






在深度学习的世界里,模型微调是一个常见的任务。我们经常需要在预训练模型的基础上进行微调,以适应特定的任务。然而,随着模型规模的不断增大,微调的计算成本和存储需求也在不断增加。今天,我们要聊聊一种新颖的技术——LoRA-GA(Low-Rank Adaptation with Gradient Approximation),它不仅能有效降低计算成本,还能保持甚至提升模型性能。
什么是 LoRA-GA?
LoRA-GA 是一种结合了低秩适配(LoRA)和梯度近似(GA)的技术。它的核心思想是通过引入低秩矩阵来减少需要更新的参数数量,从而降低计算和存储成本。同时,LoRA-GA 通过梯度近似技术确保低秩矩阵的更新方向与全参数矩阵的更新方向尽可能一致,从而提高模型的适应性和训练效率。
为什么需要 LoRA-GA?
LoRA往往只是显存不足的无奈之选,因为一般情况下全量微调的效果都会优于LoRA,所以如果算力足够并且要追求效果最佳时,请优先选择全量微调。这也是LoRA-GA的假设之一,因为它的改进方向就是向全量微调对齐。使用LoRA的另一个场景是有大量的微型定制化需求,我们要存下非常多的微调结果,此时使用LoRA能减少储存成本。
想象一下,你正在微调一个庞大的预训练模型,比如 BERT 或 GPT-3。每次更新都需要调整数百万甚至数十亿个参数,这不仅耗时耗力,还需要大量的计算资源。LoRA-GA 通过引入低秩矩阵,只需更新少量参数,就能达到类似的效果。这就像是用一把小锤子敲打大石头,既省力又高效。如下图所示(来自https://arxiv.org/abs/2407.05000):
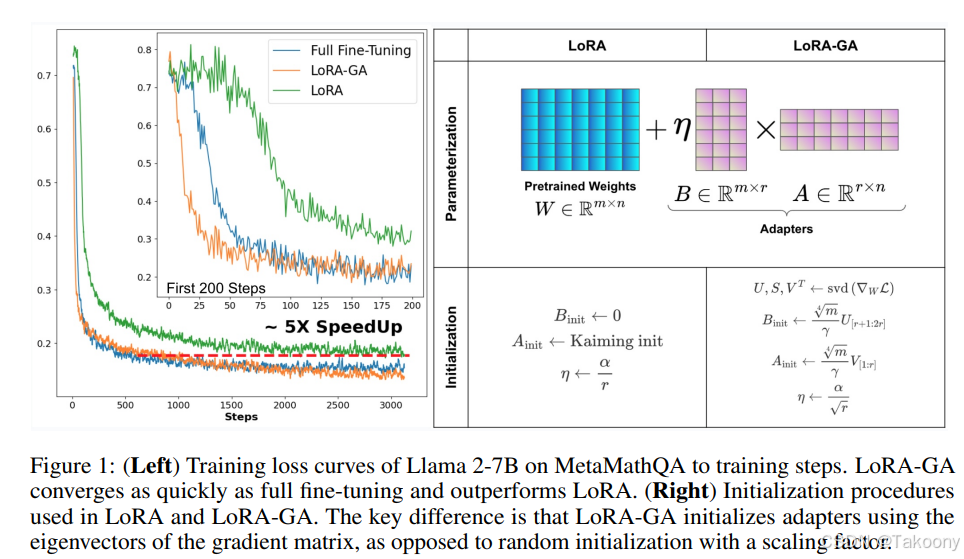
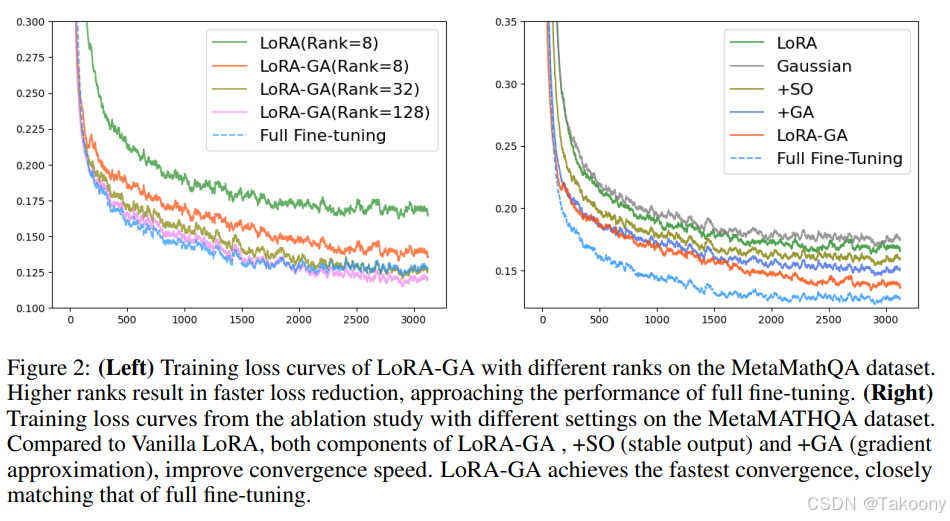
LoRA-GA 的工作原理
LoRA-GA 的工作原理可以分为以下几个步骤:
- 低秩分解:将预训练模型的权重矩阵分解为两个低秩矩阵的乘积。
- 梯度近似:通过奇异值分解(SVD)初始化低秩矩阵,确保低秩矩阵的更新方向与全参数矩阵的更新方向尽可能一致。SVD将一个矩阵分解为三个矩阵的乘积:左奇异矩阵、对角矩阵和右奇异矩阵。SVD 的一个重要特性是它能够提取矩阵的主要方向(奇异向量),这些方向与原始矩阵的方向一致;左奇异向量(矩阵 (U) 的列向量)表示矩阵 (A) 在行空间上的主要方向。右奇异向量(矩阵 (V) 的列向量)表示矩阵 (A) 在列空间上的主要方向。奇异值(矩阵 (Sigma) 的对角线元素)表示这些方向的重要性,按降序排列。
- 参数更新:在训练过程中,只更新低秩矩阵的参数,而保持原始权重矩阵不变。
实例演示
让我们通过一个简单的实例来看看 LoRA-GA 的实际应用。
首先,我们需要定义一个预训练模型和 LoRA-GA 模型:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from torch.utils.data import DataLoader, TensorDataset
# 生成示例数据
X, y = make_classification(n_samples=10000, n_features=768, n_informative=10, n_classes=10, n_clusters_per_class=1, random_state=42)
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
# 创建数据加载器
dataset = TensorDataset(X, y)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
class PretrainedModel(nn.Module):
def __init__(self):
super(PretrainedModel, self).__init__()
