






1. A/B测试流程
A/B测试类似于高中做的生物实验,遵循单变量原则,用户分组时使用同一个分组方案,保证用户群体间无差异(新老用户/特殊偏好用户),进行实验时保证在相同的时间维度上观测,最后根据假设检验判断试验结果,判断哪些版本较原版本有统计意义上的差异,并根据p值选择最好的版本。
一个完整的A/B测试包含如下部分:
1、分析业务现状,确定最高优先级优化点,作出假设,提出优化建设;
2、根据业务确定衡量版本优劣的主要观测指标,设置辅助指标评估其他影响;
3、设计优化版本的原型并开发;
4、确认测试进行的时长;
5、确定每个版本的分流方案和分流的细节;
6、收集实验数据,进行有效性和效果判断;
7、得出结论:①确定发布新版本;②调整分流比例继续测试;③优化迭代方案重新开发,回到步骤1。
注意点:
1. 测试时长:测试的时长不宜过短,否则参与试验的用户几乎都是产品的高频用户或者因为用户的猎奇心理短时间内表现好。
2. 分流(或者说抽样):应该保证同时性、同质性、唯一性、均匀性。
①同时性:分流应该是同时的,测试的进行也应该是同时的。
②同质性:也可以说是相似性,是要求分出的用户群,在各维度的特征都相似。可以基于用户的设备特征(例如手机机型、操作系统版本号、手机语言等)和用户的其他标签(例如性别、年龄、新老用户、会员等级等)进行分群,每一个A/B测试都可以选定特定的用户群进行试验。
思考:如何判断是不是真的同质?可以采用AAB测试。抽出两份流量进行A版本的测试,进行AA测试,并分别与B版本进行AB测试。通过考察A1和A2组是否存在显著性差异,就可以确定试验的分流是否同质了。
③唯一性:即要求用户不被重复计入测试,互斥,用户只能进入其中一个实验。
④均匀性:要求各组流量是均匀的。Hash算法。现在一般由专用的A/B测试工具负责。也有看到一篇文章写了python实现,大体的思路是对用户id添加Salt值,对其散列,并据此算出一个0-1之间的浮点数,同设定好的阈值比大小,从而分组。有兴趣的可以看看,该作者的思路很清晰: 随机分配里的Why and How。(统计学原理上,我没有找到均匀性这一要求的依据,其实双样本的假设检验并不要求两个样本的数量相等或相近。当然从直观上是可以理解,希望分出的用户组越相近越好,包括人数的相近。)
3. A/B测试只能有两个版本么?
A/B test不是只能A方案和B方案,实际上一个测试可以包含A/B/C/D/E/……多个版本,但是要保证单变量,比如按钮的颜色赤/橙/黄/绿/青/蓝/紫,那么这七个方案是可以做A/B测试的;但如果某方案在旁边新增了另一个按钮,即便实验结果产生了显著差异,我们也无法判断这种差异的成因究竟是谁。
4. 同一段时间内可以做不同的A/B测试么?
比如一个test抽取总体20%的流量做按钮颜色的实验,另一个test也抽取总体20%的流量做布局样式的实验。是否可行?
可行的。但要求多个方案并行测试,同层互斥。如果从总体里,先后两次随机抽取20%流量,则很有可能会有重叠的用户,既无法满足控制单变量,又影响了用户的使用体验。
- 同层指的是在同一流量层中创建实验,在此层中创建的实验共享此层中的100%流量。
- 互斥指的是在此层中,一个设备有且只能分配到此层多个实验中的某一个实验。
2. A/B测试的原理
A/B测试的原理就是假设检验

1.给出零假设和备择假设:
零假设和备择假设是参数空间的真子集,且不能相交。
常把没有把握不能轻易肯定的命题作为备择假设 H1 ,而把没有充分理由不能轻易否定的命题作为零假设 H0 。
或者说我们将希望通过实验结果推翻的假设记为零假设H0。
2.根据备择假设确定检验方向:
备择假设含≠则为双尾;含<或>则为单尾,含<为左尾,含>为右尾。
3.判断抽样分布类型:
主要判断抽样分布是否近似正态分布
4.确定检验类型及检验统计量:
在判断用什么检验的时候,首要考虑的条件是样本量,其次是总体服从的分布。
转化率指标检验统计量公式
Pa和Pb分别代表两组(ab组)的样本比例,Na和Nb分别代表两组的样本数量。以下是z检验统计量,只适用于大样本,或者方差已知的数据(实际案例都不知道方差)
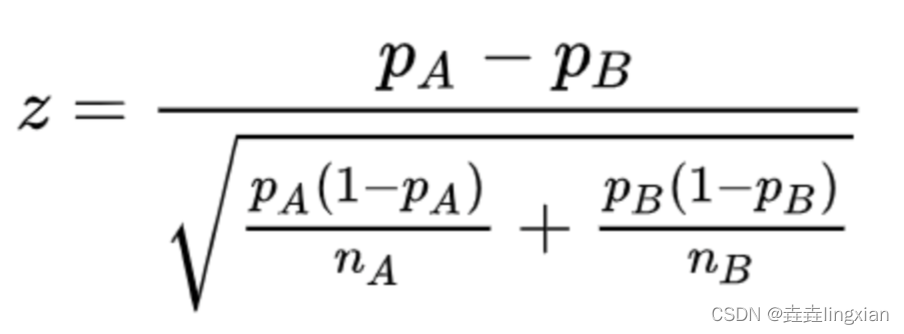
数值型指标检验统计量公式
以下是z检验统计量,只适用于大样本,或者方差已知的数据(实际案例都不知道方差)

5.给定显著性水平α:
α常取0.1、0.05、0.01,后文会再谈到显著性水平与两类错误。
P值(P value)是用于判定假设检验结果的一个参数,指的是当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。p值是根据实际统计量计算出的显著性水平。
