import os
import torch
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import numpy as np
from transformers import MT5TokenizerFast, MT5ForConditionalGeneration
from sklearn.metrics import accuracy_score
from qa_datasets import train_data, test_data
import warnings
warnings.filterwarnings('ignore')
# -------------------------- 1. 全局配置(任务范式重构) --------------------------
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"✅ 运行设备:{device}")
# 网络加载配置(国内镜像加速)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
MODEL_NAME = "google/mt5-small"
# 超参数(小数据集专用优化)
MAX_INPUT_LEN = 128
MAX_OUTPUT_LEN = 32
BATCH_SIZE = 1
EPOCHS = 60 # 延长训练轮次,强制任务迁移
LEARNING_RATE = 5e-7 # 极小学习率,避免参数震荡
GRADIENT_ACCUMULATION_STEPS = 8 # 模拟batch=8,增强训练稳定性
MIN_GENERATE_LENGTH = 2
# -------------------------- 2. 数据集类(彻底脱离填充任务格式) --------------------------
class QADataset(Dataset):
def __init__(self, data, tokenizer, max_input_len, max_output_len):
self.data = data
self.tokenizer = tokenizer
self.max_input_len = max_input_len
self.max_output_len = max_output_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
# 核心修改:输入格式改为“问答提取”范式,完全脱离填充任务
# 格式:[问答] 问题? 上下文。 答案:
input_text = f"[问答] {item['question']}? {item['context']}。 答案:"
target_text = item['answer']
# 编码优化:确保输入无特殊符号干扰
input_encoding = self.tokenizer(
input_text,
max_length=self.max_input_len,
padding='max_length',
truncation=True,
return_tensors='pt',
add_special_tokens=True
)
target_encoding = self.tokenizer(
target_text,
max_length=self.max_output_len,
padding='max_length',
truncation=True,
return_tensors='pt',
add_special_tokens=False # 答案仅保留纯文本
)
input_ids = input_encoding['input_ids'].flatten()
attention_mask = input_encoding['attention_mask'].flatten()
target_ids = target_encoding['input_ids'].flatten()
# 标签处理:强化填充符屏蔽
labels = target_ids.clone()
pad_token_id = self.tokenizer.pad_token_id
labels[labels == pad_token_id] = -100
return {
'input_ids': input_ids,
'attention_mask': attention_mask,
'labels': labels
}
# -------------------------- 3. 训练与测试函数(禁用填充token生成) --------------------------
def train_epoch(model, loader, optimizer, device, accumulation_steps):
model.train()
total_loss = 0.0
optimizer.zero_grad()
for batch_idx, batch in enumerate(loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss / accumulation_steps
loss.backward()
# 梯度裁剪+梯度累积,双重稳定训练
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=0.5)
if (batch_idx + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item() * accumulation_steps
return total_loss / len(loader)
def get_bad_words_ids(tokenizer):
"""获取`<extra_id_*>`的token ID,禁止生成这些填充token"""
bad_words_ids = []
# MT5的填充token从<extra_id_0>到<extra_id_99>,遍历生成其ID
for i in range(100):
extra_token = f"<extra_id_{i}>"
if extra_token in tokenizer.get_vocab():
bad_words_ids.append([tokenizer.convert_tokens_to_ids(extra_token)])
return bad_words_ids
def evaluate(model, tokenizer, device, test_data):
model.eval()
all_preds = []
all_trues = []
bad_words_ids = get_bad_words_ids(tokenizer) # 禁用填充token
with torch.no_grad():
for item in test_data:
input_text = f"[问答] {item['question']}? {item['context']}。 答案:"
input_encoding = tokenizer(
input_text,
max_length=MAX_INPUT_LEN,
padding='max_length',
truncation=True,
return_tensors='pt'
).to(device)
# 生成策略核心优化:禁止生成`<extra_id_*>`
generated_ids = model.generate(
input_ids=input_encoding['input_ids'],
attention_mask=input_encoding['attention_mask'],
max_length=MAX_OUTPUT_LEN,
min_length=MIN_GENERATE_LENGTH,
num_beams=10, # 进一步增加束搜索,提升正确答案概率
early_stopping=True,
no_repeat_ngram_size=2,
decoder_start_token_id=tokenizer.eos_token_id,
temperature=0.3, # 极低温度,强制模型输出高置信度答案
top_p=0.8,
remove_invalid_values=True,
bad_words_ids=bad_words_ids # 关键:禁止生成填充token
)
# 解码+清理
pred_answer = tokenizer.decode(
generated_ids[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
).strip()
# 兜底处理
if not pred_answer or pred_answer.isspace():
pred_answer = "未识别到答案"
true_answer = item['answer'].strip()
all_preds.append(pred_answer)
all_trues.append(true_answer)
# 计算准确率+部分匹配率(小数据集更合理)
exact_acc = sum([1 for p, t in zip(all_preds, all_trues) if p == t]) / len(all_trues)
partial_acc = sum([1 for p, t in zip(all_preds, all_trues) if p in t or t in p]) / len(all_trues)
return exact_acc, partial_acc, all_preds, all_trues
# -------------------------- 4. Attention可视化函数 --------------------------
def visualize_t5_attention(
model, tokenizer, question, context, device,
layer_idx=5, head_idx=0, save_path="t5_qa_attention.png"
):
input_text = f"[问答] {question}? {context}。 答案:"
encoder_encoding = tokenizer(
input_text,
max_length=MAX_INPUT_LEN,
padding='max_length',
truncation=True,
return_tensors='pt'
).to(device)
decoder_start_token_id = tokenizer.eos_token_id
decoder_input_ids = torch.tensor([[decoder_start_token_id]]).to(device)
outputs = model(
input_ids=encoder_encoding['input_ids'],
attention_mask=encoder_encoding['attention_mask'],
decoder_input_ids=decoder_input_ids,
output_attentions=True
)
cross_attentions = outputs.cross_attentions[layer_idx][0][head_idx].cpu().detach().numpy()
encoder_tokens = tokenizer.convert_ids_to_tokens(encoder_encoding['input_ids'][0].cpu().numpy())
decoder_tokens = tokenizer.convert_ids_to_tokens(decoder_input_ids[0].cpu().numpy())
valid_encoder_tokens = [t for t in encoder_tokens if t not in [tokenizer.pad_token, tokenizer.unk_token]]
valid_decoder_tokens = [t for t in decoder_tokens if t not in [tokenizer.pad_token, tokenizer.unk_token]]
attention_weights = cross_attentions[:len(valid_decoder_tokens), :len(valid_encoder_tokens)]
plt.figure(figsize=(14, 6))
plt.imshow(attention_weights, cmap='viridis')
plt.colorbar(label='Attention权重(值越大关注越强)')
plt.xticks(range(len(valid_encoder_tokens)), valid_encoder_tokens, rotation=90, fontsize=10)
plt.yticks(range(len(valid_decoder_tokens)), valid_decoder_tokens, fontsize=12)
plt.title(
f'MT5模型Encoder-Decoder Attention可视化(第{layer_idx+1}层,第{head_idx+1}个头)\n问题:{question}',
fontsize=12
)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"✅ Attention可视化图已保存至:{save_path}")
# -------------------------- 5. 主程序(任务迁移强化) --------------------------
if __name__ == "__main__":
