




 本文详细介绍如何在三台机器上搭建Hadoop集群,包括关闭防火墙、SELinux,配置免密登录,部署JDK,配置Hadoop核心参数,以及启动和测试集群的过程。
本文详细介绍如何在三台机器上搭建Hadoop集群,包括关闭防火墙、SELinux,配置免密登录,部署JDK,配置Hadoop核心参数,以及启动和测试集群的过程。
由于资源有限,部署只用了三台机器,一台master,两台slave,三台机器之间互做免密,互做解析,主机名-和解析的名字一定要一样,基础环境比较好弄,要细心,
关闭你所准备的机器上的防火墙,selinux。swap
systemctl stop firewalld
systemctl disable firewalld
vim /etc/selinux/config
![]()
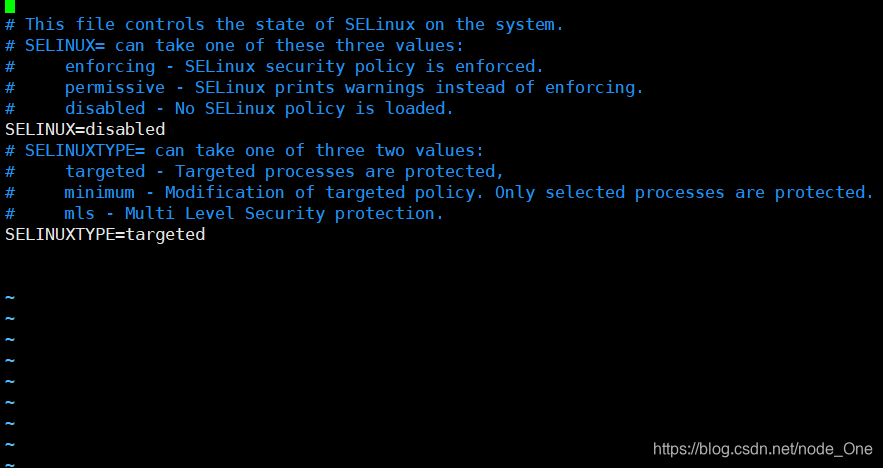
把selinux的值更改成disabled
三台机器彼此之间需要互相做免密
master上执行
ssh-keygen -t rsa 或者是 dsa
然后一路回车
然后ssh-copy-id hadoop-master
ssh-copy-id hadoop-slave1
ssh-copy-id hadoop-slave2
slave1上执行
ssh-keygen -t rsa 或者是 dsa
然后一路回车
然后ssh-copy-id hadoop-master
ssh-copy-id hadoop-slave1
ssh-copy-id hadoop-slave2
slave2上执行
ssh-keygen -t rsa 或者是 dsa
然后一路回车
然后ssh-copy-id hadoop-master
ssh-copy-id hadoop-slave1
ssh-copy-id hadoop-slave2
三台都要如此操作
hadoop跑起来需要java环境所以咱们要部署一个jdk我选的jdk是1.8,首先下载一个jdk往期里边有,请看,
简单的部署就是将jdk下载到服务器然后将他存放到规划的目录下,然后将这个具体的路径配置到。/etc/profile中
然后重新加载一下这个文件,source /etc/profile 就完事
下载自己需要的版本hadoop,我用的包是 2.8.5
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.5.tar.gz然后解压
tar -xzvf hadoop-2.8.5.tar.gz
只需要在一台机器上更改配置,完成以后scp到其他机器上
mv hadoop-2.8.5 hadoop
vim /usr/local/src/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop_tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configurationvim /usr/local/src/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/src/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/src/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop-master:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop-master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> </property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vim /usr/local/src/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<!--指定maoreduce运行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> </property>
<!--历史服务的通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<!--历史服务的web ui地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
</configuration>
[root@hadoop-master ~]# vim /usr/local/src/hadoop/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/src/hadoop/hadoop_tmp/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/usr/local/src/hadoop/hadoop_tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
![]()
更改slaves 在里边写上自己的slave

配置hadoop-env.sh,指定JAVA_HOME

更改yarm-env.sh

配置mapred-env.sh,指定JAVA_HOME
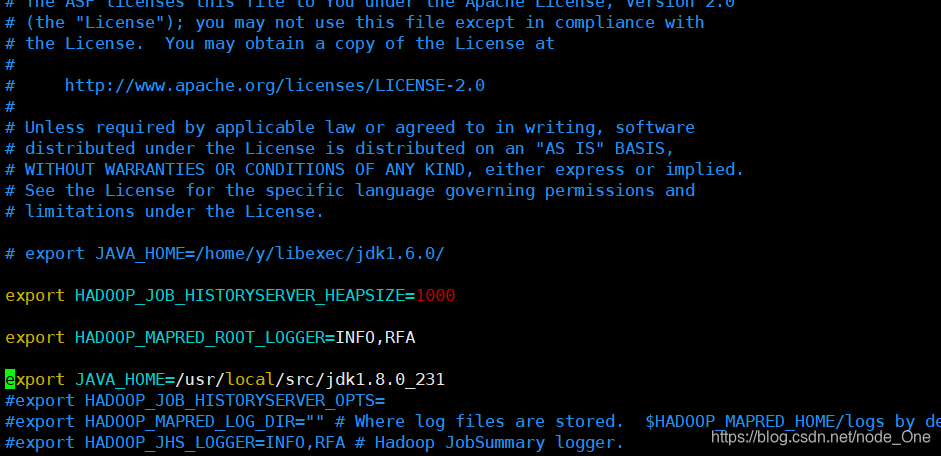
然后通过scp命令将这个安装包分发到其他的几台机器上
![]()
![]()
然后启动集群测试集群
如果是第一次启动集群需要格式化namenode
![]()
hdfs namenode -format
查看是否报错,如果不报错进行下一步,不错查看自己的配置文件,防火墙,还有就是是否将,hadoop的环境变量添加到 /etc/profie
如图