如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。
小概率原理是指一个事件的发生概率很小,那么它在一次试验中是几乎不可能发生的,但在多次重复试验中是必然发生的。统计学上,把小概率事件在一次实验中看成是实际不可能发生的事件,一般认为等于或小于0.05或0.01的概率为小概率。
3. A/B测试最小样本量
-
ABtest实验计算样本量基于大数定律和中心极限定理。
-
大数定律:实验条件不变,随机实验重复多次,随机事件的频率可以近似为随机事件概率。
-
中心极限定理:对于独立同分布且具有相同期望和方差的n个随机变量,当样本量很大时,样本的均值近似服从标准正态分布N(0,1),即样本量很大时,样本能够代表整体的表现。
-
样本计算公式一般如下(每组的样本量)
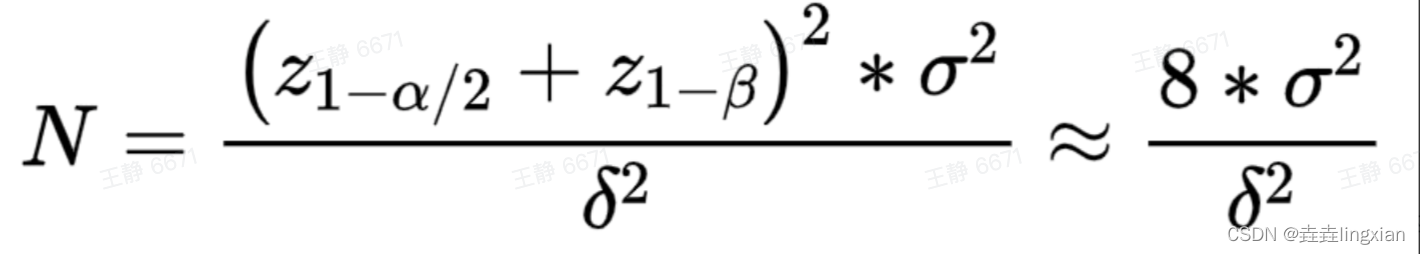
公式中,一般情况下:
- α=0.05, z1−2α=1.96,α为犯第一类错误的概率,1-α为置信水平;
β=0.2,z1−β=0.84,β为犯第二类错误的概率,1-β为功效;
δ代表实验组与对照组预期差值即提升度(如核心指标为ctr,由10%提升至15%,则δ为5%)
σ为样本标准差:
当观测指标为绝对值类指标时
- 当观测指标为比率类指标时
转化率指标最小样本量
Sample Size Calculator (Evan’s Awesome A/B Tools)
数值型指标最小样本量
Two-Sample T-Test (Evan’s Awesome A/B Tools)
4. A/B测试实例
以支付宝营销活动为例,通过广告点击率指标比较两组营销策略的广告投放效果。
数据来自于阿里云天池 - Audience Expansion Dataset
- dmp_id:营销策略编号(源数据文档未作说明,这里根据数据情况设定为1:对照组,2:营销策略一,3:营销策略二)
- user_id:支付宝用户ID
- label:用户当天是否点击活动广告(0:未点击,1:点击)
4.1 数据清洗
导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline导入数据文件,查看前5行数据
data = pd.read_csv('effect_tb.csv')
data.head()4.1.1 处理重复值
查看是否有重复值
print('数据行数:', data.shape[0])
print('去重用户数:', data.user_id.nunique())
数据行数和去重用户数不一样,说明有重复数据,查找重复数据
data[data.duplicated(keep = False)].sort_values(by = ["user_id"])删除重复数据
data1 = data1.drop_duplicates() #删除重复数据
data1[data1.duplicated(keep = False)] #检查是否还有重复数据4.1.2 处理空值
data.info(null_counts = True) #查找是否有空值
此份数据没有空值
如果数据存在空值,用以下方法处理空值
删除空值
# 删除含有空值的行
data.dropna(axis=0, inplace=True)
# 或者删除含有空值的列
data.dropna(axis=1, inplace=True)替换空值
# 用0替换空值
data.fillna(0, inplace=True)
# 或者用平均值替换空值
mean_value = data['column'].mean()
data.fillna(value=mean_value, inplace=True)4.1.3 异常值查询
通过透视表检查各属性字段是否存在不合理取值:
data.pivot_table(index = "dmp_id", columns = "label", values = "user_id",
aggfunc = "count", margins = True)
没有发现异常的枚举值
4.1.4 数据类型
data.dtypes
数据类型正常
4.2 假设检验
4.2.1 最小样本量
先计算现有点击率,对照组中点击率为0.0126,希望可以提升1%,通过最小样本量计算公式得出最小样本量为2,167
data[data['dmp_id'] == 1]['label'].mean()计算不同营销策略下的样本量
data['dmp_id'].value_counts()
营销策略一对应样本量41w,营销策略二对应样本量31w,远超过最小样本量,而且远超过30,是大样本,可以用转化率指标的z检验公式计算检验统计量和p值