print(f"✅ 训练集规模:{len(train_data)}条,测试集规模:{len(test_data)}条")
# 加载模型和分词器
print("\n正在加载MT5模型和分词器...")
tokenizer = MT5TokenizerFast.from_pretrained(MODEL_NAME)
model = MT5ForConditionalGeneration.from_pretrained(MODEL_NAME).to(device)
# 确保特殊token配置正确
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
if tokenizer.sep_token is None:
tokenizer.sep_token = tokenizer.eos_token
print("✅ 模型加载完成(已适配MT5)")
# 模型结构优化:解冻Encoder最后3层,增强任务迁移能力
for name, param in model.encoder.named_parameters():
if "layer_9" in name or "layer_10" in name or "layer_11" in name:
param.requires_grad = True
print(f"✅ 解冻Encoder层:{name}")
else:
param.requires_grad = False
# 创建数据加载器
train_dataset = QADataset(train_data, tokenizer, MAX_INPUT_LEN, MAX_OUTPUT_LEN)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
print(f"✅ 数据加载完成:训练集{len(train_loader)}个batch")
# 优化器:使用低学习率+权重衰减
optimizer = optim.AdamW(
model.parameters(),
lr=LEARNING_RATE,
weight_decay=2e-4 # 更强的权重衰减,防止过拟合
)
# 训练模型(任务迁移)
print("\n" + "="*60)
print("开始训练MT5中文问答模型(任务范式迁移版)")
print("="*60)
best_exact_acc = 0.0
best_partial_acc = 0.0
for epoch in range(EPOCHS):
train_loss = train_epoch(model, train_loader, optimizer, device, GRADIENT_ACCUMULATION_STEPS)
# 每4轮测试一次
if (epoch + 1) % 4 == 0:
exact_acc, partial_acc, _, _ = evaluate(model, tokenizer, device, test_data)
print(f"Epoch {epoch+1:2d}/{EPOCHS} | 训练损失: {train_loss:.4f} | 精确匹配率: {exact_acc:.4f} | 部分匹配率: {partial_acc:.4f}")
# 更新最佳准确率
if exact_acc > best_exact_acc:
best_exact_acc = exact_acc
if partial_acc > best_partial_acc:
best_partial_acc = partial_acc
else:
print(f"Epoch {epoch+1:2d}/{EPOCHS} | 训练损失: {train_loss:.4f}")
# 最终测试
print("\n" + "="*60)
print("最终测试结果")
print("="*60)
final_exact_acc, final_partial_acc, pred_answers, true_answers = evaluate(model, tokenizer, device, test_data)
for i in range(len(test_data)):
print(f"\n【样本{i+1}】")
print(f"问题:{test_data[i]['question']}")
print(f"预测答案:{pred_answers[i]}")
print(f"真实答案:{true_answers[i]}")
print(f"精确匹配:{'✅' if pred_answers[i] == true_answers[i] else '❌'}")
print(f"部分匹配:{'✅' if pred_answers[i] in true_answers[i] or true_answers[i] in pred_answers[i] else '❌'}")
print(f"\n📊 最终精确匹配率:{final_exact_acc:.2%}")
print(f"📊 最终部分匹配率:{final_partial_acc:.2%}")
print(f"🏆 最佳精确匹配率:{best_exact_acc:.2%}")
print(f"🏆 最佳部分匹配率:{best_partial_acc:.2%}")
# Attention可视化
print("\n" + "="*60)
print("开始Attention机制可视化")
print("="*60)
sample = test_data[0]
visualize_t5_attention(
model=model,
tokenizer=tokenizer,
question=sample['question'],
context=sample['context'],
device=device
)
print("\n" + "="*60)
print("✅ 任务4全流程执行完成!")
print("="*60)
最新发布





 超级会员免费看
超级会员免费看
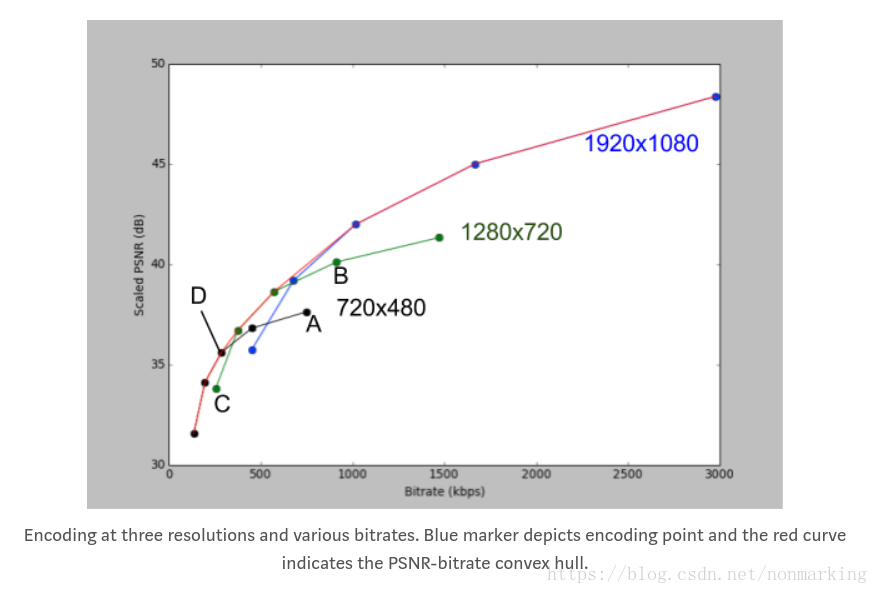
 本文介绍了Netflix在编码效率优化方面的实践,包括Per-Title Encoding根据视频特性定制码率,Per-Chunk Encoding针对每个视频块优化,以及Dynamic Optimizer的镜头分割编码。这些方法通过调整编码策略,显著降低了码率,提高了编码效率,为流媒体服务节省了带宽。
本文介绍了Netflix在编码效率优化方面的实践,包括Per-Title Encoding根据视频特性定制码率,Per-Chunk Encoding针对每个视频块优化,以及Dynamic Optimizer的镜头分割编码。这些方法通过调整编码策略,显著降低了码率,提高了编码效率,为流媒体服务节省了带宽。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2039
2039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