#hadoop
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin


启动这两个,可以都在一个master上执行,完成以后
访问自己定义的webip:50070
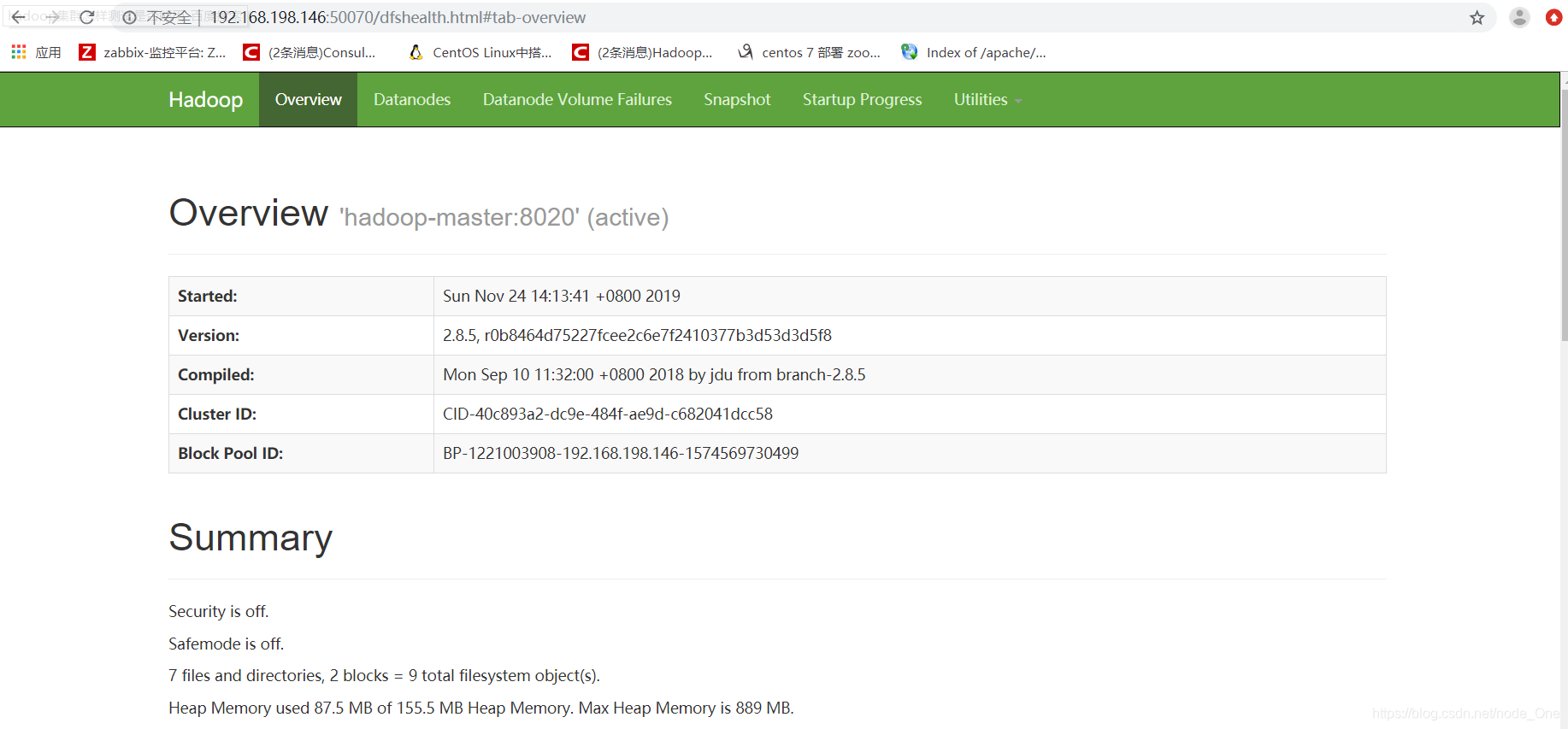
成功以后就是这样的,如果显示不全或者是没有这个端口可以查看一下日志和端口,或者是配置文件,是否写错,如有更好欢迎交流

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