self.fc = nn.Linear(768, 10) # 示例权重矩阵
def forward(self, x):
return self.fc(x)
class LoRA(nn.Module):
def __init__(self, model, rank=4, alpha=1.0):
super(LoRA, self).__init__()
self.model = model
self.rank = rank
self.alpha = alpha
self.lora_A = nn.Parameter(torch.randn(768, rank))
self.lora_B = nn.Parameter(torch.randn(rank, 10))
def forward(self, x):
original_output = self.model(x)
lora_output = torch.matmul(x, self.lora_A)
lora_output = torch.matmul(lora_output, self.lora_B)
return original_output + self.alpha * lora_output
class LoRAGA(nn.Module):
def __init__(self, model, rank=4, alpha=1.0):
super(LoRAGA, self).__init__()
self.model = model
self.rank = rank
self.alpha = alpha
self.lora_A = nn.Parameter(torch.randn(768, rank))
self.lora_B = nn.Parameter(torch.randn(rank, 10))
self.initialize_lora()
def initialize_lora(self):
# 使用 SVD 初始化 A 和 B
with torch.no_grad():
W = self.model.fc.weight.data
U, S, V = torch.svd(W.T)
self.lora_A.data = U[:, :self.rank] * torch.sqrt(S[:self.rank])
self.lora_B.data = torch.sqrt(S[:self.rank]).unsqueeze(1) * V[:self.rank, :]
def forward(self, x):
original_output = self.model(x)
# print(x.shape, self.lora_A.shape, self.lora_B.shape)
lora_output = torch.matmul(x, self.lora_A)
lora_output = torch.matmul(lora_output, self.lora_B)
return original_output + self.alpha * lora_output
# 初始化模型
pretrained_model = PretrainedModel()
lora_model = LoRA(pretrained_model, rank=4, alpha=0.5)
lora_ga_model = LoRAGA(pretrained_model, rank=4, alpha=0.5)
def train_model(model, data_loader, epochs=100):
optimizer = optim.Adam(model.parameters(), lr=1e-5)
criterion = nn.CrossEntropyLoss()
model.train()
loss_values = []
for epoch in range(epochs):
total_loss = 0