# 保存清洗好的数据备用
data.to_csv('data/output.csv', index = False)4.2.2 假设检验
计算不同组的点击率
print("对 照 组: " ,data[data['dmp_id'] == 1]['label'].mean())
print("营销策略一: " ,data[data['dmp_id'] == 2]['label'].mean())
print("营销策略二: " ,data[data['dmp_id'] == 3]['label'].mean())
可以看到策略一提升0.2个百分点,策略二提升1.3个百分点,只有策略二满足了前面我们对点击率提升最小值的要求。
接下来需要进行假设检验,看策略二点击率的提升是否显著。
a. 原假设和备择假设
记对照组点击率为p1,策略二点击率为p2,则:
原假设 H0: p1 ≥ p2
备择假设 H1: p1 < p2
b. 分布类型、检验类型和显著性水平
样本服从二点分布,独立双样本,样本大小n>30,总体均值和标准差未知,所以采用Z检验。显著性水平α取0.05。所以用如下公式
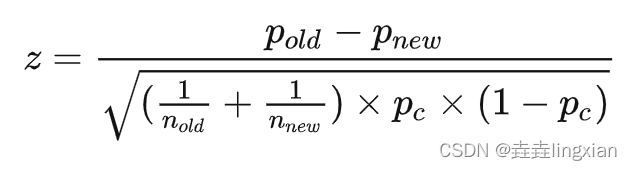
4.2.2.1 公式计算
# 用户数
n_old = len(data[data.dmp_id == 1]) # 对照组
n_new = len(data[data.dmp_id == 3]) # 策略二
# 点击数
c_old = len(data[data.dmp_id ==1][data.label == 1])
c_new = len(data[data.dmp_id ==3][data.label == 1])
# 计算点击率
r_old = c_old / n_old
r_new = c_new / n_new
# 总和点击率
r = (c_old + c_new) / (n_old + n_new)
print("总和点击率:", r)计算检验统计量z值
z = (r_old - r_new) / np.sqrt(r * (1 - r)*(1/n_old + 1/n_new))
print("检验统计量z:", z)检验统计量z: -59.44164223047762
# 查α=0.05对应的z分位数
from scipy.stats import norm
z_alpha = norm.ppf(0.05)
z_alphaz_alpha = -1.64, 检验统计量z = -59.44,该检验为左侧单尾检验,拒绝域为{z<z_alpha}。
所以我们可以得出结论:拒绝原假设,策略二点击率的提升在统计上是显著的。
4.2.2.2 Python函数计算
参考文档:statsmodels.stats.proportion.proportions_ztest - statsmodels 0.14.0
import statsmodels.stats.proportion as sp
z_score, p = sp.proportions_ztest([c_old, c_new],[n_old, n_new], alternative = "smaller")
print("检验统计量z:",z_score,",p值:", p)检验统计量z: -59.44168632985996 ,p值: 0.0
p值约等于0,p < α,与方法一结论相同,拒绝原假设。
作为补充,我们再检验下策略一的点击率提升是否显著。
# 策略一检验
z_score, p = sp.proportions_ztest([c_old, len(data[data.dmp_id ==2][data.label == 1])],[n_old, len(data[data.dmp_id == 2])], alternative = "smaller")
print("检验统计量z:",z_score,",p值:", p)检验统计量z: -14.165873564308429 ,p值: 7.450121742737582e-46
p值约等于7.45e-46,p < α,但因为前面我们设置了对点击率提升的最小值要求,这里仍只选择第二组策略进行推广。
结论:综上所述,两种营销策略中,策略二对广告点击率有显著提升效果,且相较于对照组点击率提升了近一倍,因而在两组营销策略中应选择第二组进行推广。

















 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









