优先判定FutureTask执行状态,若已经执行结束了,此时再有线程执行get()方法会直接返回状态“state”。
未完,待续。。。

















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