for inputs, labels in data_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
loss_values.append(avg_loss)
print(f"Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}")
return loss_values
# 训练 LoRA 模型
print("Training LoRA Model")
%time lora_loss_values = train_model(lora_model, data_loader)
# 训练 LoRA-GA 模型
print("Training LoRA-GA Model")
%time lora_ga_loss_values = train_model(lora_ga_model, data_loader)
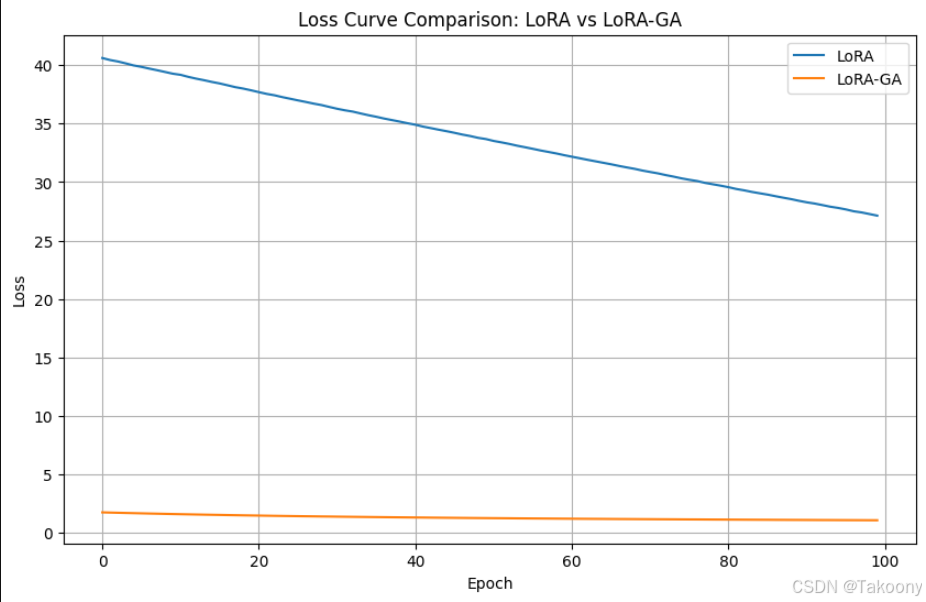
# 绘制损失函数曲线
plt.figure(figsize=(10, 6))
plt.plot(lora_loss_values, label='LoRA')
plt.plot(lora_ga_loss_values, label='LoRA-GA')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve Comparison: LoRA vs LoRA-GA')
plt.legend()
plt.grid(True)
plt.show()
def evaluate_model(model, data_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in data_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
return accuracy
# 评估模型
lora_accuracy = evaluate_model(lora_model, data_loader)
lora_ga_accuracy = evaluate_model(lora_ga_model, data_loader)
print(f"LoRA Model Accuracy: {lora_accuracy:.4f}")
print(f"LoRA-GA Model Accuracy: {lora_ga_accuracy:.4f}")
输出:
LoRA Model Accuracy: 0.1414
LoRA-GA Model Accuracy: 0.6453
结果分析
通过上述代码,我们可以看到 LoRA 和 LoRA-GA 在相同训练任务上的损失值和准确率。通常情况下,LoRA-GA 模型由于使用了梯度近似技术,能够更快地收敛,并且在相同的训练时间内达到更低的损失值和更高的准确率。
总结
LoRA-GA 通过结合低秩适配和梯度近似技术,有效地提高了模型微调的效率和性能。与原始的 LoRA 技术相比,LoRA-GA 在减少计算和存储成本的同时,能够更快地收敛,并且在相同的训练时间内达到更低的损失值和更高的准确率。通过这种方式,LoRA-GA 提供了一种高效且实用的模型微调方法,特别适用于大规模预训练模型的微调和资源受限的环境。
该算法仅仅是靠初始化逼近全量微调才取得效果,如果能做到每一步梯度更新都能逼近全量微调,效果会不会更好呢?
LoRA-Pro技术:https://arxiv.org/pdf/2407.18242
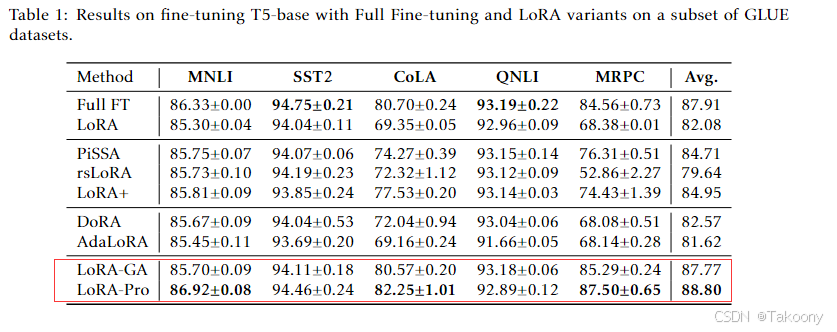
LoRA-Pro通过修改优化器的更新规则来使得LoRA的每一步更新都尽量跟全量微调对齐

















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









